Prefect
안녕하세요. 오태호입니다.
Prefect는 Workflow의 관리를 도와주는 Workflow Management System입니다.
이 글에서는 간단한 Machine Learning Workflow를 Prefect를 사용해서 구성해 보면서 Prefect를 이해할 수 있도록 도와드립니다. Luigi나 Airflow와 같은 Workflow Management System을 사용하면서 불편함을 느껴서 다른 Workflow Management System로 변경하는 것을 고려하고 있다면 Prefect도 한 번 검토해 보시기를 추천드립니다. 이 글은 Prefect의 기본적인 내용을 이해하는데 도움을 줄 것으로 생각합니다.
이 글은 Ubuntu 18.04, Python 3.6.7, Prefect 0.15.4, Scikit-learn 0.24.2을 기준으로 작성하였습니다.
이 글을 이해하기 위해서는 Machine Learning에 대한 기초지식이 권장되지만 필수사항은 아닙니다.
Architecture Overview
Prefect는 다음과 같은 구조를 가지고 있습니다.
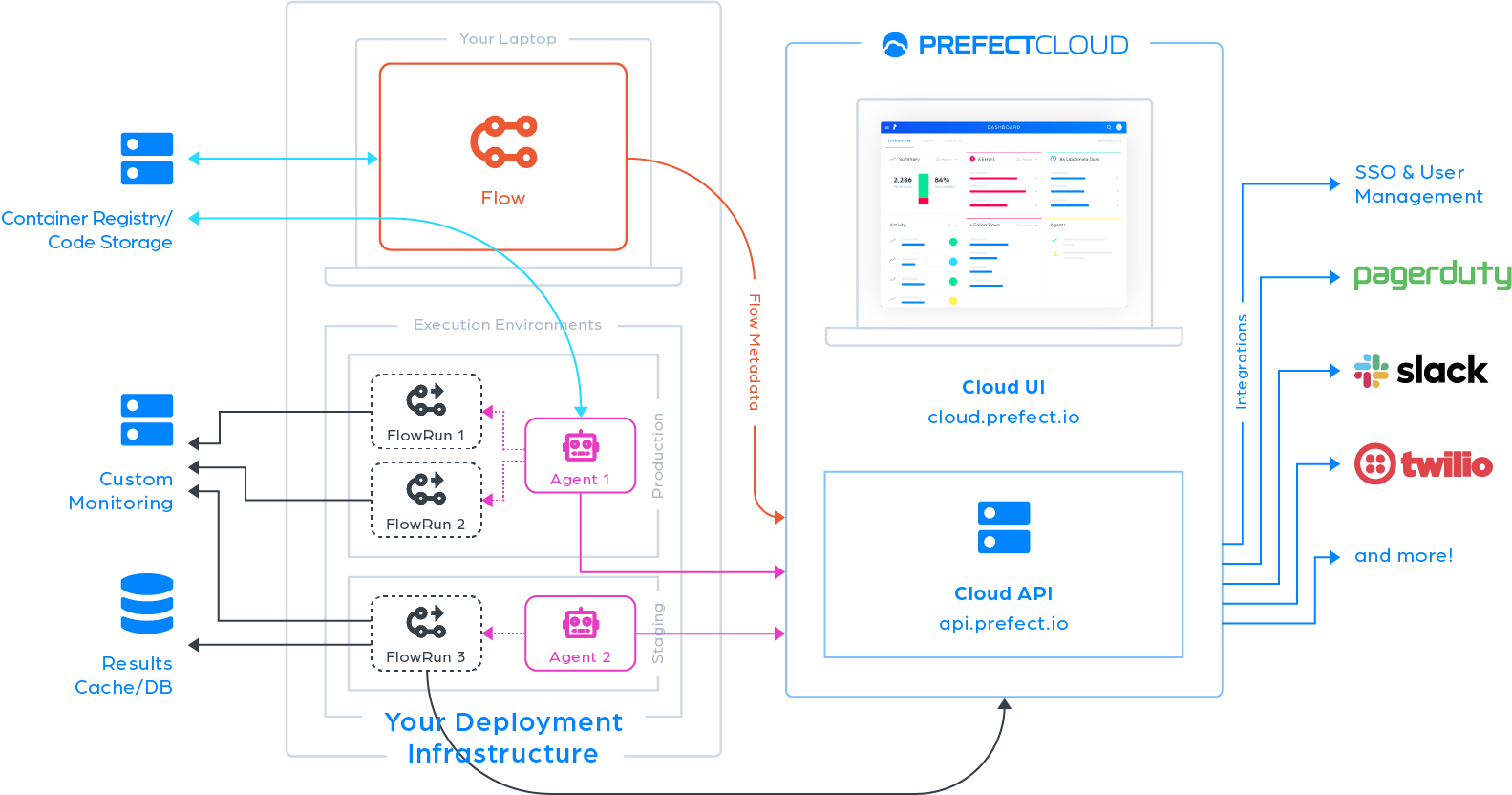
사용자는 관리하고자 하는 작업을 Flow형태로 만들어서 Prefect Server에 등록하고, Flow가 실행되었으면 하는 환경을 Agent형태로 만들어서 Prefect Server에 등록하면, Prefect Server가 등록되어 있는 Flow를 등록되어 있는 Agent를 통해서 실행해 줍니다. Prefect Server의 UI를 통해서 Flow와 Agent의 각종 상태를 확인하거나 각종 설정을 변경할 수 있습니다. 참고로 이 그림에서는 Prefect Cloud가 보이는데, 이것은 Prefect에서 (유료로) 제공해 주는 Prefect Cloud Service로, 이것을 사용하는 대신에 직접 Prefect Server를 실행해서 사용할 수도 있습니다. 이 글에서는 직접 localhost에서 Prefect Server를 실행해서 사용합니다.
Code 1
직접 Code를 실행해 보면서 Prefect사용법을 익혀보도록 하겠습니다. 우선 Prefect를 사용하지 않고 다음과 같은 간단한 Code를 실행해 봅니다.
from pathlib import Path
import numpy as np
from joblib import dump, load
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
def download_dataset():
print('download_dataset begin')
dataset_filename = 'dataset.csv'
random_state = np.random.RandomState(seed=17)
a, b = random_state.uniform(-10, 10, 2)
x_data = random_state.uniform(-10, 10, size=100)
y_data = a * x_data + b + random_state.uniform(-10, 10, size=100)
dataset = np.column_stack((x_data, y_data))
np.savetxt(dataset_filename, dataset, delimiter=',')
print('download_dataset end')
return dataset_filename
def preprocess_dataset(dataset_filename):
print('preprocess_dataset begin')
train_dataset_filename = f'train_{dataset_filename}'
test_dataset_filename = f'test_{dataset_filename}'
dataset = np.loadtxt(dataset_filename, delimiter=',')
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, 0], dataset[:, 1], random_state=23)
train_dataset = np.column_stack((x_train, y_train))
test_dataset = np.column_stack((x_test, y_test))
np.savetxt(train_dataset_filename, train_dataset, delimiter=',')
np.savetxt(test_dataset_filename, test_dataset, delimiter=',')
print('preprocess_dataset end')
return train_dataset_filename, test_dataset_filename
def train_model(train_dataset_filename):
print('train_model begin')
model_filename = str(
Path(f'model_{train_dataset_filename}').with_suffix('.joblib'))
dataset = np.loadtxt(train_dataset_filename, delimiter=',')
model = LinearRegression().fit(dataset[:, 0:1], dataset[:, 1])
dump(model, model_filename)
print('train_model end')
return model_filename
def evaluate_model(model_filename, test_dataset_filename):
print('evaluate_model begin')
eval_model_filename = str(Path(f'eval_{model_filename}').with_suffix('.txt'))
model = load(model_filename)
dataset = np.loadtxt(test_dataset_filename, delimiter=',')
score = model.score(dataset[:, 0:1], dataset[:, 1])
np.savetxt(eval_model_filename, [score])
print('evaluate_model end')
return eval_model_filename
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filename = train_model(train_test_dataset_filename[0])
eval_model_filename = evaluate_model(
model_filename, train_test_dataset_filename[1])
각 부분은 다음과 같은 역할을 합니다.
