Prefect Part 2 - AWS
안녕하세요. 오태호입니다.
이 글에서는 Prefect를 AWS(Amazon Web Services)의 S3(Simple Storage Service), ECR(Elastic Container Registry), EKS(Elastic Kubernetes Service)와 함께 사용하는 방법에 대해서 살펴보도록 하겠습니다.
이 글을 읽기 전에 Prefect와 Kubernetes를 먼저 읽는 것을 권장드립니다.
이 글을 이해하기 위해서는 Docker, AWS, S3, ECR, EKS에 대한 기본 지식이 필요합니다.
이 글은 Ubuntu 18.04, Python 3.6.7, Prefect 0.15.4, Scikit-learn 0.24.2, Docker 20.10.7, awscli 1.20.53, kubectl 1.21.2, eksctl 0.69.0을 기준으로 작성하였습니다.
AWS
AWS Account를 만들고 ~/.aws를 적절하게 설정합니다.
Prefect Server
Prefect Server를 실행합니다.
prefect_aws.tgz
이 글에서 사용한 Code는 모두 prefect_aws.tgz에서 살펴볼 수 있습니다. 다음과 같이 prefect_aws.tgz을 ~/Downloads에 Download한 후 ~/work/prefect_aws에 압축을 풉니다.
$ mkdir -p ~/work
$ cd ~/work
$ tar -xzf ~/Downloads/prefect_aws.tgz
$ cd prefect_aws
$ ls
code_11 code_12 code_13 code_14 code_15 Dockerfile
$
Local Agent
다음과 같이 prefect_aws_local_label Label의 Local Agent를 실행합니다. 이 글에서 실행하는 모든 Flow는 이 Local Agent를 사용합니다.
$ virtualenv -p python3 ~/prefect_aws_local_agent_env
$ source ~/prefect_aws_local_agent_env/bin/activate
$ pip install prefect==0.15.4 scikit-learn==0.24.2 s3path==0.3.2 awscli==1.20.53
$ cd ~/work/prefect_aws
$ prefect agent local start --api http://localhost:4200 --label prefect_aws_local_label
Code 11
code_11/flow.py
from prefect import Flow, Client, Parameter, unmapped, flatten
from prefect.executors import LocalDaskExecutor
from prefect.schedules import CronSchedule
from prefect.storage import S3
from .tasks import (
download_dataset, preprocess_dataset, evaluate_model, cleanup_file,
train_model,
)
PROJECT_NAME = 'prefect_aws_project'
with Flow('code_11_flow', executor=LocalDaskExecutor(),
schedule=CronSchedule('*/1 * * * *'),
storage=S3(bucket='ohhara-prefect-storage')) as flow:
alphas = Parameter('alphas', default=[1.0, 0.1, 0.01, 0.001, 0.0001, 0.00001]);
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filenames = train_model.map(
unmapped(train_test_dataset_filename[0]), alphas)
eval_model_filenames = evaluate_model.map(
model_filenames, unmapped(train_test_dataset_filename[1]))
cleanup_files = cleanup_file.map(
flatten([[dataset_filename], model_filenames, train_test_dataset_filename]))
cleanup_files.set_upstream(eval_model_filenames)
Client().create_project(project_name=PROJECT_NAME)
flow.register(project_name=PROJECT_NAME, labels=['prefect_aws_local_label'],
set_schedule_active=False)
code_11/tasks.py
import time
import random
from io import StringIO, BytesIO
from s3path import S3Path
import numpy as np
from joblib import dump, load
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
import prefect
from prefect import task
S3_DATA = 's3://ohhara-prefect-data'
@task
def download_dataset():
dt = prefect.context.get('scheduled_start_time')
seed = int(dt.timestamp())
dataset_filename = f'{S3_DATA}/dataset_{dt.format("YYYYMMDDHHmmss")}.csv'
random_state = np.random.RandomState(seed=seed)
a, b = random_state.uniform(-10, 10, 2)
x_data = random_state.uniform(-10, 10, size=100)
y_data = a * x_data + b + random_state.uniform(-10, 10, size=100)
dataset = np.column_stack((x_data, y_data))
sio = StringIO()
np.savetxt(sio, dataset, delimiter=',')
S3Path.from_uri(dataset_filename).write_text(sio.getvalue())
time.sleep(5)
return dataset_filename
@task
def preprocess_dataset(dataset_filename):
train_dataset_filename = f'{S3_DATA}/train_{S3Path.from_uri(dataset_filename).name}'
test_dataset_filename = f'{S3_DATA}/test_{S3Path.from_uri(dataset_filename).name}'
dataset = np.genfromtxt(
StringIO(S3Path.from_uri(dataset_filename).read_text()), delimiter=',')
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, 0], dataset[:, 1], random_state=23)
train_dataset = np.column_stack((x_train, y_train))
test_dataset = np.column_stack((x_test, y_test))
sio = StringIO()
np.savetxt(sio, train_dataset, delimiter=',')
S3Path.from_uri(train_dataset_filename).write_text(sio.getvalue())
sio = StringIO()
np.savetxt(sio, test_dataset, delimiter=',')
S3Path.from_uri(test_dataset_filename).write_text(sio.getvalue())
time.sleep(5)
return train_dataset_filename, test_dataset_filename
@task
def train_model(train_dataset_filename, alpha):
model_filename = S3Path.from_uri(
f'{S3_DATA}/model_{alpha}_{S3Path.from_uri(train_dataset_filename).name}').with_suffix('.joblib').as_uri()
dataset = np.genfromtxt(
StringIO(S3Path.from_uri(train_dataset_filename).read_text()), delimiter=',')
model = Ridge(alpha=alpha).fit(dataset[:, 0:1], dataset[:, 1])
bio = BytesIO()
dump(model, bio)
S3Path.from_uri(model_filename).write_bytes(bio.getvalue())
time.sleep(5)
return model_filename
@task
def evaluate_model(model_filename, test_dataset_filename):
eval_model_filename = S3Path.from_uri(
f'{S3_DATA}/eval_{S3Path.from_uri(model_filename).name}').with_suffix('.txt').as_uri()
bio = BytesIO(S3Path.from_uri(model_filename).read_bytes())
model = load(bio)
dataset = np.genfromtxt(
StringIO(S3Path.from_uri(test_dataset_filename).read_text()), delimiter=',')
score = model.score(dataset[:, 0:1], dataset[:, 1])
sio = StringIO()
np.savetxt(sio, [score])
S3Path.from_uri(eval_model_filename).write_text(sio.getvalue())
time.sleep(5)
return eval_model_filename
@task
def cleanup_file(filename):
S3Path.from_uri(filename).unlink()
time.sleep(5)
Code-10을 S3에서 사용하기 위해 수정합니다. 주요 변경사항은 다음과 같습니다.
flow를 생성할 때storage를S3(bucket='ohhara-prefect-storage')로 설정해서flow와 관련된 정보가 S3의ohhara-prefect-storagebucket에 저장하도록 설정합니다.- 이렇게 설정하지 않으면
~/.prefect에 저장됩니다. - 직접 이 Code를 실행시킬 때는 적절한 S3 Bucket을 직접 만들고
ohhara-prefect-storage을 직접 만든 S3 Bucket으로 변경합니다.
- 이렇게 설정하지 않으면
- Task들의 각종 실행결과를
s3://ohhara-prefect-data에 저장합니다.- 전에는 Agent의 Current Directory에 저장했었습니다.
- 직접 이 Code를 실행시킬 때는 적절한 S3 Bucket을 직접 만들고
s3://ohhara-prefect-data을 직접 만든 S3 Bucket으로 변경합니다.
- Flow는
flow.py에 저장하고 Task들은tasks.py에 저장해서 Flow와 Task를 분리합니다. - Flow를 Register할 때 set_schedule_active을
False로 설정해서 Register를 하자마자 Flow가 1분마다 실행되는 것을 Disable합니다.- Flow가 1분마다 실행되게 하고 싶으면 Prefect Server UI에서 Schedule의 Check Box를 Click해서 Enable합니다.
Flow를 다음과 같이 Register합니다. Register후에 Flow가 ohhara-prefect-storage S3 Bucket에 Upload된 것을 확인합니다.
$ source ~/prefect_aws_local_agent_env/bin/activate
$ cd ~/work/prefect_aws
$ python -m code_11.flow
[2021-10-05 01:17:45+0900] INFO - prefect.S3 | Uploading code-11-flow/2021-10-04t16-17-45-474922-00-00 to ohhara-prefect-storage
Flow URL: http://localhost:8080/default/flow/87c72f6f-09ed-41a6-bcaa-247b5da6124d
└── ID: 15fbbca7-a6a7-4a35-8aeb-fce9220f4428
└── Project: prefect_aws_project
└── Labels: ['prefect_aws_local_label']
$ aws s3 ls --recursive s3://ohhara-prefect-storage
2021-10-05 01:17:46 11258 code-11-flow/2021-10-04t16-17-45-474922-00-00
$
Prefect Server UI에서 Flows를 Click해서 확인해 보면 code_11_flow Flow가 prefect_aws_project Project에 등록되어 있으며 Schedule은 Disable되어 있습니다. 1분마다 Flow를 실행하고 싶으면 Schedule을 Click해서 Enable로 변경하면 되는데 여기서는 변경없이 Disable상태로 둡니다.
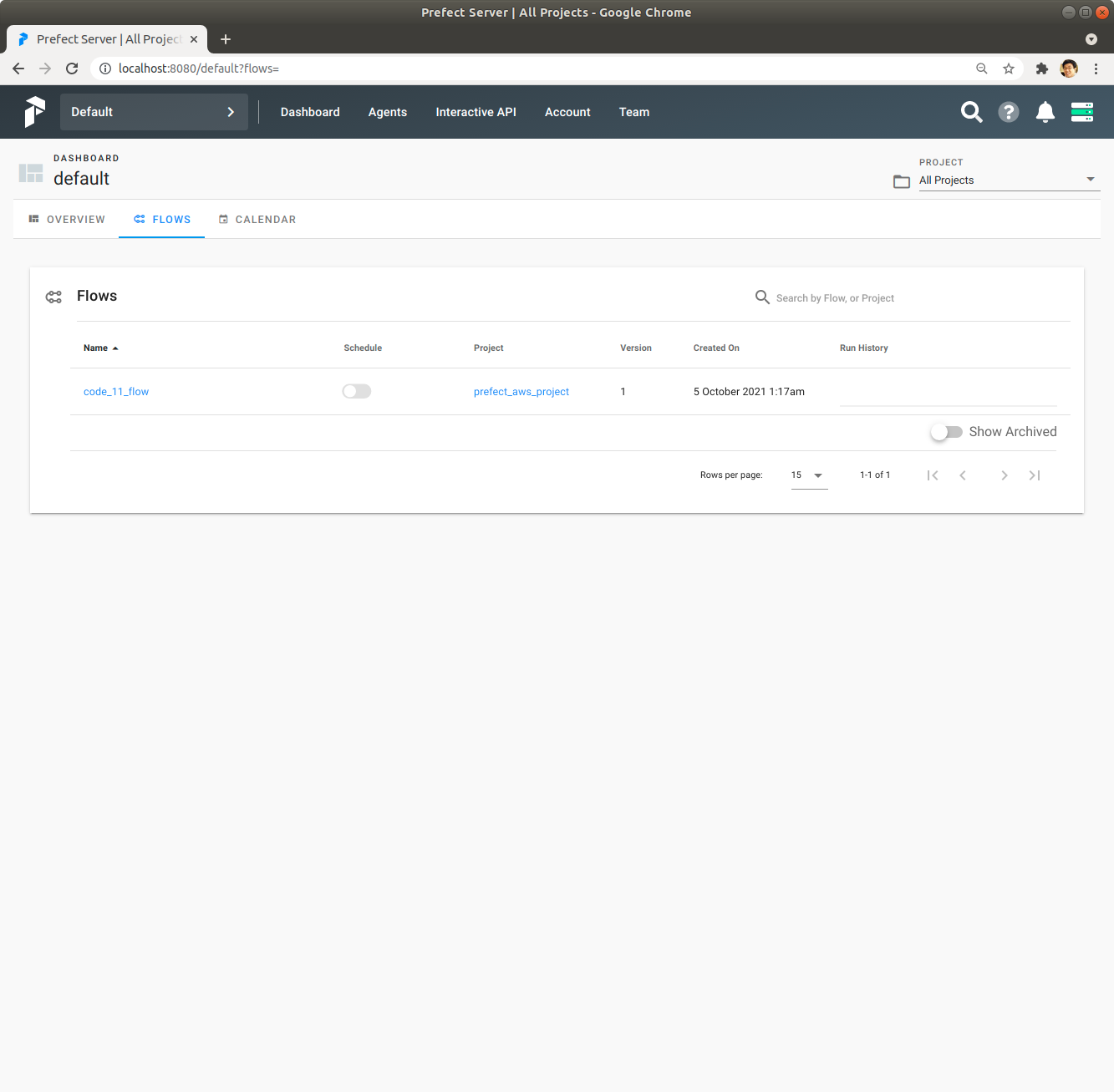
code_11_flow Flow를 Click해서 내용을 확인합니다.