-
download_datasetDataset을 Download해서
dataset.csv에 저장합니다. 여기서는 이해를 쉽게 할 수 있도록 하기 위해 Dataset을 실제로 Download하지는 않고, Linear Regression으로 학습하기 적당한 가상의 Dataset을 Random하게 생성합니다. -
preprocess_dataset앞에서 저장한 Dataset을 Preprocess한 후 Train Dataset과 Test Dataset으로 나눠서 각각을
train_dataset.csv하고test_dataset.csv에 저장합니다. 여기서는 이해를 쉽게 할 수 있도록 하기 위해 Dataset에 실제로 Preprocess를 하지는 않습니다. -
train_model앞에서 저장한 Train Dataset을 가지고 Model을 Train하여 생성된 Model을
model_train_dataset.joblib에 저장합니다. 여기서는 간단하게 Scikit-learn의 LinearRegression을 사용하여 Model을 생성합니다. -
evaluate_modelpreprocess_dataset에서 저장한 Test Dataset을 사용해서train_model에서 저장한 Model의 성능을 평가하여 평가결과를eval_model_train_dataset.txt에 저장합니다. 여기서는 \(R^2\)를 Model의 성능 평가값으로 사용합니다.
요약하면, Dataset을 Download하고, Dataset을 Preprocess를 하고, Preprocess된 Dataset을 사용해서 Model을 Train하고, Train된 Model을 평가합니다. Machine Learning을 활용하여 작업하다 보면 매우 빈번하게 하게 되는 작업을 이해를 쉽게 할 수 있도록 최대한 단순화시켜 보았습니다. 이 Code를 기반으로 Code를 조금씩 수정하여 Prefect의 기본 개념을 살펴볼 예정입니다.
Code를 살펴보면 Data를 주고받을 때 Memory로 주고받지 않고 모두 File로 저장해서 번거롭게 주고받도록 되어 있습니다. 이렇게 한 이유는 실제로 작업하다 보면 Data가 매우 커서 Memory에 저장하기 힘든 경우가 종종 있기 때문에 그런 상황과 유사한 상황을 재현해 보기 위함입니다. 실제로는 Data가 매우 커서 Local Hard Disk에도 저장하기에 곤란하여 Cloud Storage를 사용해야 되는 경우도 많습니다.
혹시 virtualenv가 설치되어 있지 않다면 다음과 같이 실행하여 설치합니다.
$ sudo apt-get install virtualenv
이 Code의 환경설정과 실행은 다음과 같이 합니다.
$ virtualenv -p python3 ~/scikit_learn_env
$ source ~/scikit_learn_env/bin/activate
$ pip install scikit-learn==0.24.2
$ mkdir -p ~/work/scikit_learn/code_1
$ cd ~/work/scikit_learn/code_1
$ vi code_1.py
$ python code_1.py
실행 후에 다음과 같이 정상적으로 실행된 것을 확인합니다.
$ ls
code_1.py eval_model_train_dataset.txt test_dataset.csv
dataset.csv model_train_dataset.joblib train_dataset.csv
$ cat eval_model_train_dataset.txt
9.655153179853411816e-01
$
Code 2
from pathlib import Path
import numpy as np
from joblib import dump, load
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from prefect import task, Flow
@task
def download_dataset():
print('download_dataset begin')
dataset_filename = 'dataset.csv'
random_state = np.random.RandomState(seed=17)
a, b = random_state.uniform(-10, 10, 2)
x_data = random_state.uniform(-10, 10, size=100)
y_data = a * x_data + b + random_state.uniform(-10, 10, size=100)
dataset = np.column_stack((x_data, y_data))
np.savetxt(dataset_filename, dataset, delimiter=',')
print('download_dataset end')
return dataset_filename
@task
def preprocess_dataset(dataset_filename):
print('preprocess_dataset begin')
train_dataset_filename = f'train_{dataset_filename}'
test_dataset_filename = f'test_{dataset_filename}'
dataset = np.loadtxt(dataset_filename, delimiter=',')
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, 0], dataset[:, 1], random_state=23)
train_dataset = np.column_stack((x_train, y_train))
test_dataset = np.column_stack((x_test, y_test))
np.savetxt(train_dataset_filename, train_dataset, delimiter=',')
np.savetxt(test_dataset_filename, test_dataset, delimiter=',')
print('preprocess_dataset end')
return train_dataset_filename, test_dataset_filename
@task
def train_model(train_dataset_filename):
print('train_model begin')
model_filename = str(
Path(f'model_{train_dataset_filename}').with_suffix('.joblib'))
dataset = np.loadtxt(train_dataset_filename, delimiter=',')
model = LinearRegression().fit(dataset[:, 0:1], dataset[:, 1])
dump(model, model_filename)
print('train_model end')
return model_filename
@task
def evaluate_model(model_filename, test_dataset_filename):
print('evaluate_model begin')
eval_model_filename = str(Path(f'eval_{model_filename}').with_suffix('.txt'))
model = load(model_filename)
dataset = np.loadtxt(test_dataset_filename, delimiter=',')
score = model.score(dataset[:, 0:1], dataset[:, 1])
np.savetxt(eval_model_filename, [score])
print('evaluate_model end')
return eval_model_filename
with Flow('code_2_flow') as flow:
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filename = train_model(train_test_dataset_filename[0])
eval_model_filename = evaluate_model(
model_filename, train_test_dataset_filename[1])
print('dataset_filename', dataset_filename)
print('train_Test_dataset_filename', train_test_dataset_filename)
print('model_filename', model_filename)
print('eval_model_filename', eval_model_filename)
print('flow.run() begin')
flow.run()
print('flow.run() end')
Code 1를 Prefect를 사용해서 실행하기 위해 수정합니다. 주요 변경사항은 다음과 같습니다.
@taskDecorator를 사용하여download_dataset,preprocess_dataset,train_model,evaluate_model을 Prefect Flow에서 호출이 가능한 Task형태로 만듭니다.- Task들을 사용해서 Flow를 생성하여
flow에 저장합니다.with Flow('code_2_flow') as flow:로 시작하는 Flow 생성부분을 보면 실제로 Task들을 실행하는 것처럼 착각할 수 있는데, 여기서는 Task들을 실행하지 않고 Task들이 Flow 실행시에 어떻게 실행되어야 한다라는 연결관계만 생성해서 Flow에 저장합니다.dataset_filename,train_test_dataset_filename,model_filename,eval_model_filename를 print해서 확인해 보면 Task의 실행 결과값이 저장되어 있지 않고 Task가 저장되어 있는 것을 확인할 수 있습니다.- 어떤 Task의 결과물을 어떤 Task가 필요로 한다라는 Dependency관계를 기술하며, 기술된 Task의 순서가 Task의 실행 순서를 의미하지는 않는 것에 주의합니다.
- Tensorflow의 Computation Graph와 비슷한 개념으로 이해하면 이해가 쉽습니다.
flow.run()에서flowFlow를 실행합니다.
이 Code의 환경설정과 실행은 다음과 같이 합니다.
$ virtualenv -p python3 ~/prefect_scikit_learn_agent_env
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ pip install prefect==0.15.4
$ pip install scikit-learn==0.24.2
$ mkdir -p ~/work/prefect_scikit_learn/code_2
$ cd ~/work/prefect_scikit_learn/code_2
$ vi code_2.py
$ python code_2.py
실행시에 다음과 같이 출력됩니다.
dataset_filename <Task: download_dataset>
train_Test_dataset_filename <Task: preprocess_dataset>
model_filename <Task: train_model>
eval_model_filename <Task: evaluate_model>
flow.run() begin
[2021-09-25 22:08:14+0900] INFO - prefect.FlowRunner | Beginning Flow run for 'code_2_flow'
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'download_dataset': Starting task run...
download_dataset begin
download_dataset end
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'download_dataset': Finished task run for task with final state: 'Success'
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'preprocess_dataset': Starting task run...
preprocess_dataset begin
preprocess_dataset end
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'preprocess_dataset': Finished task run for task with final state: 'Success'
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'preprocess_dataset[1]': Starting task run...
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'preprocess_dataset[1]': Finished task run for task with final state: 'Success'
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'preprocess_dataset[0]': Starting task run...
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'preprocess_dataset[0]': Finished task run for task with final state: 'Success'
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'train_model': Starting task run...
train_model begin
train_model end
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'train_model': Finished task run for task with final state: 'Success'
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'evaluate_model': Starting task run...
evaluate_model begin
evaluate_model end
[2021-09-25 22:08:14+0900] INFO - prefect.TaskRunner | Task 'evaluate_model': Finished task run for task with final state: 'Success'
[2021-09-25 22:08:14+0900] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded
flow.run() end
실행 후에 다음과 같이 Code 1과 동일하게 정상적으로 실행된 것을 확인합니다.
$ ls
code_2.py eval_model_train_dataset.txt test_dataset.csv
dataset.csv model_train_dataset.joblib train_dataset.csv
$ cat eval_model_train_dataset.txt
9.655153179853411816e-01
$
Architecture Overview에서 설명할 때는 Flow의 실행을 위해서는 Prefect Server와 Agent가 필요하다고 설명하였는데, 여기서는 Prefect Server와 Agent를 사용하지 않고 Prefect에서 직접 Flow를 실행했습니다. 보통은 Prefect Server와 Agent를 사용해서 Flow를 실행하는데 이와 같이 Flow를 직접 실행하는 것도 가능합니다. 참고로 Flow를 Debug할 때 이렇게 Flow를 직접 실행해 가면서 Debug하는 것이 더 편리합니다.
Prefect Server
Flow를 Prefect Server에서 실행하기 위해 Prefect Server를 설정합니다.
Prefect Server의 실행을 위해서는 Docker가 필요합니다. Docker가 설치되어 있지 않다면 다음과 같이 실행해서 설치합니다.
$ sudo apt-get install curl
$ sudo apt-get install docker.io
$ sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
$ sudo chmod 755 /usr/local/bin/docker-compose
Prefect Server를 다음과 같이 설치하고 실행합니다.
$ virtualenv -p python3 ~/prefect_server_env
$ source ~/prefect_server_env/bin/activate
$ pip install prefect==0.15.4
$ prefect backend server
$ prefect server start
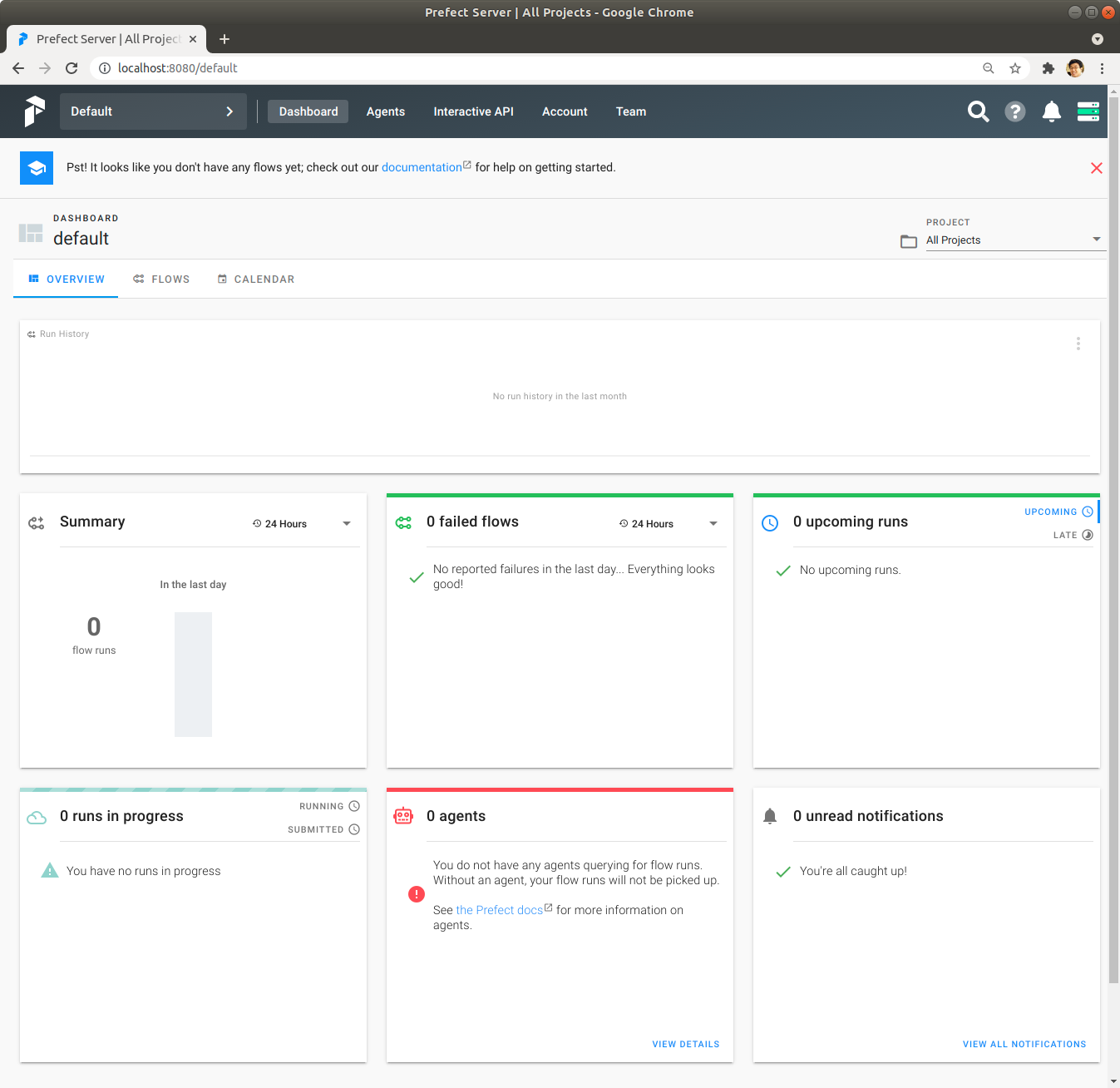
http://localhost:8080에 접속하여 다음과 같이 Prefect Server의 UI에 접속이 되는지 확인합니다.