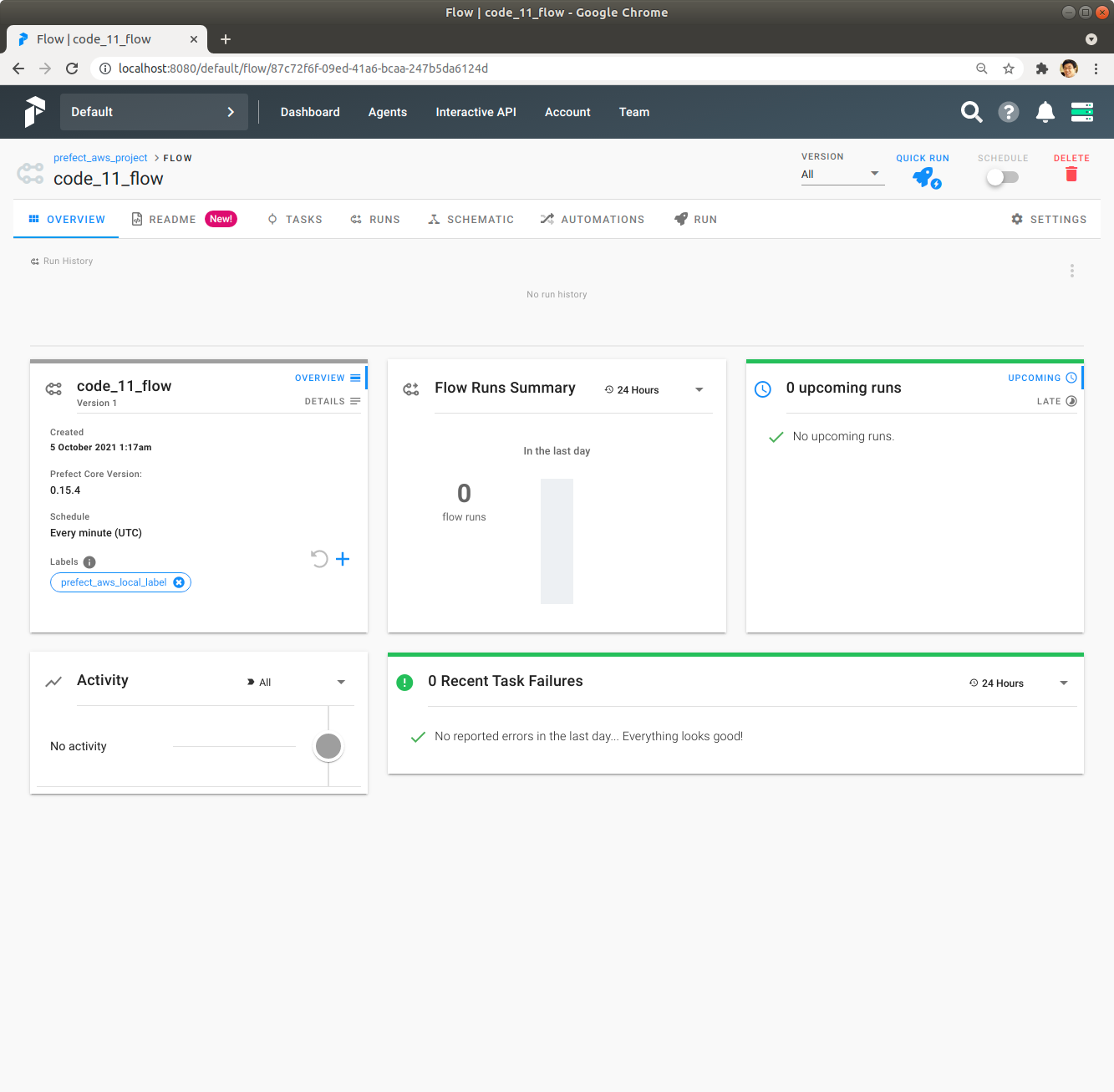
우측 상단에 있는 Quick Run을 Click하여 code_11_flow Flow를 실행합니다. 잠시 기다리면 녹색 막대가 나오면서 code_11_flow Flow의 실행이 성공적으로 완료됩니다.
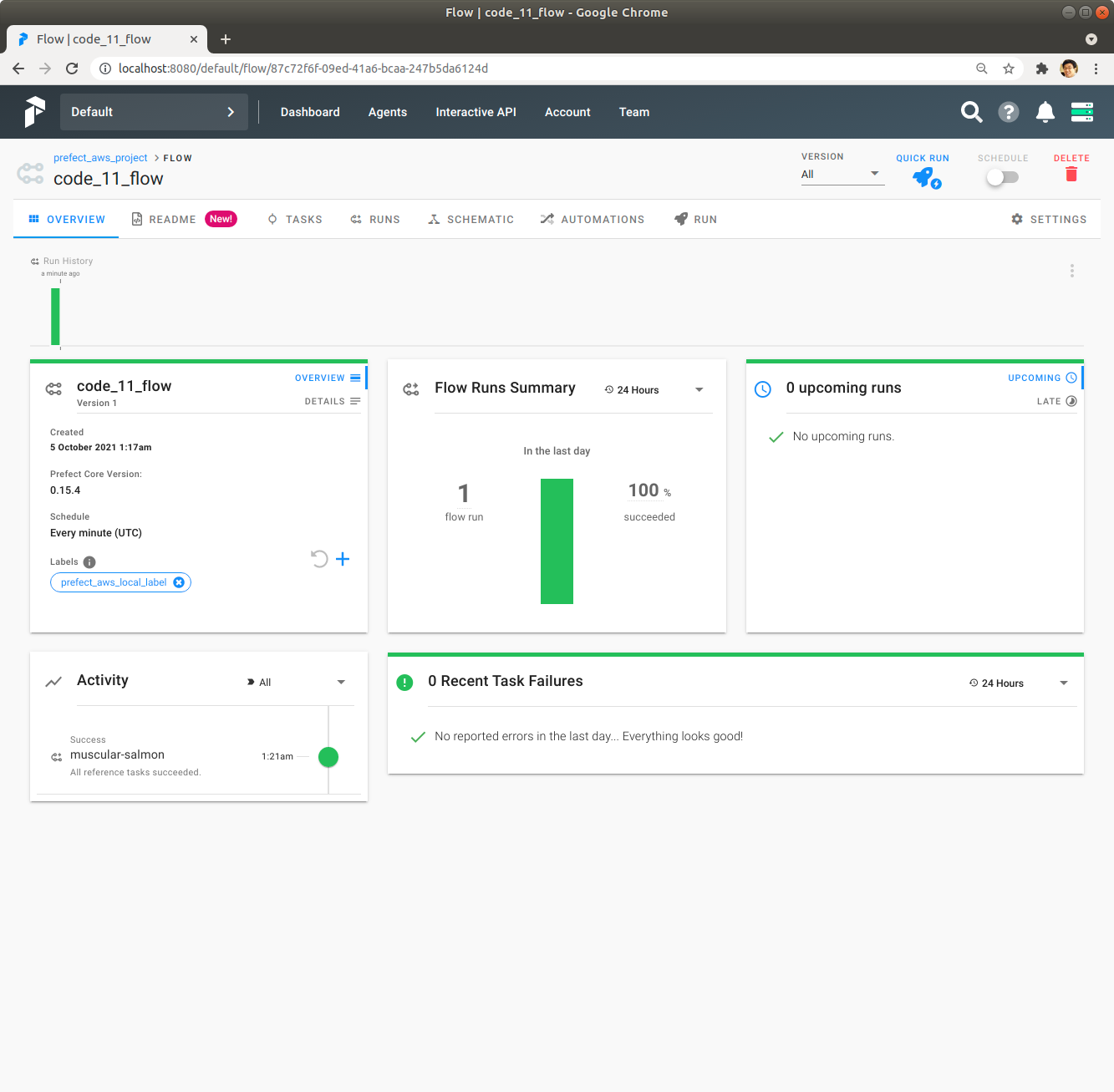
녹색 막대를 Click해서 각 Task의 실행시간 등 자세한 정보를 확인합니다.
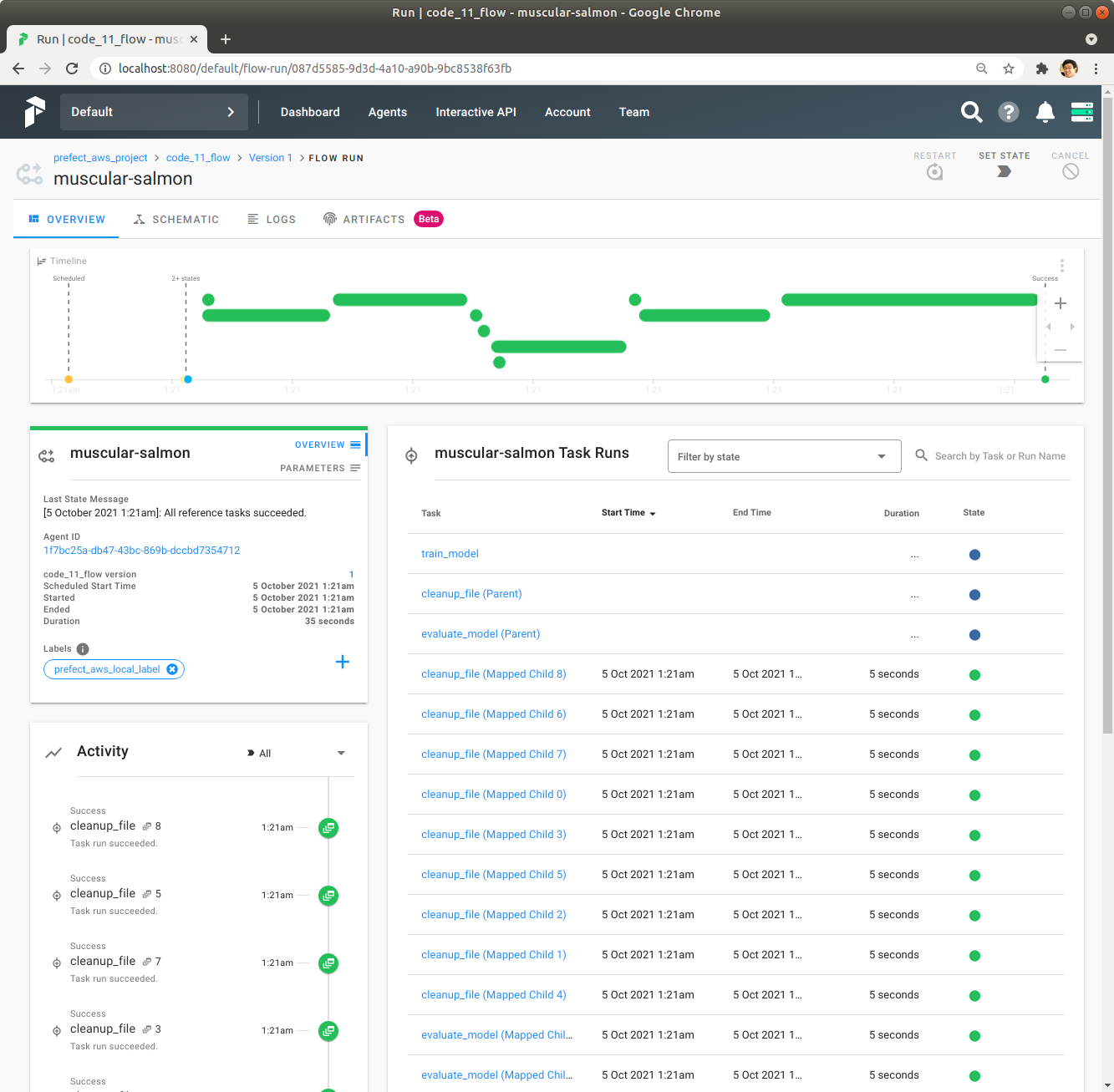
중앙에 있는 train_model을 Click해서 train_model의 Task Run의 자세한 정보를 확인합니다.
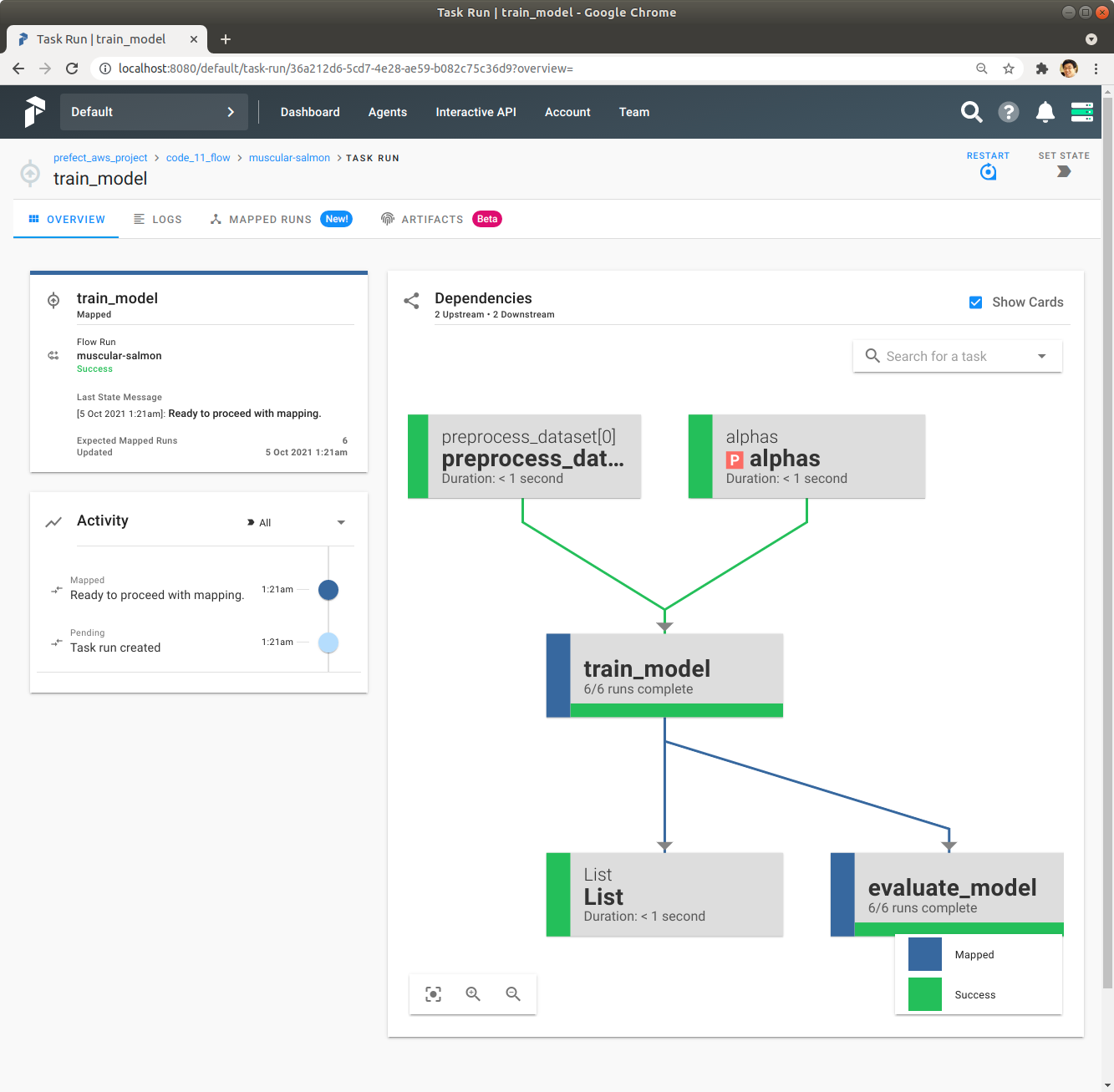
좌측 상단에 있는 Mapped Runs를 Click해서 train_model이 map을 사용해서 어떻게 여러번 동시에 실행되었는지 확인합니다.
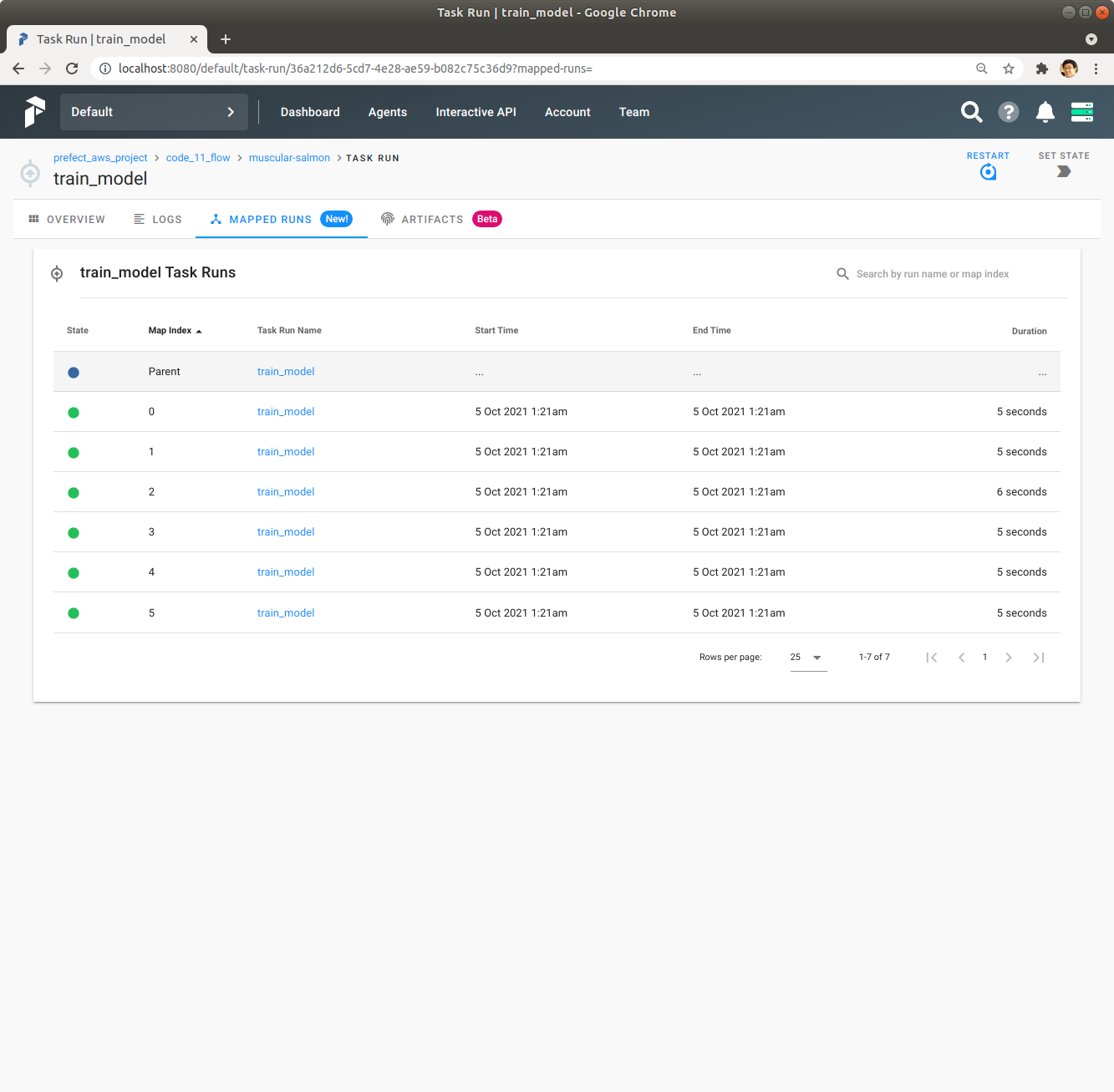
Map Index 2의 train_model을 Click해서 Task Run의 자세한 정보를 확인합니다.
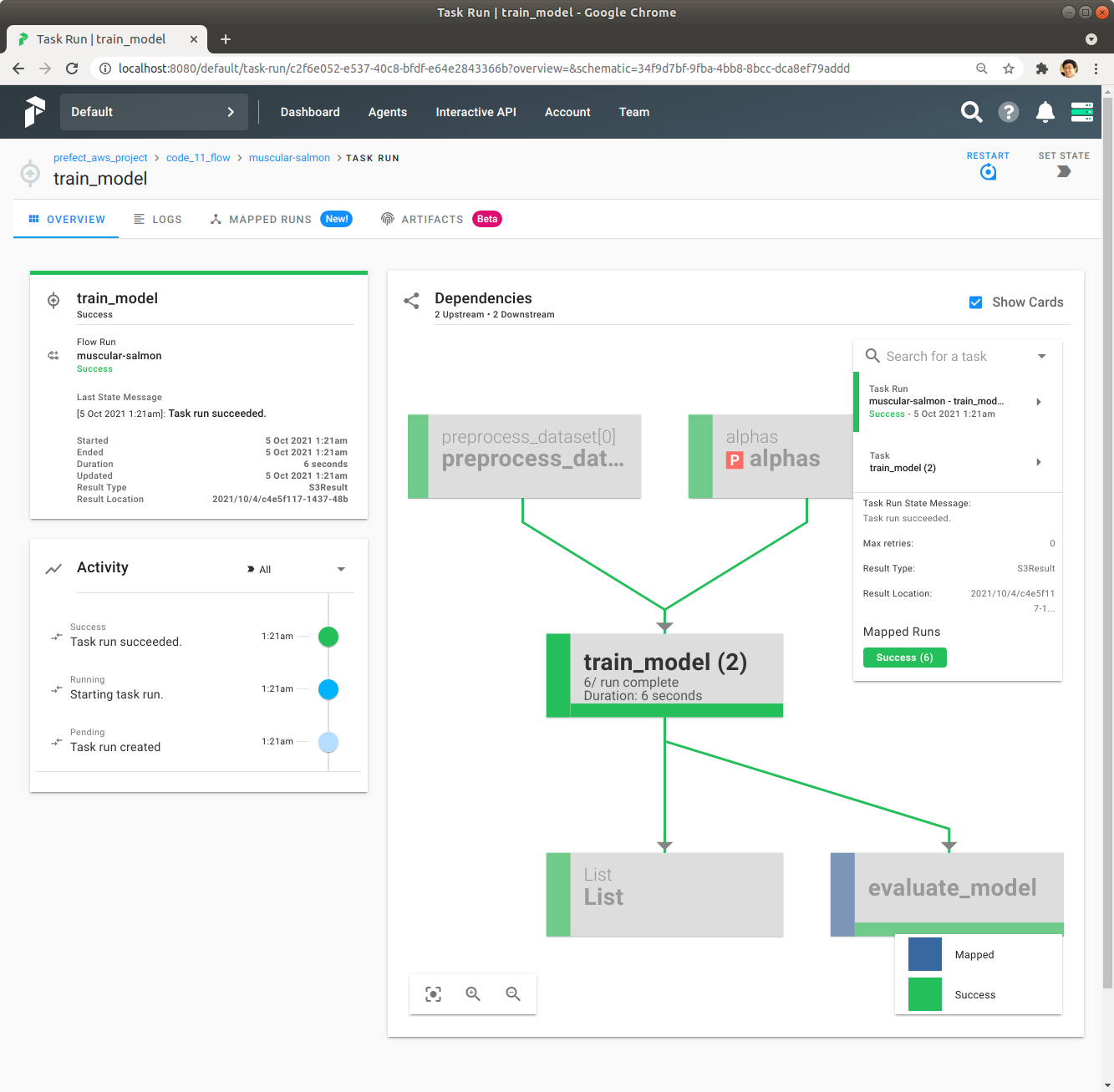
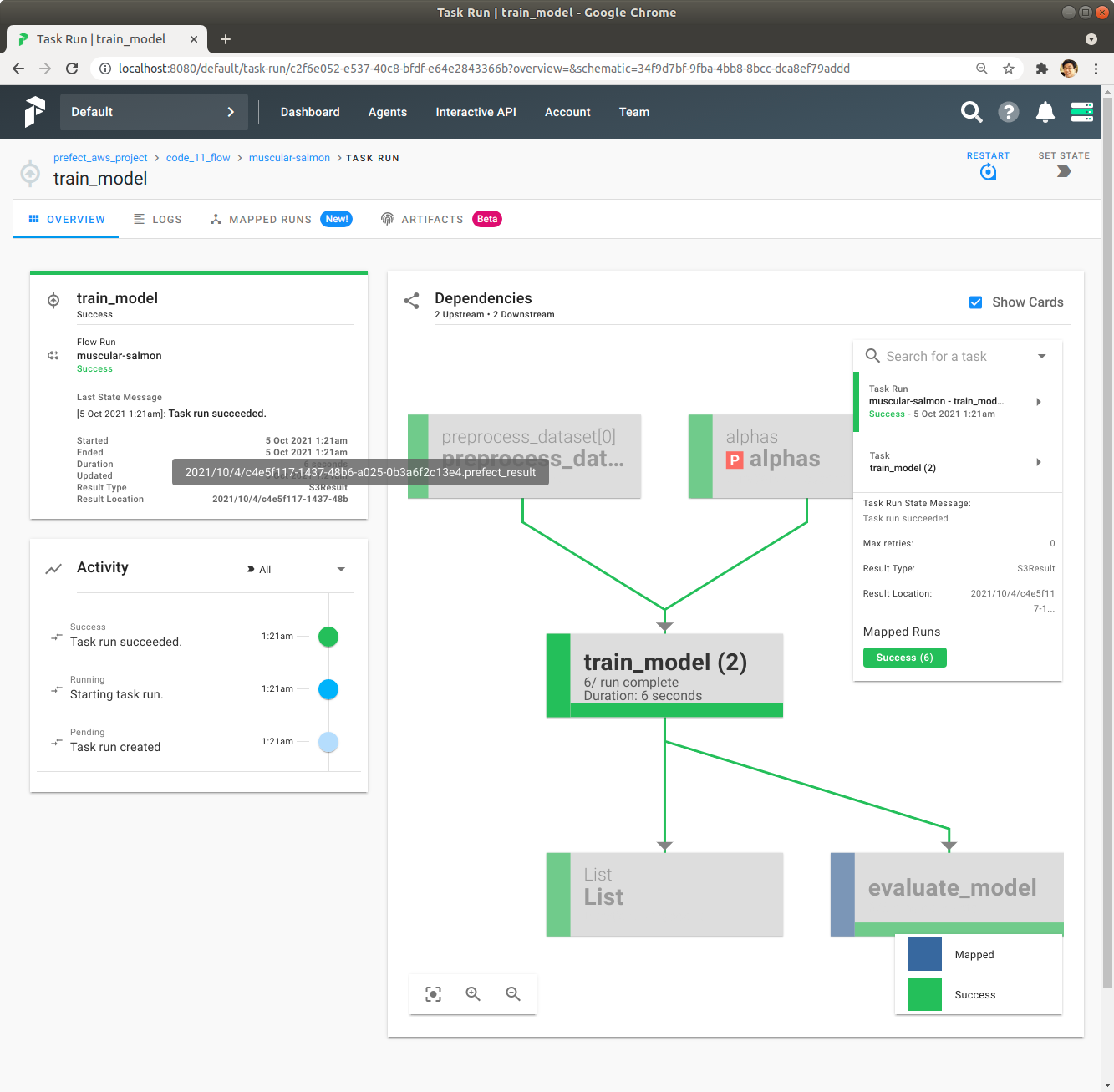
좌측의 Result Location에 Mouse를 이동해서 Result Location의 정확한 정보를 확인합니다.
Flow의 실행 결과물이 s3://ohhara-prefect-data에 잘 저장된 것을 확인합니다.
$ aws s3 ls --recursive s3://ohhara-prefect-data
2021-10-05 01:21:25 25 eval_model_0.0001_train_dataset_20211004162100.txt
2021-10-05 01:21:25 25 eval_model_0.001_train_dataset_20211004162100.txt
2021-10-05 01:21:25 25 eval_model_0.01_train_dataset_20211004162100.txt
2021-10-05 01:21:25 25 eval_model_0.1_train_dataset_20211004162100.txt
2021-10-05 01:21:25 25 eval_model_1.0_train_dataset_20211004162100.txt
2021-10-05 01:21:25 25 eval_model_1e-05_train_dataset_20211004162100.txt
$
Flow가 실행되면서 실행한 각 Task의 실행결과가 s3://ohhara-prefect-storage에 잘 저장된 것을 확인합니다.
$ aws s3 ls --recursive s3://ohhara-prefect-storage
2021-10-05 01:21:30 89 2021/10/4/03154b25-9ae4-4bd3-bed0-93cd3ce63b13.prefect_result
2021-10-05 01:21:30 87 2021/10/4/1aa684d5-8ce3-4f5e-85b3-9f57bfabe7b0.prefect_result
2021-10-05 01:21:19 69 2021/10/4/2125bb33-c715-4460-86e3-67880871cf9b.prefect_result
2021-10-05 01:21:30 87 2021/10/4/28b7cb00-29ee-434f-93e8-0a3dc6092b1f.prefect_result
2021-10-05 01:21:30 89 2021/10/4/2b89e09f-b718-41ba-9822-e2edbbe41534.prefect_result
2021-10-05 01:21:18 71 2021/10/4/3158e2c5-28f0-48da-88bf-61421d249bfe.prefect_result
2021-10-05 01:21:30 88 2021/10/4/4d00eb27-a12c-44b9-b422-4f7acc1a7760.prefect_result
2021-10-05 01:21:24 88 2021/10/4/50222e29-ebf3-456c-b278-511570ccbd08.prefect_result
2021-10-05 01:21:25 644 2021/10/4/76a5ba7d-1058-4da3-ab8d-8ec5846f6516.prefect_result
2021-10-05 01:21:18 133 2021/10/4/81df5ac6-a1d2-4693-91ec-69c080d81b9f.prefect_result
2021-10-05 01:21:24 87 2021/10/4/84486ef4-f010-406b-ac14-8de3cff59f3c.prefect_result
2021-10-05 01:21:24 85 2021/10/4/9262f8a5-aec7-4be7-8ab7-50306cbec830.prefect_result
2021-10-05 01:21:24 85 2021/10/4/b0e656d7-6674-4df6-84b0-c5537e2af274.prefect_result
2021-10-05 01:21:24 86 2021/10/4/c4e5f117-1437-48b6-a025-0b3a6f2c13e4.prefect_result
2021-10-05 01:21:12 66 2021/10/4/d08b4b64-8a7f-409b-b143-077a9b43bb93.prefect_result
2021-10-05 01:21:18 72 2021/10/4/df2bdb5a-acf0-49d2-bf74-5eed2c17cff4.prefect_result
2021-10-05 01:21:24 87 2021/10/4/f712d217-2c0a-4677-bed4-b9a3901dc9c3.prefect_result
2021-10-05 01:21:30 90 2021/10/4/ff26a51f-0b04-4d72-af3c-fcb610715ea6.prefect_result
2021-10-05 01:17:46 11258 code-11-flow/2021-10-04t16-17-45-474922-00-00
$
Prefect Server UI에서 확인했던 Result Location에 어떤 내용이 저장되어 있는지 확인합니다. train_model Task는 Train한 Model을 저장한 경로를 String으로 Return하는데, 이것이 Result Location에 저장되어 있는 것을 확인합니다.