Code 3
여기에서는 Agent를 이용해서 Flow를 실행합니다. Agent를 다음과 같이 code_3의 Directory에서 scikit_learn_code_3_label Label을 붙이고, localhost:4200에 실행시켜 놓은 Prefect Server에 등록하도록 실행합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_3
$ cd ~/work/prefect_scikit_learn/code_3
$ prefect agent local start --api http://localhost:4200 --label scikit_learn_code_3_label
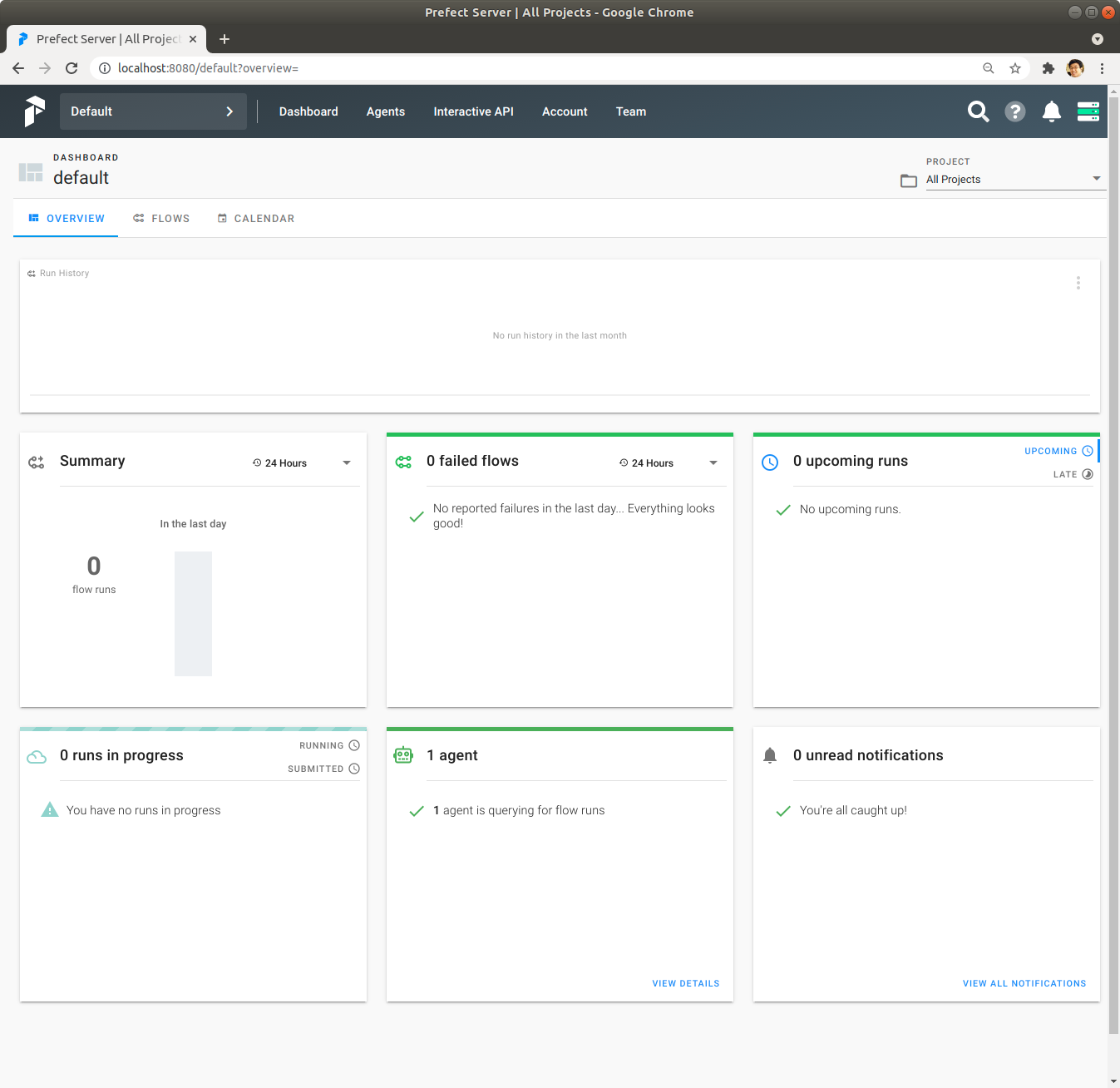
Agent를 실행한 상태에서 Prefect Server UI의 화면을 확인해 보면 다음과 같이 중앙 하단에 Agent 1개가 Prefect Server에 연결되어 있습니다.
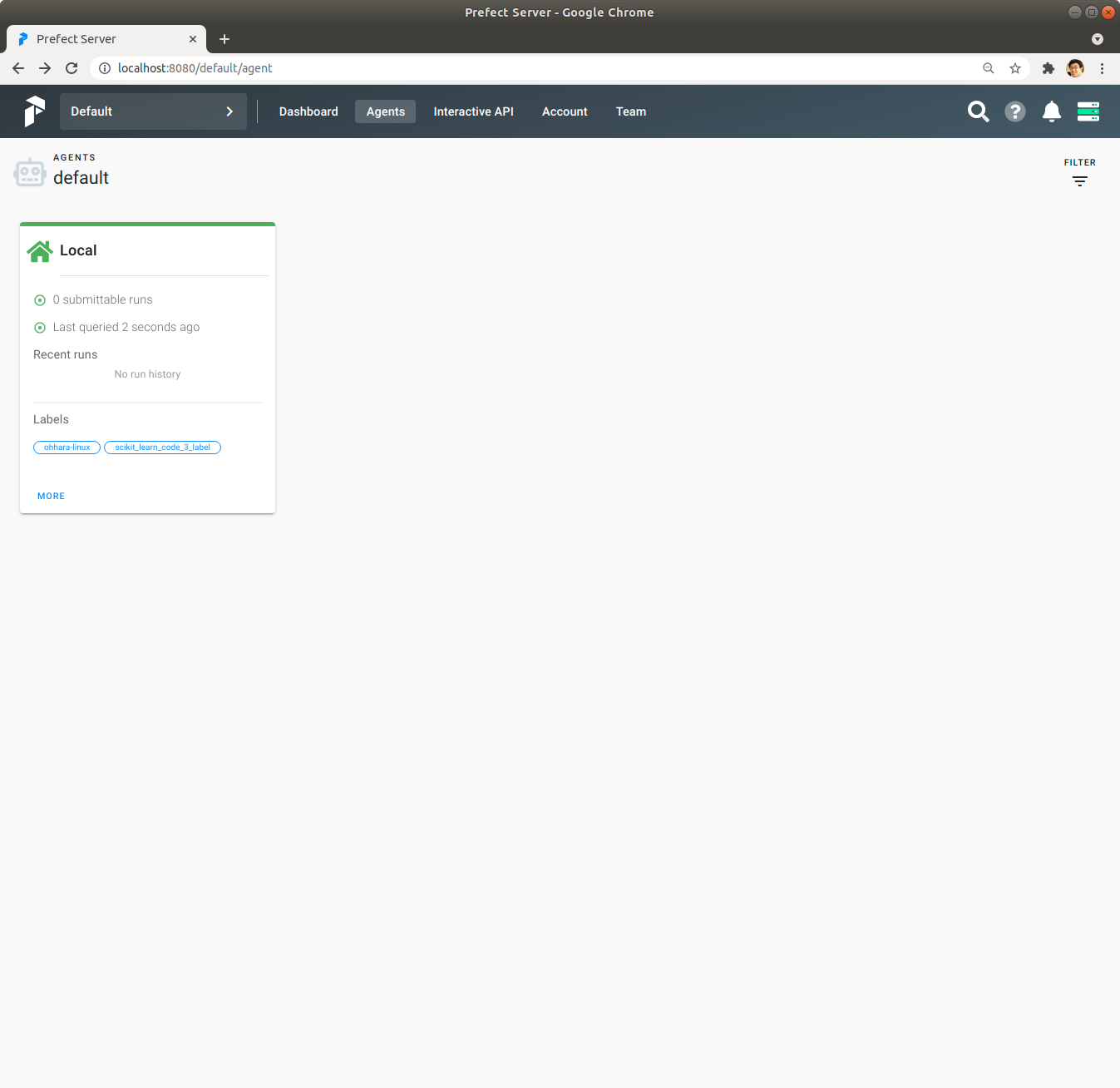
Click해서 확인해 보면 scikit_learn_code_3_label Label을 가지고 있습니다.