$ python
Python 3.6.7 (default, Oct 22 2018, 11:32:17)
[GCC 8.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from prefect.engine.results import S3Result
>>> S3Result(bucket='ohhara-prefect-storage').read(location='2021/10/4/c4e5f117-1437-48b6-a025-0b3a6f2c13e4.prefect_result')
<S3Result: 's3://ohhara-prefect-data/model_0.01_train_dataset_20211004162100.joblib'>
>>>
$
Code 12
code_12/flow_train_model.py
from prefect import Flow, Client, Parameter
from prefect.executors import LocalDaskExecutor
from prefect.storage import S3
from .tasks_train_model import train_model
PROJECT_NAME = 'prefect_aws_project'
with Flow('code_12_train_model_flow', executor=LocalDaskExecutor(),
storage=S3(bucket='ohhara-prefect-storage')) as flow:
train_dataset_filename = Parameter('train_dataset_filename')
alpha = Parameter('alpha');
train_model(train_dataset_filename, alpha)
Client().create_project(project_name=PROJECT_NAME)
flow.register(
project_name=PROJECT_NAME, labels=['prefect_aws_train_model_local_label'])
code_12/flow.py
from prefect import Flow, Client, Parameter, unmapped, flatten, task
from prefect.executors import LocalDaskExecutor
from prefect.schedules import CronSchedule
from prefect.storage import S3
from prefect.tasks.prefect.flow_run import create_flow_run, get_task_run_result
from .tasks import (
download_dataset, preprocess_dataset, evaluate_model, cleanup_file,
)
PROJECT_NAME = 'prefect_aws_project'
@task
def get_train_model_flow_param(train_dataset_filename, alpha):
return { 'train_dataset_filename': train_dataset_filename, 'alpha': alpha }
def train_models(train_dataset_filename, alphas):
train_model_params = get_train_model_flow_param.map(
unmapped(train_dataset_filename), alphas)
flow_run_ids = create_flow_run.map(
flow_name=unmapped('code_12_train_model_flow'),
project_name=unmapped(PROJECT_NAME),
parameters=train_model_params)
model_filenames = get_task_run_result.map(
flow_run_id=flow_run_ids, task_slug=unmapped('train_model-1'))
return model_filenames
with Flow('code_12_flow', executor=LocalDaskExecutor(),
schedule=CronSchedule('*/1 * * * *'),
storage=S3(bucket='ohhara-prefect-storage')) as flow:
alphas = Parameter('alphas', default=[1.0, 0.1, 0.01, 0.001, 0.0001, 0.00001]);
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filenames = train_models(train_test_dataset_filename[0], alphas)
eval_model_filenames = evaluate_model.map(
model_filenames, unmapped(train_test_dataset_filename[1]))
cleanup_files = cleanup_file.map(
flatten([[dataset_filename], model_filenames, train_test_dataset_filename]))
cleanup_files.set_upstream(eval_model_filenames)
Client().create_project(project_name=PROJECT_NAME)
flow.register(project_name=PROJECT_NAME, labels=['prefect_aws_local_label'],
set_schedule_active=False)
code_12/tasks_train_model.py
code_12/tasks.py
Code-11에서 train_model Task를 따로 분리해서 별도의 Flow로 만듭니다. code_12/tasks.py, code_12/tasks_train_model.py는 큰 수정이 없어서 Code를 생략하였습니다. 주요 변경사항은 다음과 같습니다.
train_modelTask를code_12_train_model_flowFlow에서 실행합니다.train_dataset_filename과alpha는 Flow의Parameter로 전달받아서train_model에 그대로 전달합니다.
prefect_aws_train_model_local_labelLabel의 Agent에서code_12_train_model_flowFlow를 실행하도록 Register합니다.train_model.map과 유사한 역할을 하는train_models를 Function으로 구현합니다.get_train_model_flow_param.map로 Parameter Dict의 List를 만듭니다.create_flow_run.map로code_12_train_model_flowFlow를 여러 Parameter로 동시에 실행합니다.get_task_run_result.map로 여러train_modelTask 실행결과를 동시에 읽습니다.code_12_train_model_flowFlow에서 첫 번째로train_modelTask를 실행한 결과를 읽기 위해서task_slug는train_model-1으로 설정합니다.
train_model이 다른 Task와는 다르게 별도의 Flow에서 실행하도록 했기 때문에 train_model은 별도의 Agent에서 실행하는 것이 가능합니다. Agent를 다른 Server에서 실행하면 train_model만 다른 Server에서 실행하게 하는 것도 가능합니다. Machine Learning 작업을 하다 보면 Model을 Train할 때 GPU를 사용하는 경우가 많이 있는데, 이런 경우에 train_model만 GPU가 있는 Server에서 실행하도록 하면, 소중한 GPU를 효율적으로 사용할 수 있습니다.
prefect_aws_train_model_local_label의 Agent를 다음과 같이 실행합니다.
$ virtualenv -p python3 ~/prefect_aws_train_model_local_agent_env
$ source ~/prefect_aws_train_model_local_agent_env/bin/activate
$ pip install prefect==0.15.4 scikit-learn==0.24.2 s3path==0.3.2 awscli==1.20.53
$ cd ~/work/prefect_aws
$ prefect agent local start --api http://localhost:4200 --label prefect_aws_train_model_local_label
code_12_train_model_flow Flow를 다음과 같이 Register합니다.
$ source ~/prefect_aws_train_model_local_agent_env/bin/activate
$ cd ~/work/prefect_aws
$ python -m code_12.flow_train_model
code_12_flow Flow를 다음과 같이 Register합니다.
$ source ~/prefect_aws_local_agent_env/bin/activate
$ cd ~/work/prefect_aws
$ python -m code_12.flow
Prefect Server UI에서 Agents를 보면 prefect_aws_train_model_local_label Label의 Agent와 prefect_aws_local_label Label의 Agent가 Prefect Server에 접속해 있습니다.
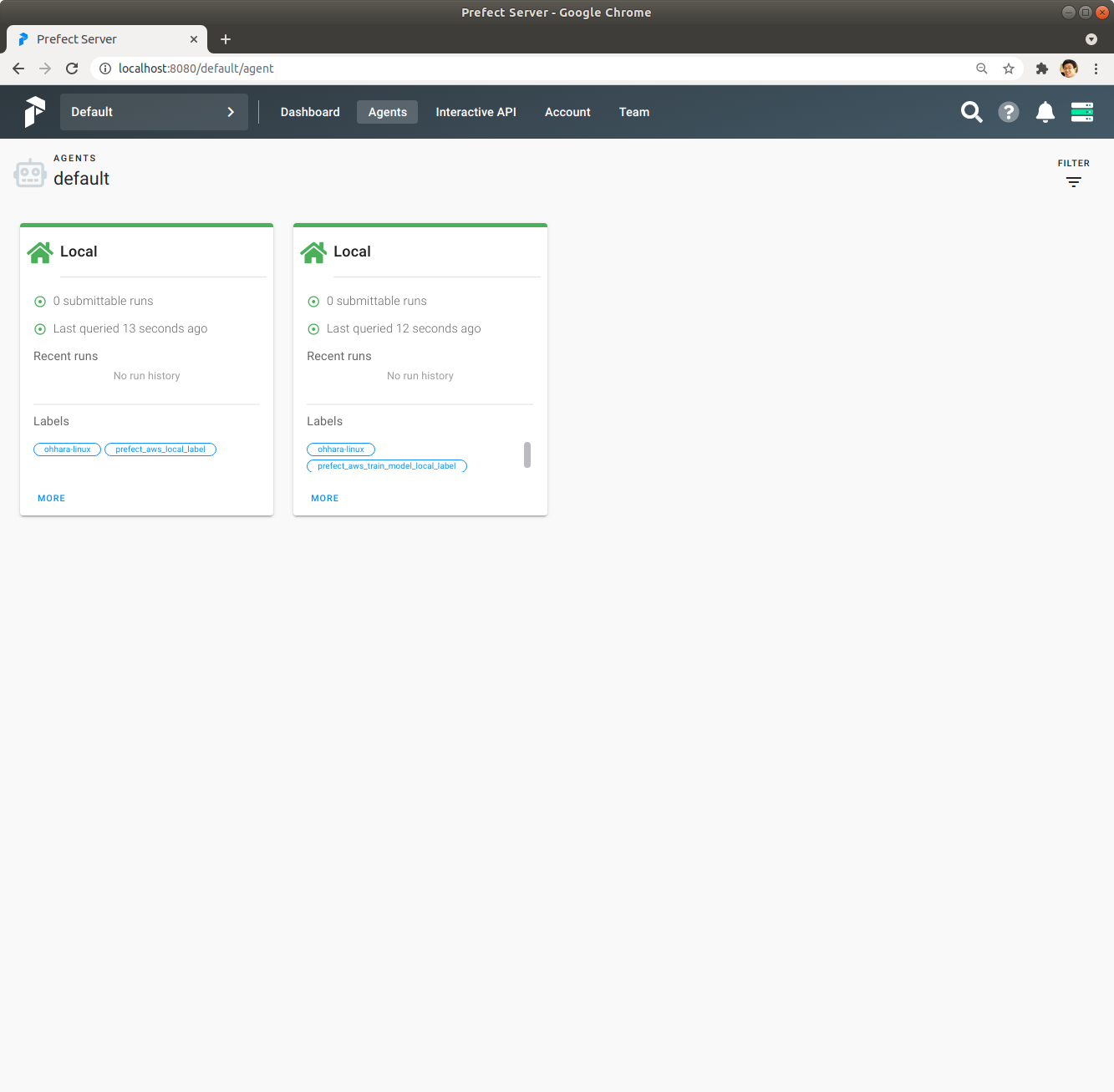
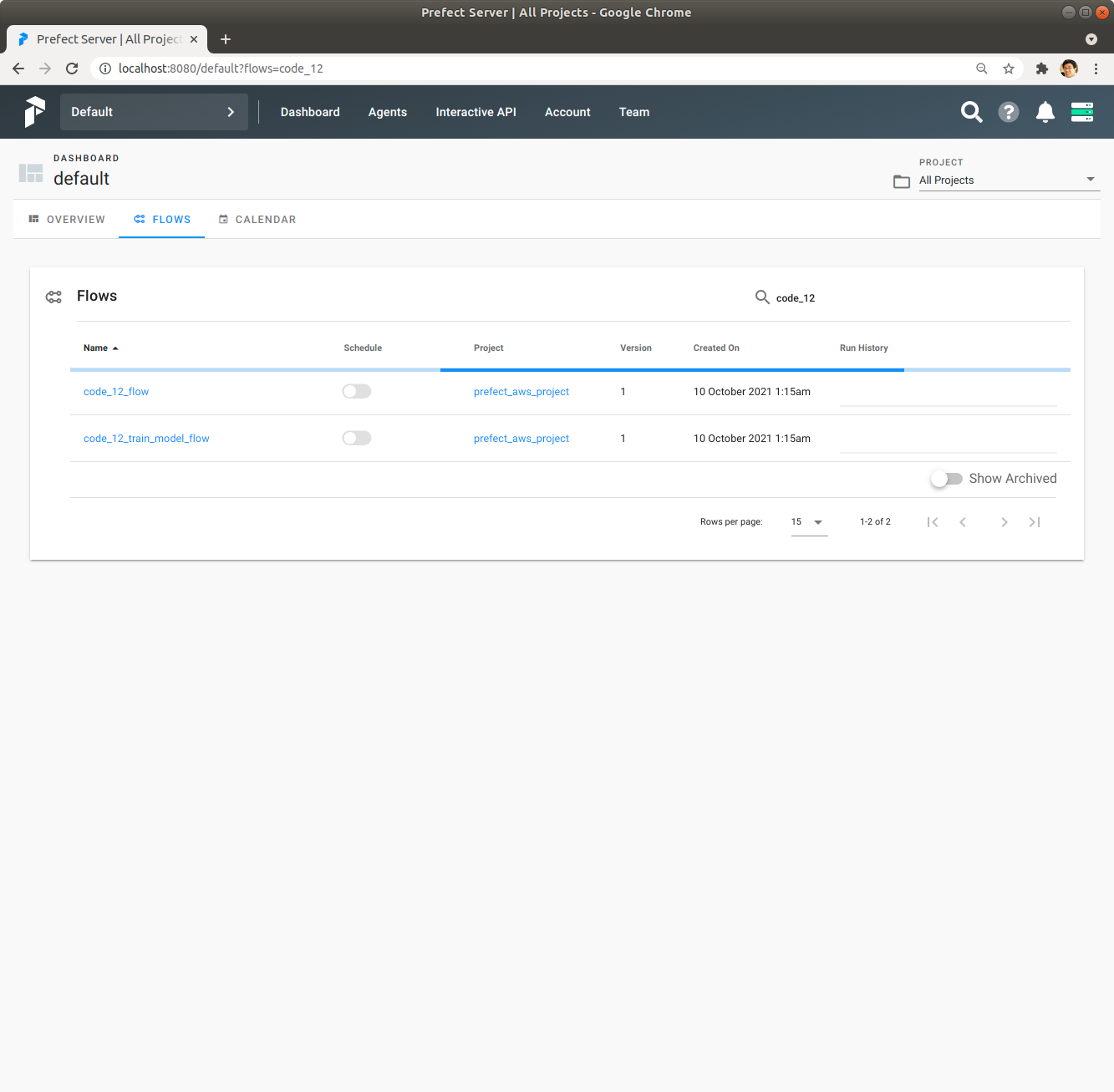
Prefect Server UI에서 Flows를 Click해서 확인해 보면 code_12_flow와 code_12_train_model_flow가 prefect_aws_project Project에 등록되어 있습니다.
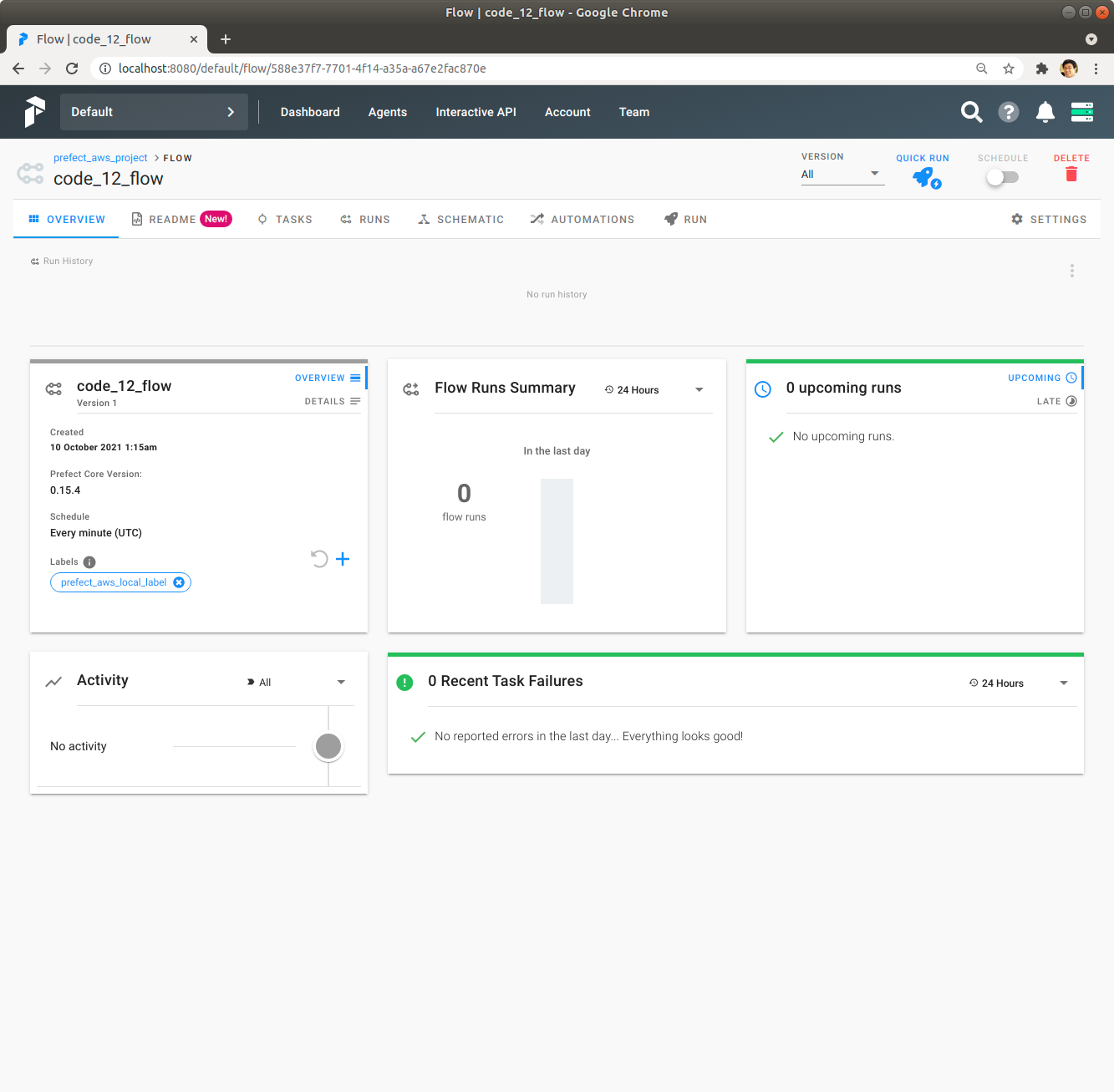
code_12_flow Flow를 Click해서 내용을 확인합니다.
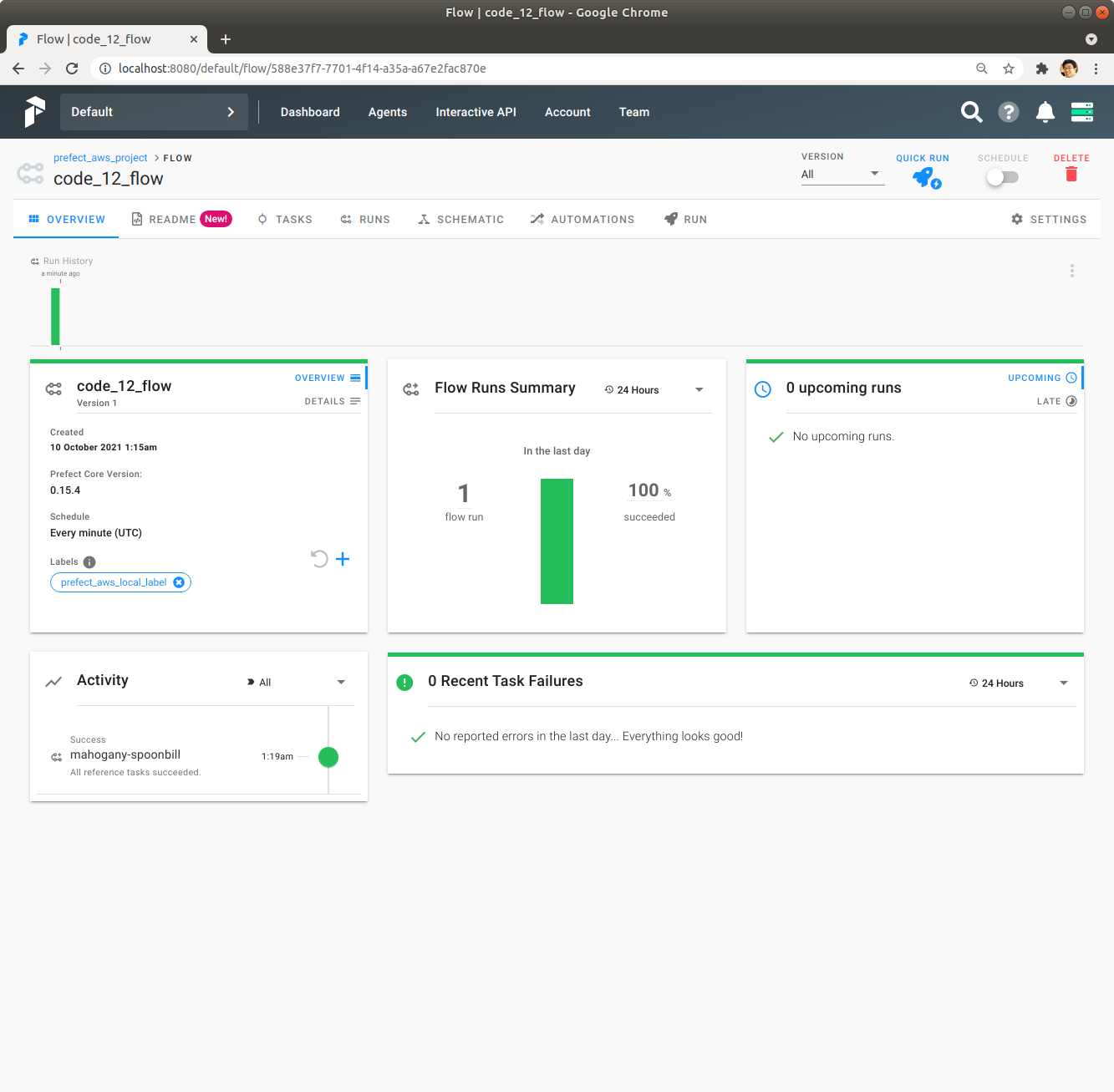
우측 상단에 있는 Quick Run을 Click하여 code_12_flow Flow를 실행합니다. 잠시 기다리면 녹색 막대가 나오면서 code_12_flow Flow의 실행이 성공적으로 완료됩니다.
녹색 막대를 Click해서 각 Task의 실행시간 등 자세한 정보를 확인합니다.
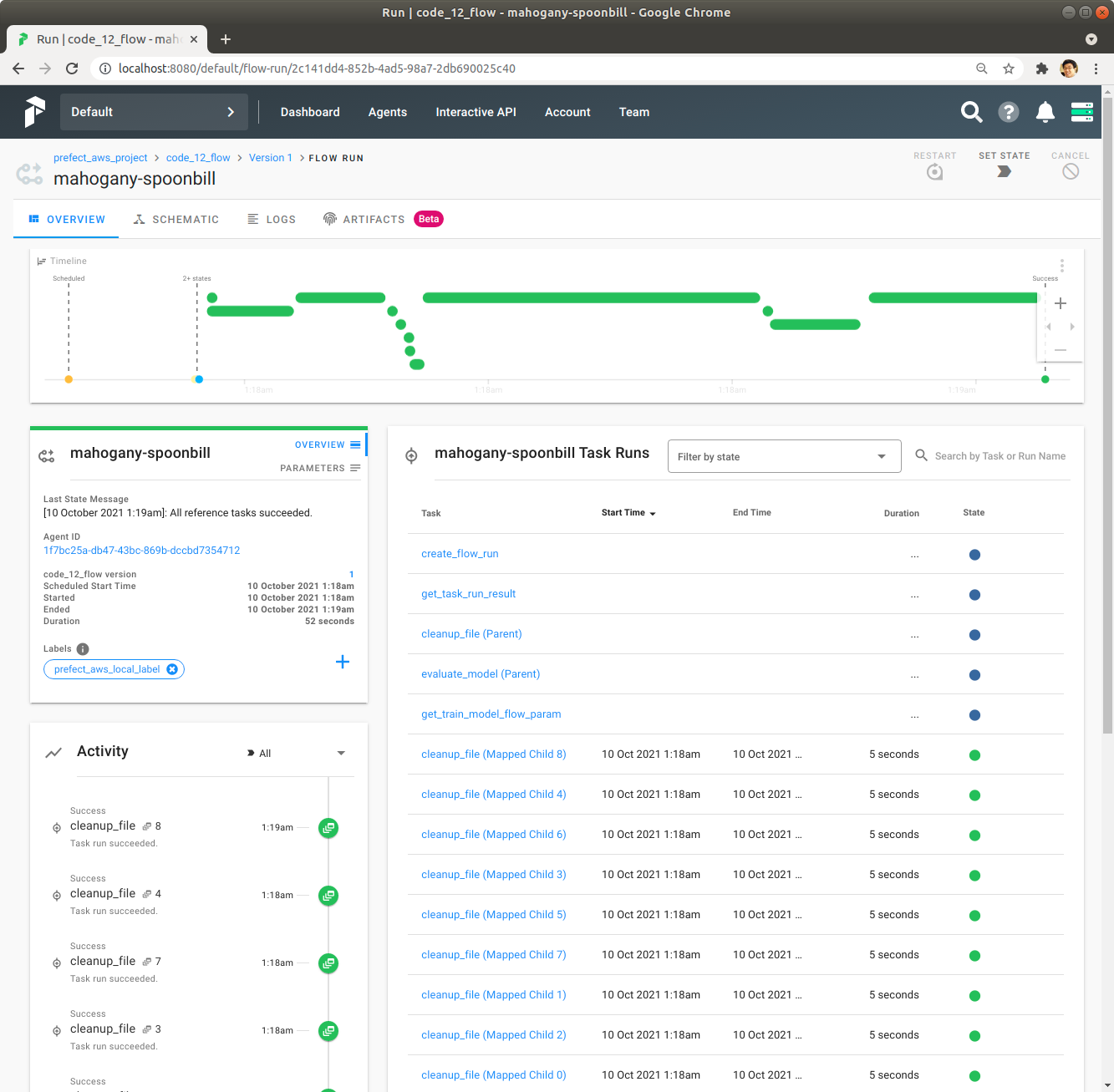
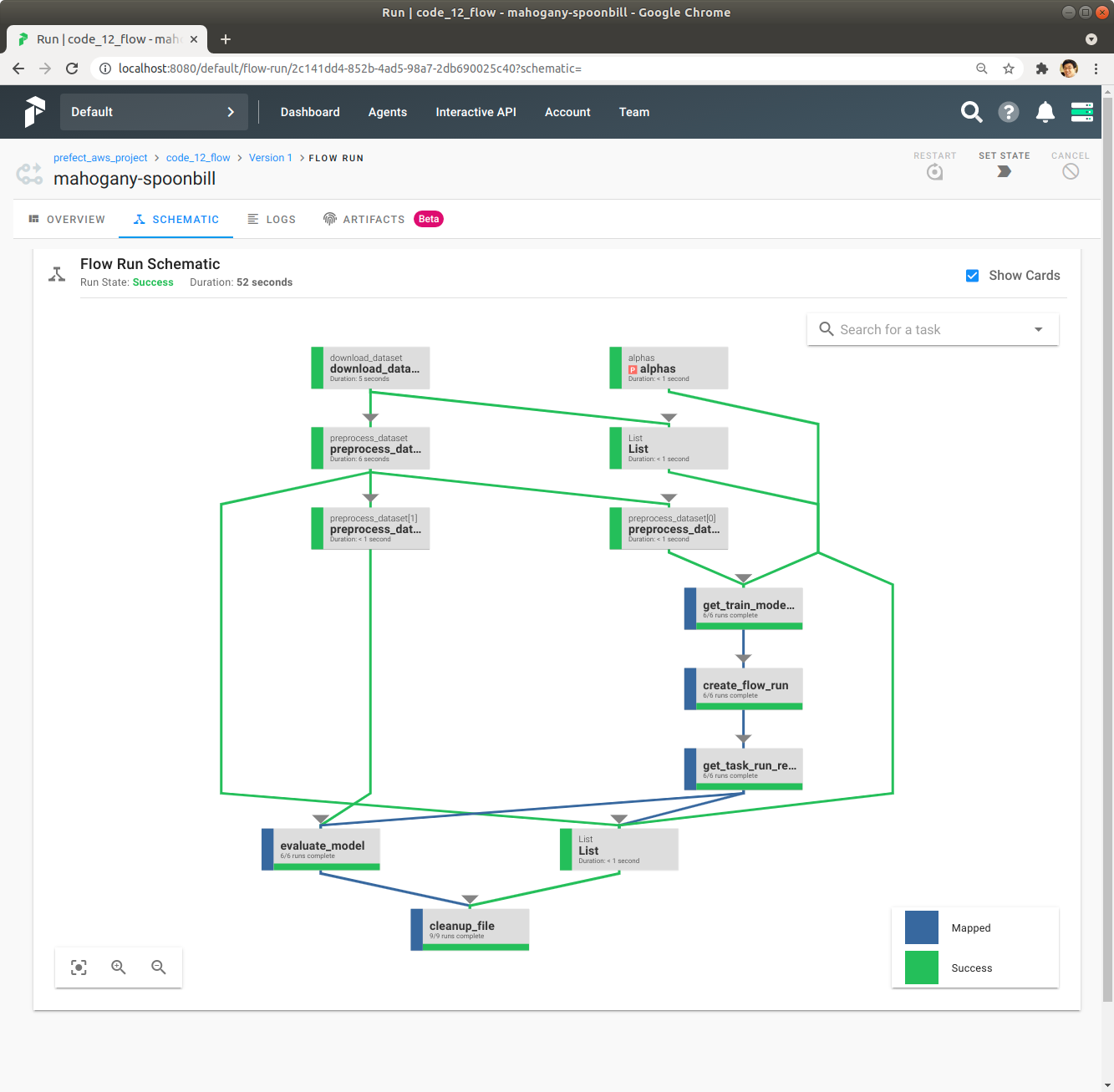
Schematic을 Click해서 Flow의 자세한 정보를 확인합니다. train_model Task는 Flow로 바꿨기 때문에 이 Schematic에서는 train_model에 대한 자세한 정보는 보이지 않습니다.