from pathlib import Path
import numpy as np
from joblib import dump, load
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from prefect import task, Flow, Client
@task
def download_dataset():
print('download_dataset begin')
dataset_filename = 'dataset.csv'
random_state = np.random.RandomState(seed=17)
a, b = random_state.uniform(-10, 10, 2)
x_data = random_state.uniform(-10, 10, size=100)
y_data = a * x_data + b + random_state.uniform(-10, 10, size=100)
dataset = np.column_stack((x_data, y_data))
np.savetxt(dataset_filename, dataset, delimiter=',')
print('download_dataset end')
return dataset_filename
@task
def preprocess_dataset(dataset_filename):
print('preprocess_dataset begin')
train_dataset_filename = f'train_{dataset_filename}'
test_dataset_filename = f'test_{dataset_filename}'
dataset = np.loadtxt(dataset_filename, delimiter=',')
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, 0], dataset[:, 1], random_state=23)
train_dataset = np.column_stack((x_train, y_train))
test_dataset = np.column_stack((x_test, y_test))
np.savetxt(train_dataset_filename, train_dataset, delimiter=',')
np.savetxt(test_dataset_filename, test_dataset, delimiter=',')
print('preprocess_dataset end')
return train_dataset_filename, test_dataset_filename
@task
def train_model(train_dataset_filename):
print('train_model begin')
model_filename = str(
Path(f'model_{train_dataset_filename}').with_suffix('.joblib'))
dataset = np.loadtxt(train_dataset_filename, delimiter=',')
model = LinearRegression().fit(dataset[:, 0:1], dataset[:, 1])
dump(model, model_filename)
print('train_model end')
return model_filename
@task
def evaluate_model(model_filename, test_dataset_filename):
print('evaluate_model begin')
eval_model_filename = str(Path(f'eval_{model_filename}').with_suffix('.txt'))
model = load(model_filename)
dataset = np.loadtxt(test_dataset_filename, delimiter=',')
score = model.score(dataset[:, 0:1], dataset[:, 1])
np.savetxt(eval_model_filename, [score])
print('evaluate_model end')
return eval_model_filename
with Flow('code_3_flow') as flow:
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filename = train_model(train_test_dataset_filename[0])
eval_model_filename = evaluate_model(
model_filename, train_test_dataset_filename[1])
print('dataset_filename', dataset_filename)
print('train_Test_dataset_filename', train_test_dataset_filename)
print('model_filename', model_filename)
print('eval_model_filename', eval_model_filename)
PROJECT_NAME = 'scikit_learn_project'
Client().create_project(project_name=PROJECT_NAME)
flow.register(project_name=PROJECT_NAME, labels=['scikit_learn_code_3_label'])
Code 2를 Prefect Server와 Agent를 사용해서 실행하기 위해 수정합니다. 주요 변경사항은 다음과 같습니다.
Client().create_project(project_name=PROJECT_NAME)에서scikit_learn_project이름의 Project를 생성합니다. Prefect의 Flow는 Server에 등록할 때 Project가 필요합니다.flow.register(project_name=PROJECT_NAME, labels=['scikit_learn_code_3_label'])에서flowFlow를scikit_learn_projectProject에 등록합니다. Prefect Server가 Flow를 실행할 때 Flow를 실행할 Agent의 Label을scikit_learn_code_3_label로 설정합니다. Prefect Server에 많은 Agent가 등록되는데, 이 Flow가 어떤 Agent에서 실행되어야 되는지 Flow를 등록할 때 Agent의 Label을 설정하여 지정합니다.
이 Code의 환경설정과 실행은 다음과 같이 합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_3
$ cd ~/work/prefect_scikit_learn/code_3
$ vi code_3.py
$ python code_3.py
실행시에 다음과 같이 출력됩니다.
dataset_filename <Task: download_dataset>
train_Test_dataset_filename <Task: preprocess_dataset>
model_filename <Task: train_model>
eval_model_filename <Task: evaluate_model>
Flow URL: http://localhost:8080/default/flow/40819876-bd7e-42cf-8332-7385ddab0d65
└── ID: 4b7ce14b-3eb3-43b9-9e2a-ee6715b31c68
└── Project: scikit_learn_project
└── Labels: ['ohhara-linux', 'scikit_learn_code_3_label']
Flow가 실제로 실행되지는 않고 Prefect Server에 등록만 되었습니다.
Prefect Server UI에서 Flows를 Click해서 확인해 보면 code_3_flow Flow가 scikit_learn_project에 등록되어 있습니다.