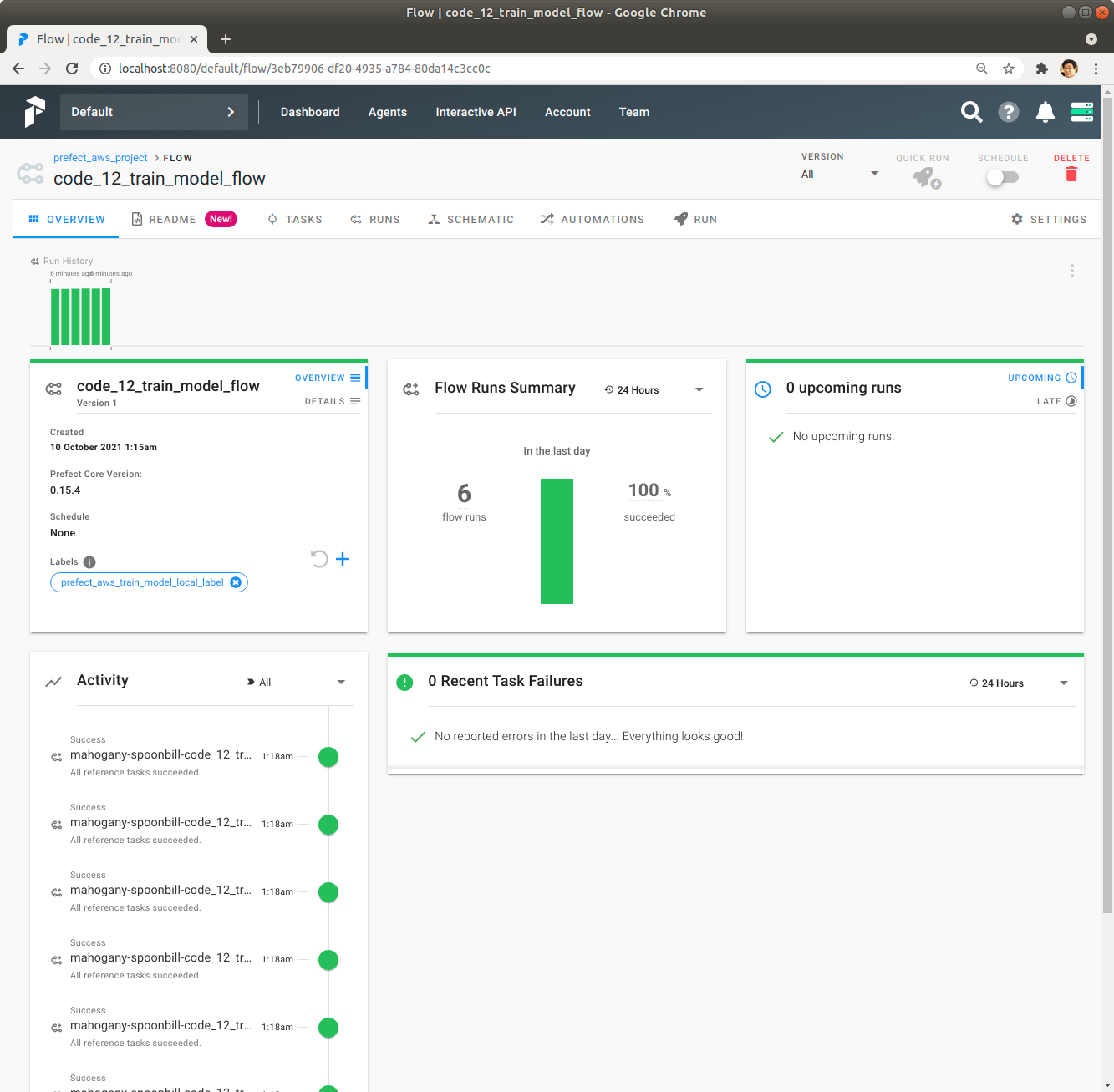
code_12_train_model_flow Flow의 내용을 확인합니다. Flow가 여러 alpha에 대해 실행되어서 총 6번 실행되었습니다.
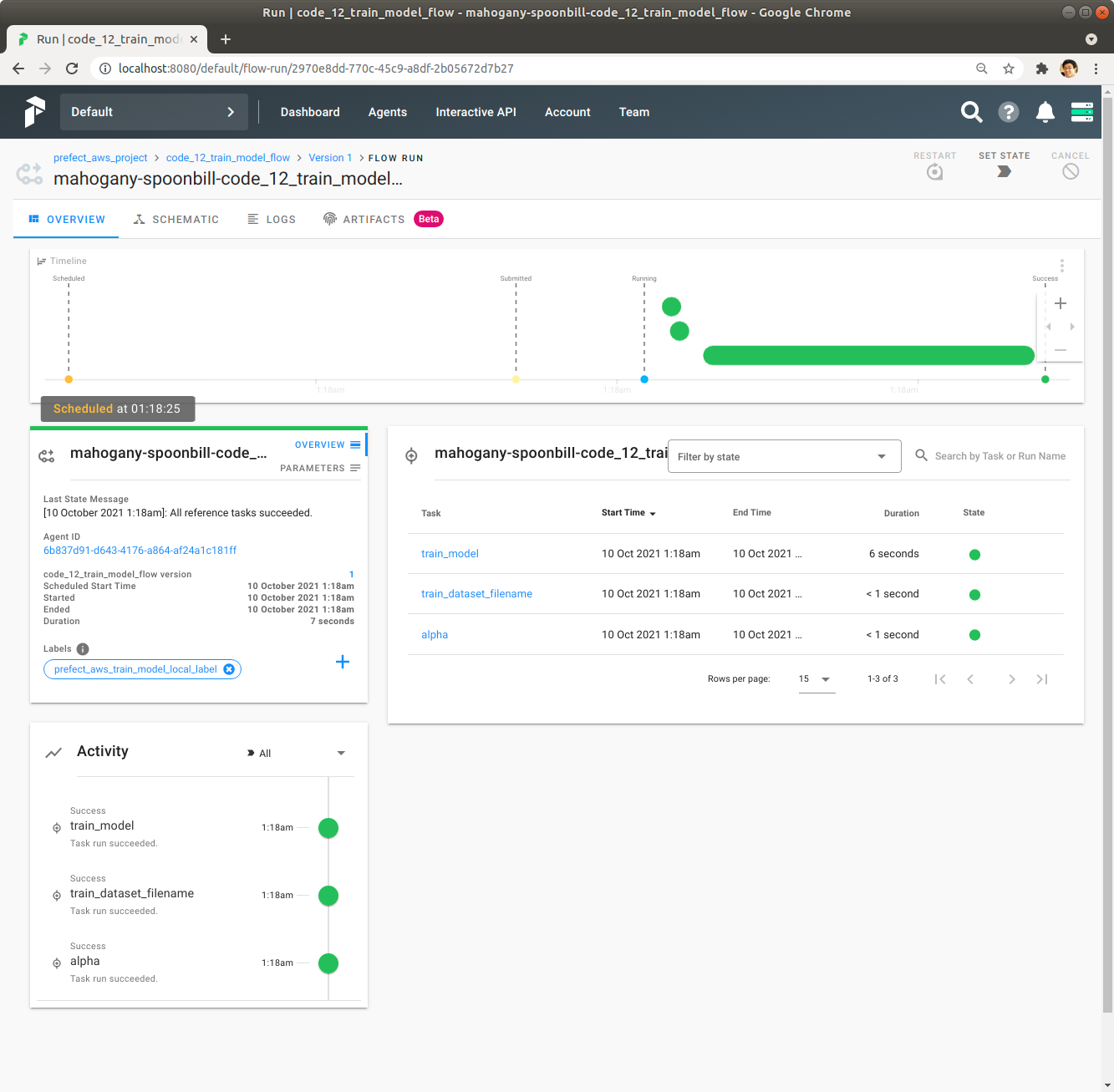
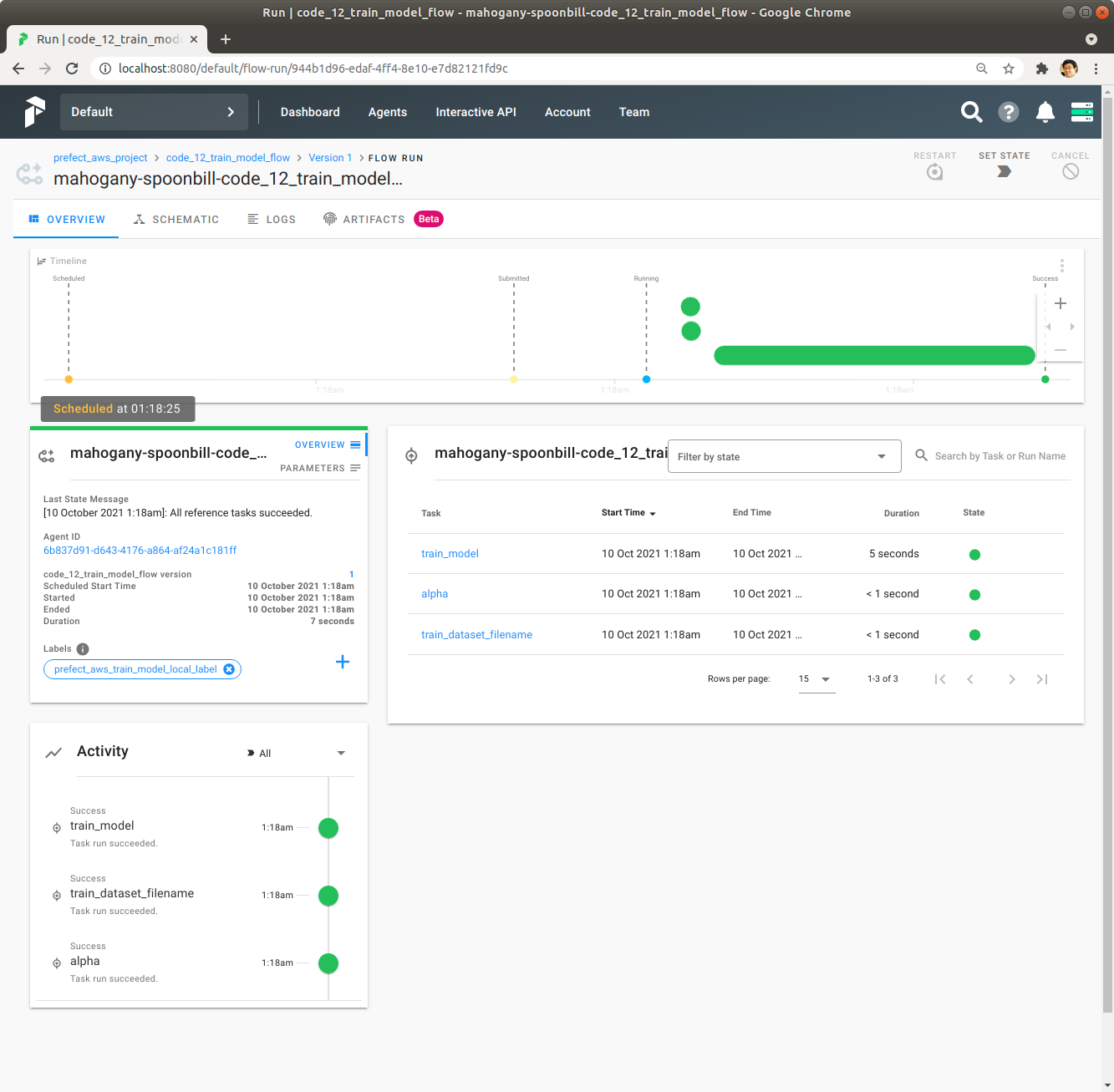
녹색 막대를 하나 Click해서 각 Task의 실행시간 등 자세한 정보를 확인합니다. Schedule된 시각이 01:18:25인 것을 확인합니다.
좌측 중앙의 Parameters를 Click해서 Flow에 전달된 Parameter를 확인합니다. alpha Parameter가 1인 것을 확인합니다.
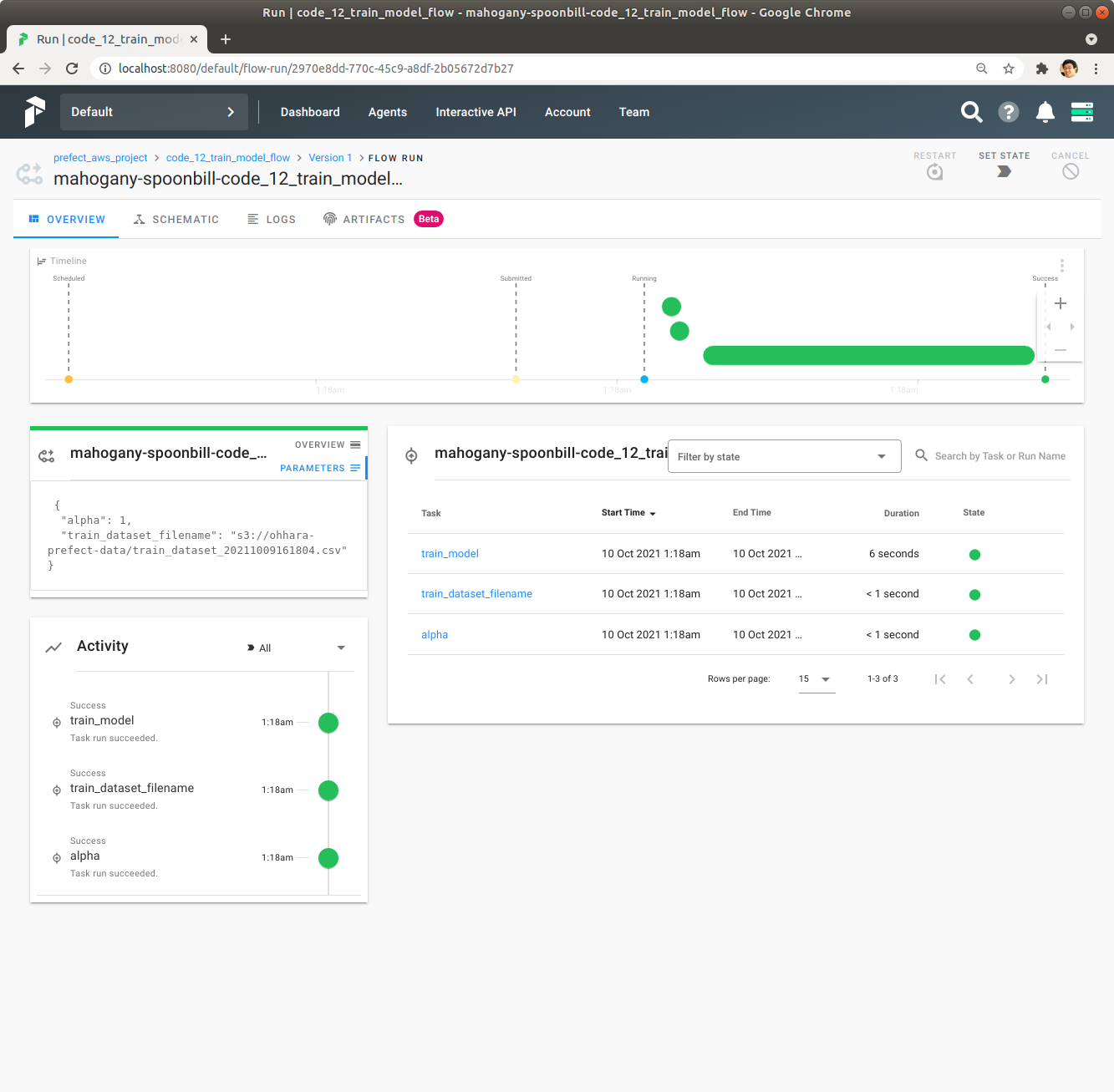
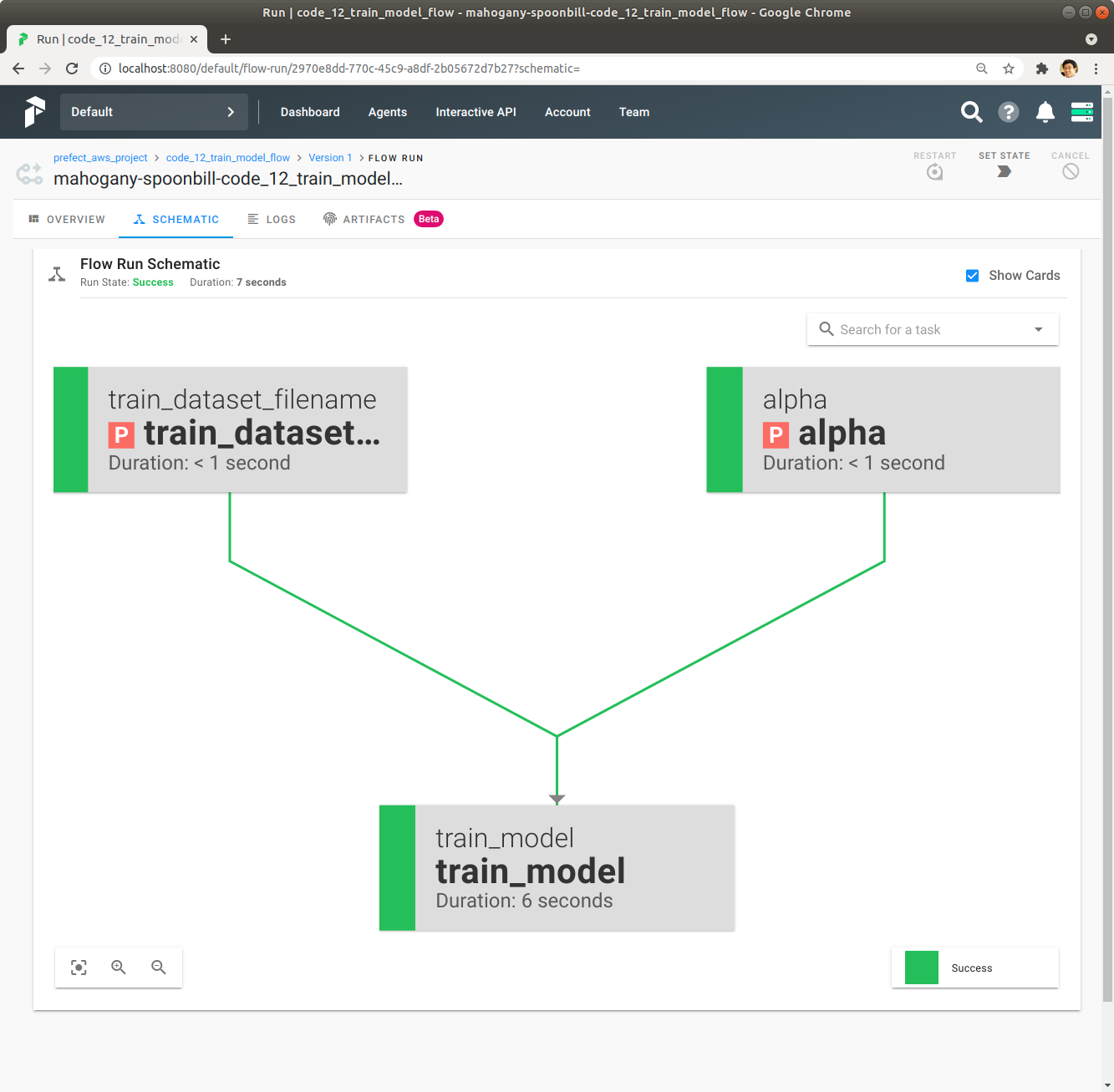
Schematic을 Click해서 code_12_train_model_flow Flow의 Schematic을 확인합니다. train_model Task의 상세한 Dependency를 확인합니다.
code_12_train_model_flow Flow 다른 Flow Run을 확인합니다. Schedule된 시각이 01:18:25로 앞에서 확인한 것과 동일한 것을 확인합니다.
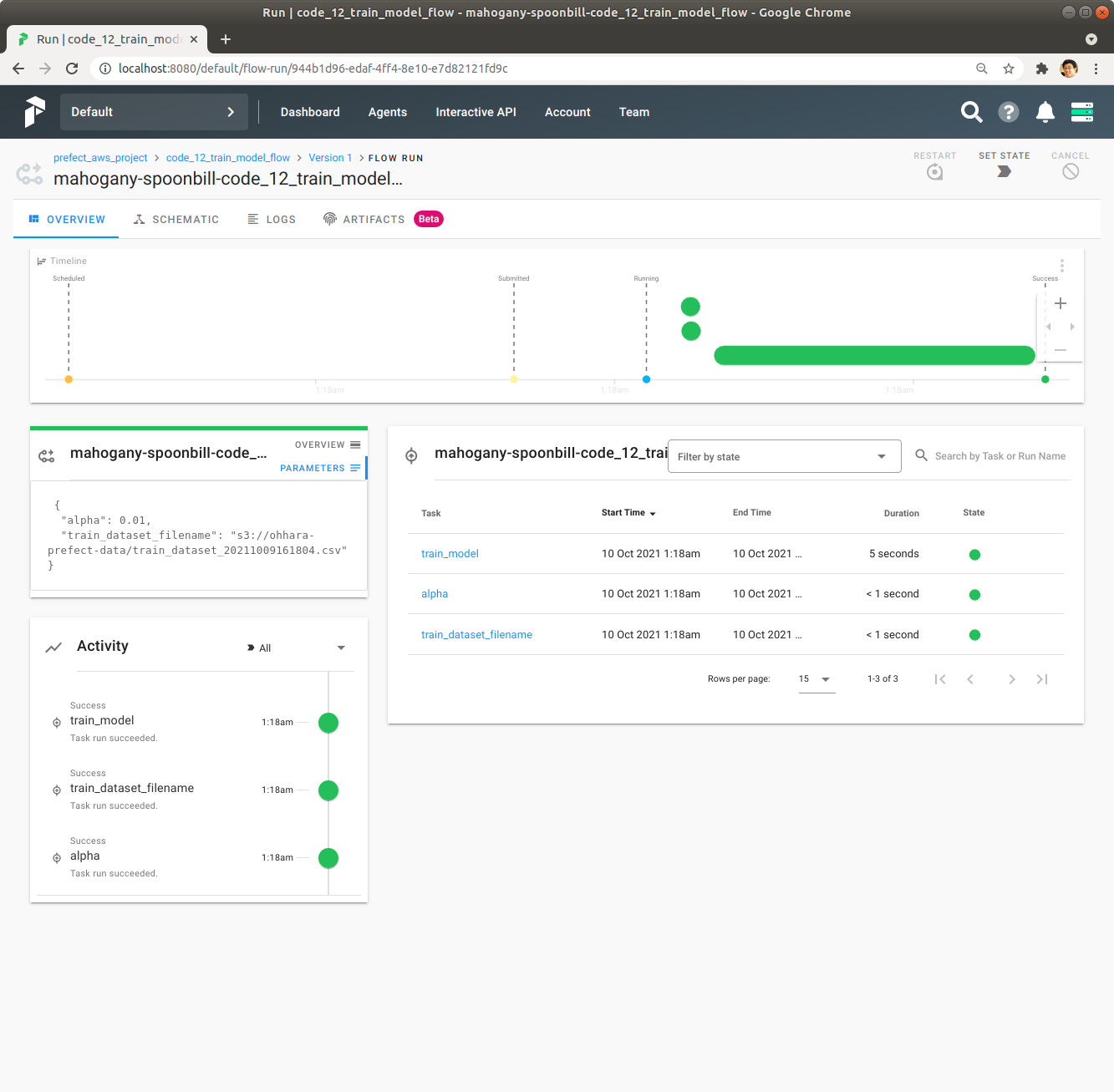
좌측 중앙의 Parameters를 Click해서 Flow에 전달된 Parameter를 확인합니다. alpha Parameter가 0.01로 앞에서 확인한 것과 다른 것을 확인합니다. 즉, code_12_train_model_flow는 여러 alpha Parameter로 동시에 실행된 것을 알 수 있습니다.
Code 13
Dockerfile
FROM prefecthq/prefect:0.15.4-python3.6
RUN prefect backend server
RUN pip install --no-cache-dir scikit-learn==0.24.2 s3path==0.3.2 awscli==1.20.53 kubernetes==18.20.0
WORKDIR /prefect_aws
ADD . /prefect_aws
code_13/flow_train_model.py
from prefect import Flow, Client, Parameter
from prefect.executors import LocalDaskExecutor
from prefect.storage import S3
from prefect.run_configs.docker import DockerRun
from .tasks_train_model import train_model
PROJECT_NAME = 'prefect_aws_project'
with Flow('code_13_train_model_flow', executor=LocalDaskExecutor(),
storage=S3(bucket='ohhara-prefect-storage'),
run_config=DockerRun(image='ohhara/prefect_aws:latest')) as flow:
train_dataset_filename = Parameter('train_dataset_filename')
alpha = Parameter('alpha');
train_model(train_dataset_filename, alpha)
Client().create_project(project_name=PROJECT_NAME)
flow.register(
project_name=PROJECT_NAME, labels=['prefect_aws_train_model_docker_label'])
code_13/flow.py
code_13/tasks_train_model.py
code_13/tasks.py
Code-12에서 train_model Task를 실행하는 Flow를 Dockerize합니다. code_13/flow.py, code_13/tasks_train_model.py, code_13/tasks.py는 큰 수정이 없어서 Code를 생략하였습니다. 주요 변경사항은 다음과 같습니다.
- Docker Image에 Prefect와 기타 필요한 Python Package들을 설치하고
prefect_awsDirectory를 복사하도록Dockerfile을 구성합니다.kubernetesPython Package는 여기서는 설치할 필요가 없지만 나중에 필요하기 때문에 미리 설치합니다. code_13_train_model_flowFlow의run_config를DockerRun(image='ohhara/prefect_aws:latest')로 설정해서ohhara/prefect_aws:latestDocker Image 기반으로 Flow를 실행하도록 합니다.- 직접 이 Code를 사용하는 경우에는 Docker Image는 자신의 환경에 맞춰서 적절하게 변경해서 사용합니다.
prefect_aws_train_model_docker_labelLabel의 Agent에서code_13_train_model_flowFlow를 실행하도록 Register합니다.
prefect_aws_train_model_docker_label Label의 Agent는 code_13_train_model_flow Flow를 실행할 때, Flow를 ohhara-prefect-storage S3 Bucket에서 Download해서 실행합니다. Flow를 실행하면서 중간중간에 Task를 실행하게 되는데, 이때 Task들은 ohhara/prefect_aws:latest Docker Image에서 읽어와서 실행합니다. ohhara/prefect_aws:latest Docker Image의 WORKDIR이 /prefect_aws로 설정되어 있어서, /prefect_aws가 PYTHONPATH에 추가되어 있는 것처럼, /prefect_aws에 있는 Python Module도 Task를 실행하면서 Load할 수 있습니다.
prefect_aws_train_model_docker_label의 Agent를 다음과 같이 실행합니다. Docker 안에서 AWS에 접근하기 위해서는 적절한 Credential의 설정이 필요한데, 여기서는 (Credential이 유출될 우려가 있지만) 쉬운 이해를 위해 Environment Variable로 설정합니다. 이 Agent를 통해서 Flow를 실행할 때 여기서 설정한 Environment Variable들이 설정됩니다.
$ virtualenv -p python3 ~/prefect_aws_train_model_docker_agent_env
$ source ~/prefect_aws_train_model_docker_agent_env/bin/activate
$ pip install prefect==0.15.4 awscli==1.20.53
$ cd ~/work/prefect_aws
$ prefect agent docker start --api http://localhost:4200 --label prefect_aws_train_model_docker_label --env AWS_ACCESS_KEY_ID=`aws configure get aws_access_key_id` --env AWS_SECRET_ACCESS_KEY=`aws configure get aws_secret_access_key` --env AWS_REGION=`aws configure get region`
Docker Image는 다음과 같이 Build하고, code_13_train_model_flow를 Docker 안에서 Register한 후, Docker Hub에 Login하고, Docker Hub에 ohhara/prefect_aws:latest라는 이름으로 Docker Image를 Push합니다. 직접 작업하는 경우에는 Docker Image 이름은 자신의 환경에 맞춰서 적절하게 변경합니다. 참고로 Docker Hub에 Push한 Docker Image는 Default로 Public하게 공개되니 주의합니다.
현재 Prefect Server는 localhost에서 실행되고 있어서, Flow를 Docker 안에서 Register하기 위해서는 Docker 안에서 Host의 localhost에 접근할 수 있도록 해야 합니다. 이를 위해서 Flow의 Register를 위해 Docker를 실행할 때 --network host를 추가하여 Docker안에서의 Network가 Host의 Network과 동일하도록 해 줍니다.