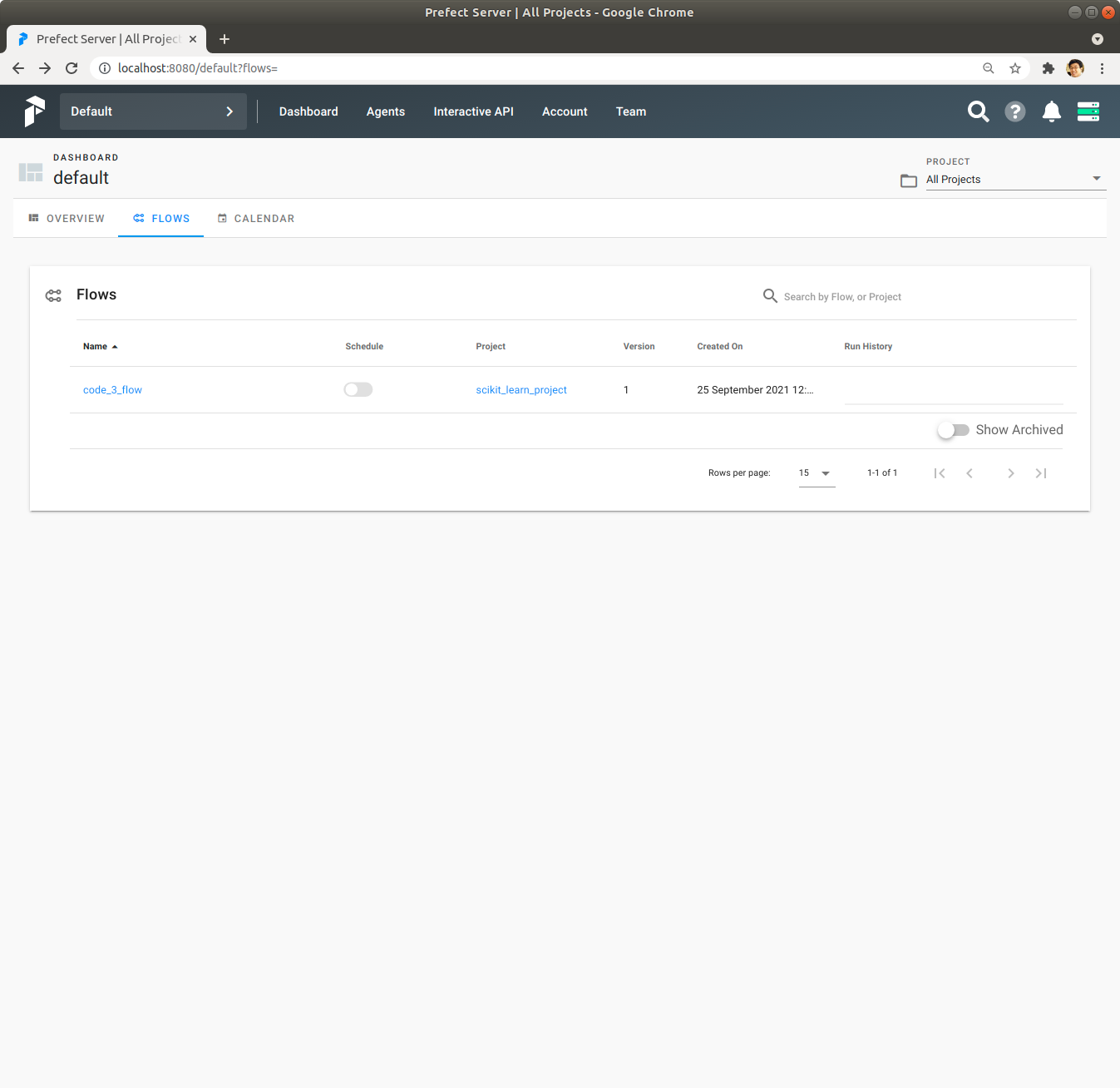
code_3_flow Flow를 Click해서 내용을 확인합니다.
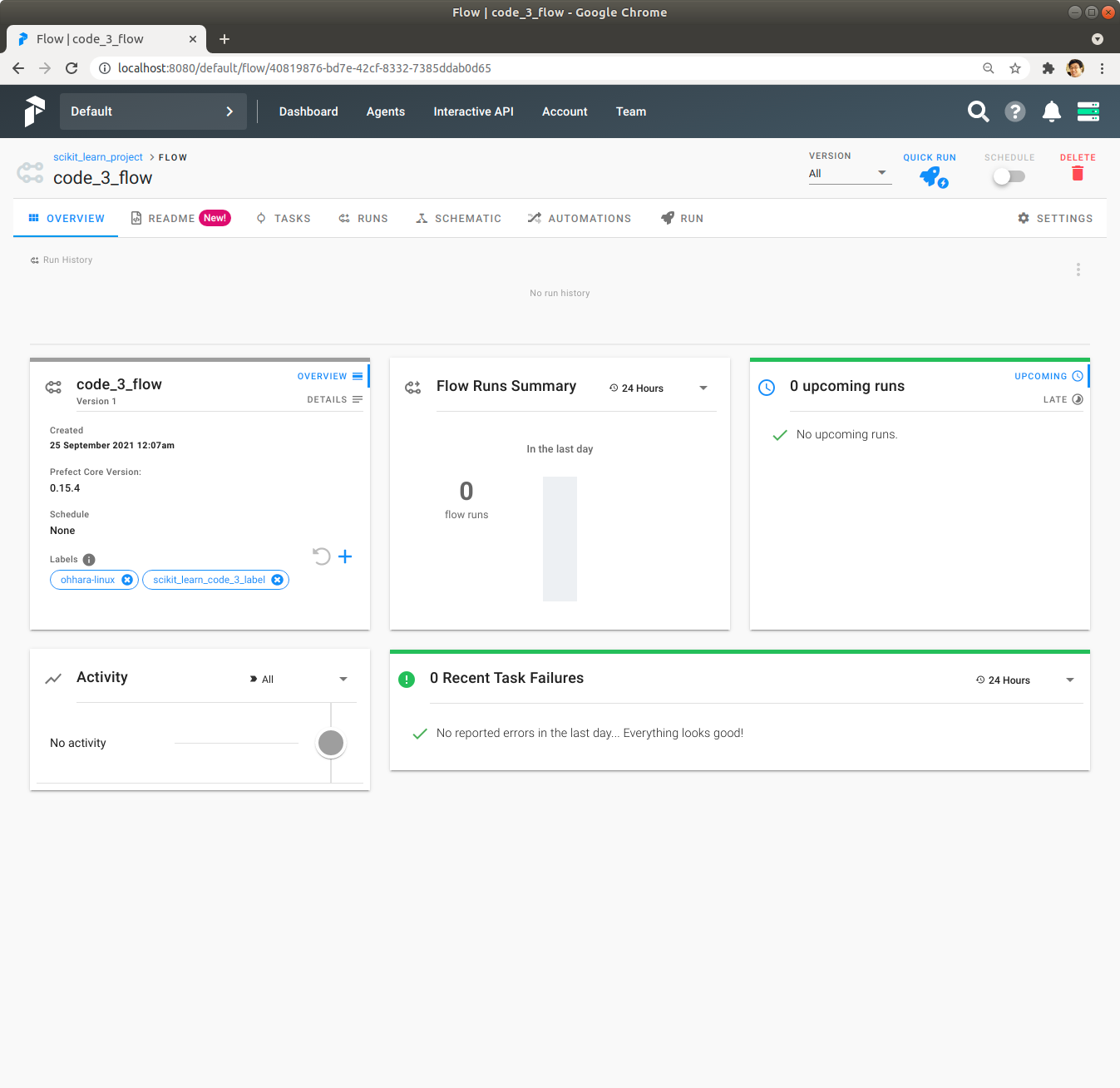
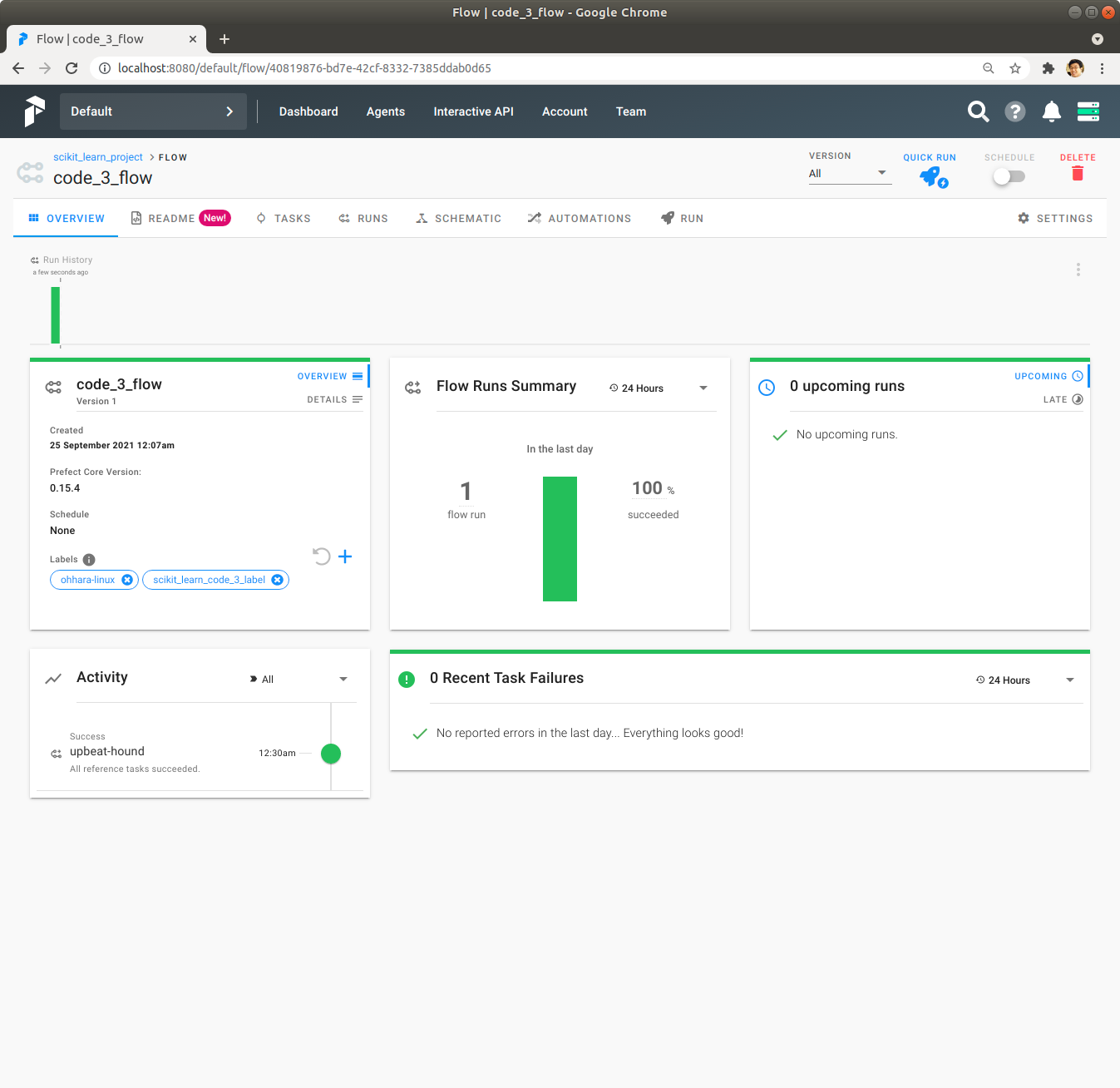