Flow를 Register를 할 때 S3에 Flow를 Upload해야 되므로 Flow의 Register를 위해 Docker를 실행할 때 AWS Credential을 Environment Variable로 설정합니다.
$ docker build -t ohhara/prefect_aws:latest .
$ docker run -e AWS_ACCESS_KEY_ID=`aws configure get aws_access_key_id` -e AWS_SECRET_ACCESS_KEY=`aws configure get aws_secret_access_key` -e AWS_REGION=`aws configure get region` --network host -it --rm ohhara/prefect_aws:latest python -m code_13.flow_train_model
$ docker login
$ docker image push ohhara/prefect_aws:latest
code_13_flow Flow를 다음과 같이 Register합니다.
$ source ~/prefect_aws_local_agent_env/bin/activate
$ cd ~/work/prefect_aws
$ python -m code_13.flow
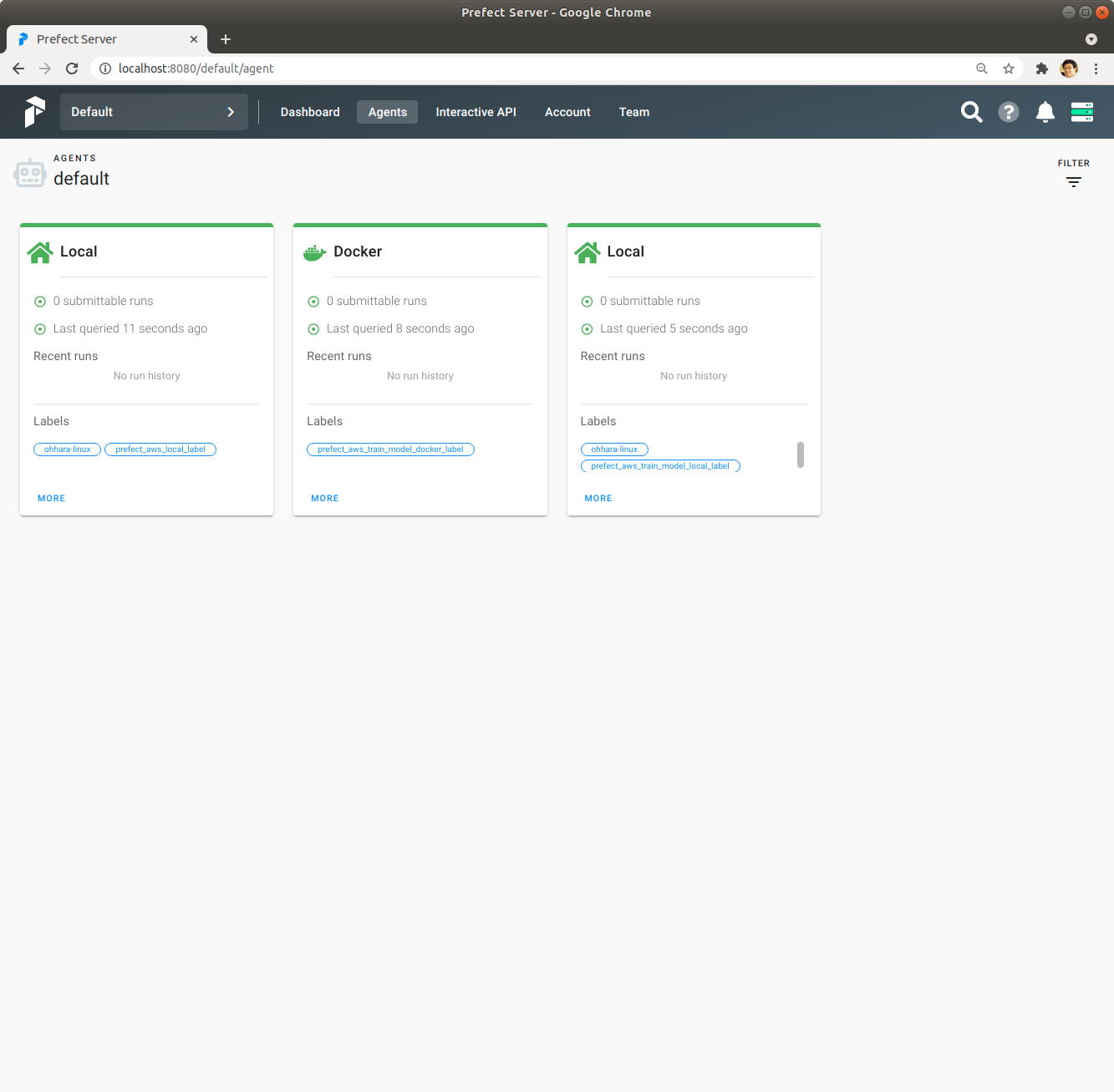
Prefect Server UI에서 Agents를 보면 prefect_aws_train_model_docker_label Label의 Agent가 Prefect Server에 접속해 있습니다.
Prefect Server UI에서 code_13_flow를 실행하고 code_12_flow와 작동이 거의 동일한 것을 확인합니다.
Code 14
code_14/flow_train_model.py
from prefect import Flow, Client, Parameter
from prefect.executors import LocalDaskExecutor
from prefect.storage import S3
from prefect.run_configs.docker import DockerRun
from .tasks_train_model import train_model
PROJECT_NAME = 'prefect_aws_project'
DOCKER_IMAGE = '799537067958.dkr.ecr.ap-northeast-2.amazonaws.com/prefect_aws:latest'
with Flow('code_14_train_model_flow', executor=LocalDaskExecutor(),
storage=S3(bucket='ohhara-prefect-storage'),
run_config=DockerRun(image=DOCKER_IMAGE)) as flow:
train_dataset_filename = Parameter('train_dataset_filename')
alpha = Parameter('alpha');
train_model(train_dataset_filename, alpha)
Client().create_project(project_name=PROJECT_NAME)
flow.register(
project_name=PROJECT_NAME, labels=['prefect_aws_train_model_docker_label'])
Dockerfile
code_14/flow.py
code_14/tasks_train_model.py
code_14/tasks.py
Code-13에서 만든 Docker Image를 ECR에 Upload하고 사용합니다. Dockerfile, code_14/flow.py, code_14/tasks_train_model.py, code_14/tasks.py는 큰 수정이 없어서 Code를 생략하였습니다. 주요 변경사항은 다음과 같습니다.
- Docker Image를
799537067958.dkr.ecr.ap-northeast-2.amazonaws.com/prefect_aws:latest로 설정합니다.- 직접 이 Code를 사용하는 경우에는 Docker Image는 자신의 ECR 환경에 맞춰서 적절하게 변경해서 사용합니다.
ECR을 사용하기 위해서 AWS Account에 적절하게 Permission설정이 되어 있어야 합니다. ECR 사용에 필요한 Permission설정이 되어 있지 않다면 설정하도록 합니다.
Docker를 사용해서 ECR에 접근하기 위해서 다음과 같이 amazon-ecr-credential-helper를 설치합니다. 이렇게 설치하면 Prefect Agent에서도 Docker를 통해 ECR에 접근이 가능해집니다.
$ git clone https://github.com/awslabs/amazon-ecr-credential-helper.git
$ cd amazon-ecr-credential-helper
$ make docker
$ sudo cp bin/local/docker-credential-ecr-login /usr/local/bin/docker-credential-ecr-login
$ sudo chmod 755 /usr/local/bin/docker-credential-ecr-login
$ vi ~/.docker/config.json
(Add following)
{
"credsStore": "ecr-login"
}
$
Docker Image는 다음과 같이 Build하고, code_14_train_model_flow를 Docker 안에서 Register한 후, ECR에 799537067958.dkr.ecr.ap-northeast-2.amazonaws.com/prefect_aws:latest라는 이름으로 Docker Image를 Push합니다. 직접 작업하는 경우에는 Docker Image 이름은 자신의 환경에 맞춰서 적절하게 변경합니다.
$ source ~/prefect_aws_train_model_docker_agent_env/bin/activate
$ cd ~/work/prefect_aws
$ docker build -t 799537067958.dkr.ecr.ap-northeast-2.amazonaws.com/prefect_aws:latest .
$ docker run -e AWS_ACCESS_KEY_ID=`aws configure get aws_access_key_id` -e AWS_SECRET_ACCESS_KEY=`aws configure get aws_secret_access_key` -e AWS_REGION=`aws configure get region` --network host -it --rm 799537067958.dkr.ecr.ap-northeast-2.amazonaws.com/prefect_aws:latest python -m code_14.flow_train_model
$ aws ecr create-repository --repository-name prefect_aws
$ docker image push 799537067958.dkr.ecr.ap-northeast-2.amazonaws.com/prefect_aws:latest
code_14_flow Flow를 다음과 같이 Register합니다.
$ source ~/prefect_aws_local_agent_env/bin/activate
$ cd ~/work/prefect_aws
$ python -m code_14.flow
Prefect Server UI에서 code_14_flow를 실행하고 code_13_flow와 작동이 거의 동일한 것을 확인합니다.
Code 15
code_15/flow_train_model.py
from prefect import Flow, Client, Parameter
from prefect.executors import LocalDaskExecutor
from prefect.storage import S3
from prefect.run_configs.kubernetes import KubernetesRun
from .tasks_train_model import train_model
PROJECT_NAME = 'prefect_aws_project'
DOCKER_IMAGE = '799537067958.dkr.ecr.ap-northeast-2.amazonaws.com/prefect_aws:latest'
with Flow('code_15_train_model_flow', executor=LocalDaskExecutor(),
storage=S3(bucket='ohhara-prefect-storage'),
run_config=KubernetesRun(image=DOCKER_IMAGE)) as flow:
train_dataset_filename = Parameter('train_dataset_filename')
alpha = Parameter('alpha');
train_model(train_dataset_filename, alpha)
Client().create_project(project_name=PROJECT_NAME)
flow.register(
project_name=PROJECT_NAME, labels=['prefect_aws_train_model_kubernetes_label'])
Dockerfile
code_15/flow.py
code_15/tasks_train_model.py
code_15/tasks.py
Code-14에서 ECR에 Upload한 Docker Image를 EKS에서 실행합니다. Dockerfile, code_15/flow.py, code_15/tasks_train_model.py, code_15/tasks.py는 큰 수정이 없어서 Code를 생략하였습니다. 주요 변경사항은 다음과 같습니다.
code_15_train_model_flowFlow의run_config를DockerRun대신에KubernetesRun으로 설정합니다.prefect_aws_train_model_kubernetes_labelLabel의 Agent에서code_15_train_model_flowFlow를 실행하도록 Register합니다.
EKS를 사용하기 위해서 AWS Account에 적절하게 Permission설정이 되어 있어야 합니다. EKS사용에 필요한 Permission설정이 되어 있지 않다면 설정하도록 합니다.
Kubernetes사용을 위해 kubectl을 다음과 같이 설치합니다.
$ sudo curl -o /usr/local/bin/kubectl https://amazon-eks.s3.us-west-2.amazonaws.com/1.21.2/2021-07-05/bin/linux/amd64/kubectl
$ sudo chmod 755 /usr/local/bin/kubectl
EKS사용을 위해 eksctl을 다음과 같이 설치합니다.
$ curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | sudo tar xz -C /usr/local/bin
prefect-cluster EKS Cluster를 다음과 같이 생성합니다. 약 30분정도 소요됩니다.
$ eksctl create cluster --name=prefect-cluster
prefect_aws_train_model_kubernetes_label의 Agent를 다음과 같이 실행합니다. Prefect에서 EKS를 사용하기 위해서는 EKS Cluster에서 Prefect Server에 접근이 가능해야 합니다. 현재 이 글에서는 Prefect Server를 localhost에 실행하고 있는데 EKS Cluster에서는 localhost로 Prefect Server에 접근할 수가 없기 때문에 EKS Cluster에서 접근이 가능한 Prefect Server의 IP Address를 --api http://175.236.132.225:4200와 같이 설정해서 Agent를 실행합니다.
$ virtualenv -p python3 ~/prefect_aws_train_model_kubernetes_agent_env
$ source ~/prefect_aws_train_model_kubernetes_agent_env/bin/activate
$ pip install prefect==0.15.4 awscli==1.20.53 kubernetes==18.20.0
$ cd ~/work/prefect_aws
$ prefect agent kubernetes start --api http://175.236.132.225:4200 --label prefect_aws_train_model_kubernetes_label --env AWS_ACCESS_KEY_ID=`aws configure get aws_access_key_id` --env AWS_SECRET_ACCESS_KEY=`aws configure get aws_secret_access_key` --env AWS_REGION=`aws configure get region`
Docker Image는 다음과 같이 Build하고, code_15_train_model_flow를 Docker 안에서 Register한 후, ECR에 799537067958.dkr.ecr.ap-northeast-2.amazonaws.com/prefect_aws:latest라는 이름으로 Docker Image를 Push합니다. 직접 작업하는 경우에는 Docker Image 이름은 자신의 환경에 맞춰서 적절하게 변경합니다.
$ source ~/prefect_aws_train_model_kubernetes_agent_env/bin/activate
$ cd ~/work/prefect_aws
$ docker build -t 799537067958.dkr.ecr.ap-northeast-2.amazonaws.com/prefect_aws:latest .
$ docker run -e AWS_ACCESS_KEY_ID=`aws configure get aws_access_key_id` -e AWS_SECRET_ACCESS_KEY=`aws configure get aws_secret_access_key` -e AWS_REGION=`aws configure get region` --network host -it --rm 799537067958.dkr.ecr.ap-northeast-2.amazonaws.com/prefect_aws:latest python -m code_15.flow_train_model
$ aws ecr create-repository --repository-name prefect_aws
$ docker image push 799537067958.dkr.ecr.ap-northeast-2.amazonaws.com/prefect_aws:latest
code_15_flow Flow를 다음과 같이 Register합니다.
$ source ~/prefect_aws_local_agent_env/bin/activate
$ cd ~/work/prefect_aws
$ python -m code_15.flow
Prefect Server UI의 Agents에서 prefect_aws_train_model_kubernetes_label Label의 Agent가 Prefect Server에 접속해 있는 것을 확인합니다.
Prefect Server UI에서 code_15_flow를 실행하고 code_14_flow와 작동이 거의 동일한 것을 확인합니다.
EKS Cluster는 많은 비용이 나오므로 사용후에는 다음과 같이 prefect-cluster EKS Cluster를 삭제합니다.
$ source ~/prefect_aws_train_model_kubernetes_agent_env/bin/activate
$ eksctl delete cluster --name=prefect-cluster --wait
Conclusion
이 글에서는 Prefect를 AWS의 S3, ECR, EKS와 함께 사용하는 방법에 대해 살펴보았습니다. Prefect를 AWS와 함께 사용하는 방법을 이해하는데 조금이나마 도움이 되었으면 좋겠습니다.