우측 상단에 있는 Quick Run을 Click하여 code_3_flow Flow를 실행합니다. 잠시 기다리면 녹색 막대가 나오면서 code_3_flow Flow의 실행이 성공적으로 완료됩니다.
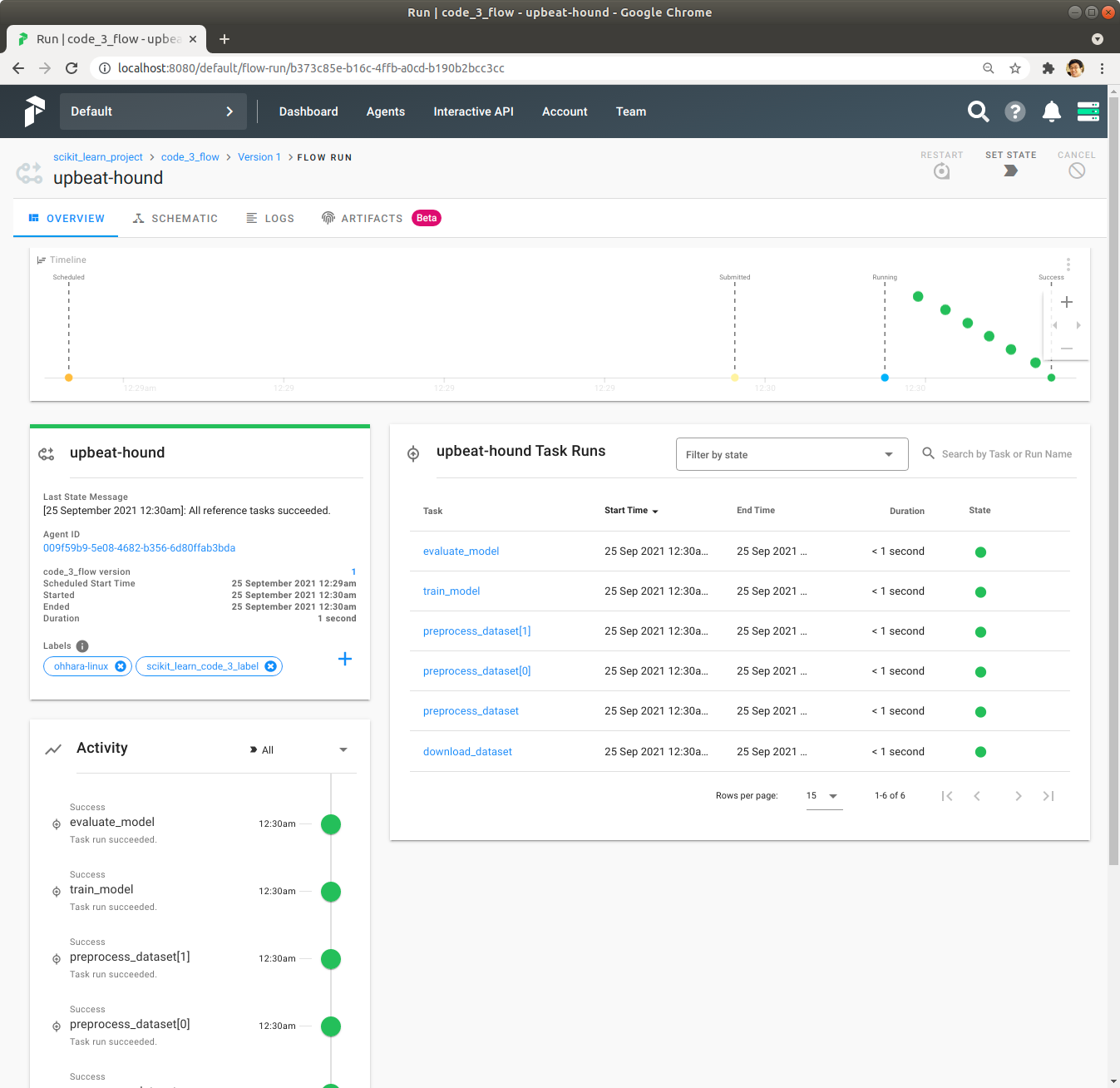
녹색 막대를 Click해서 각 Task의 실행시간 등 자세한 정보를 확인합니다.
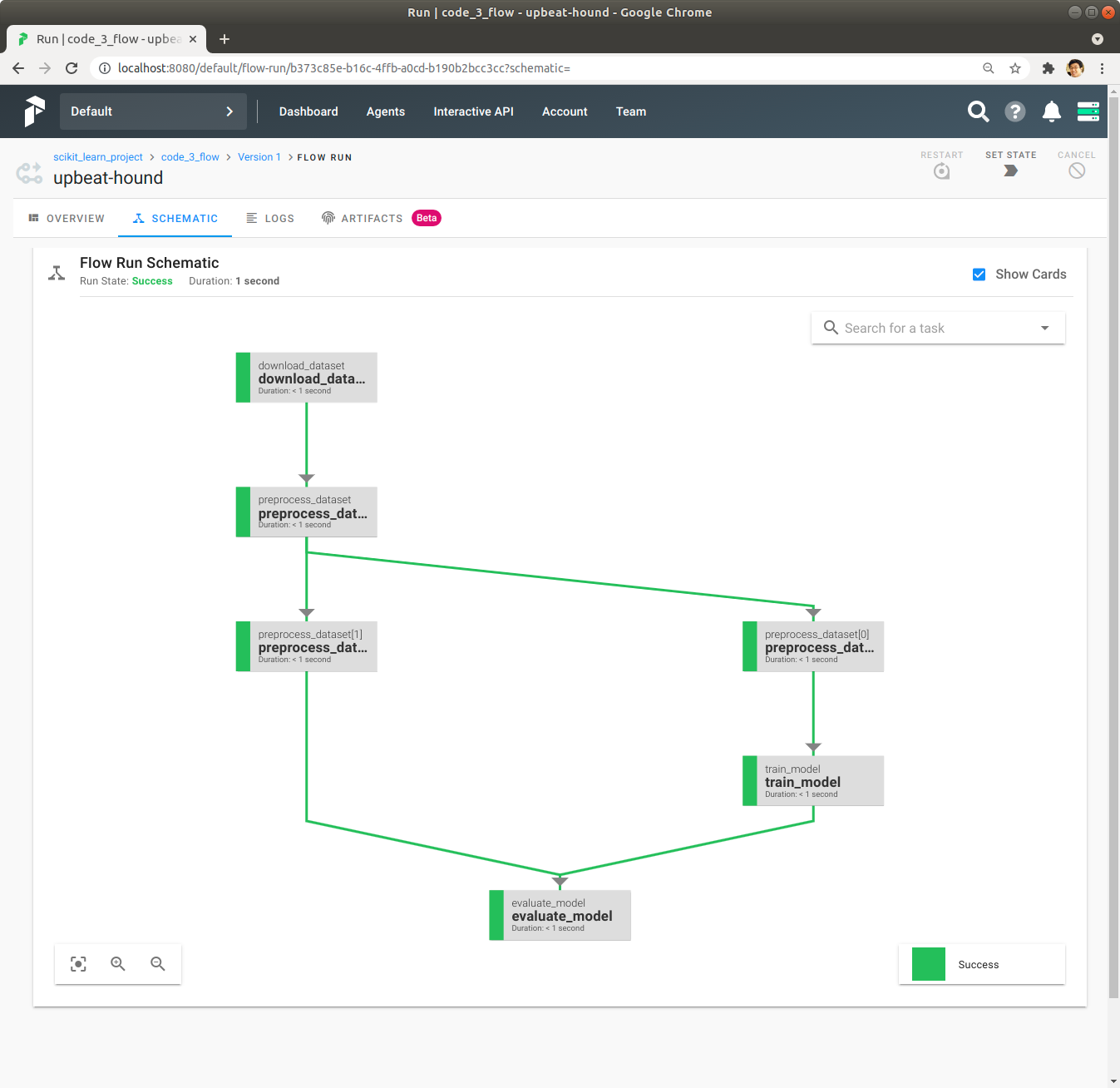
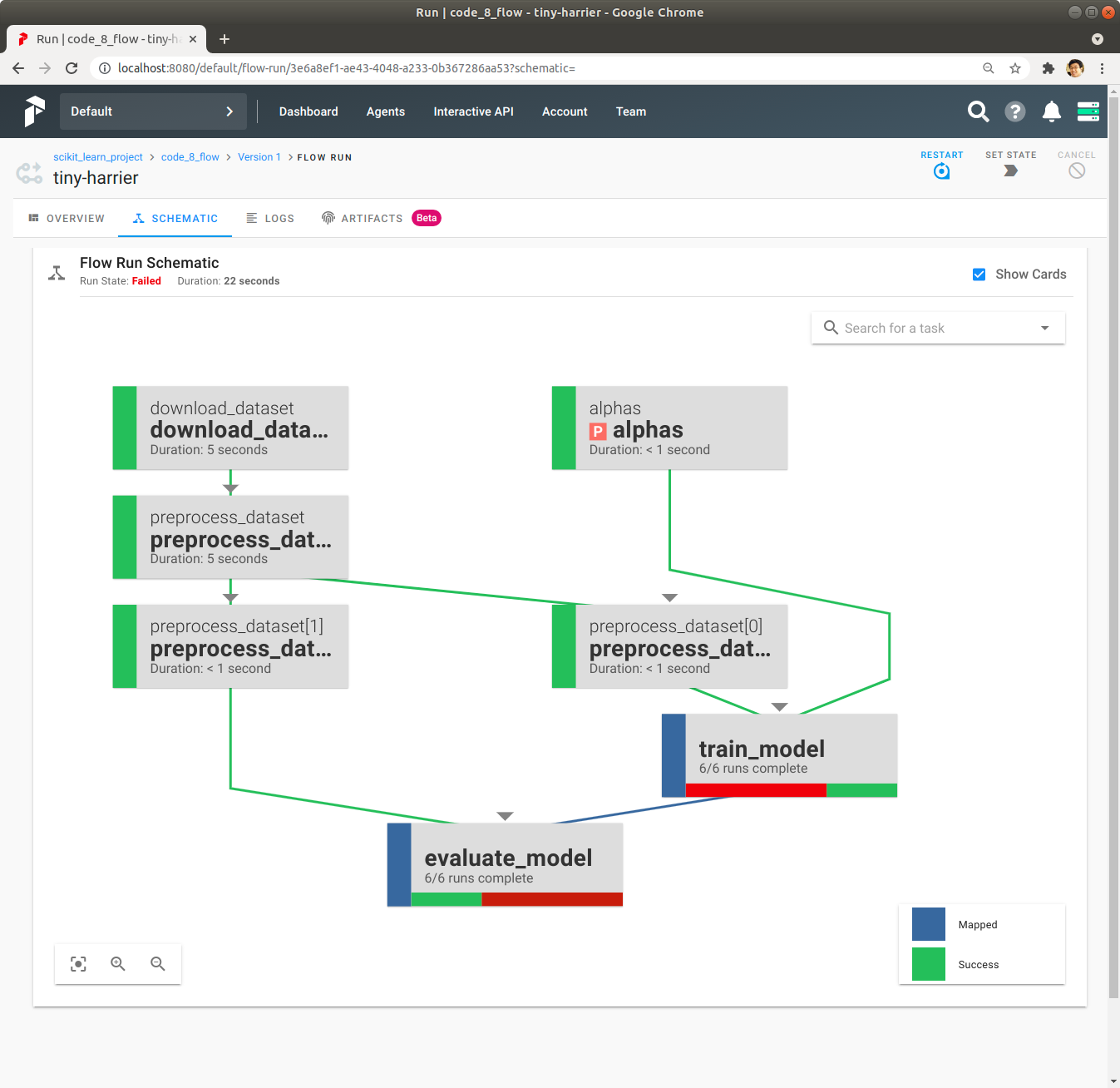
좌측 상단에 있는 Schematic을 Click하여 Task간의 Depepdency를 확인합니다. 각 Task가 실행되기 위해서는 어떤 Task들이 성공적으로 완료가 되어야 되는지 그림으로 확인할 수 있습니다.
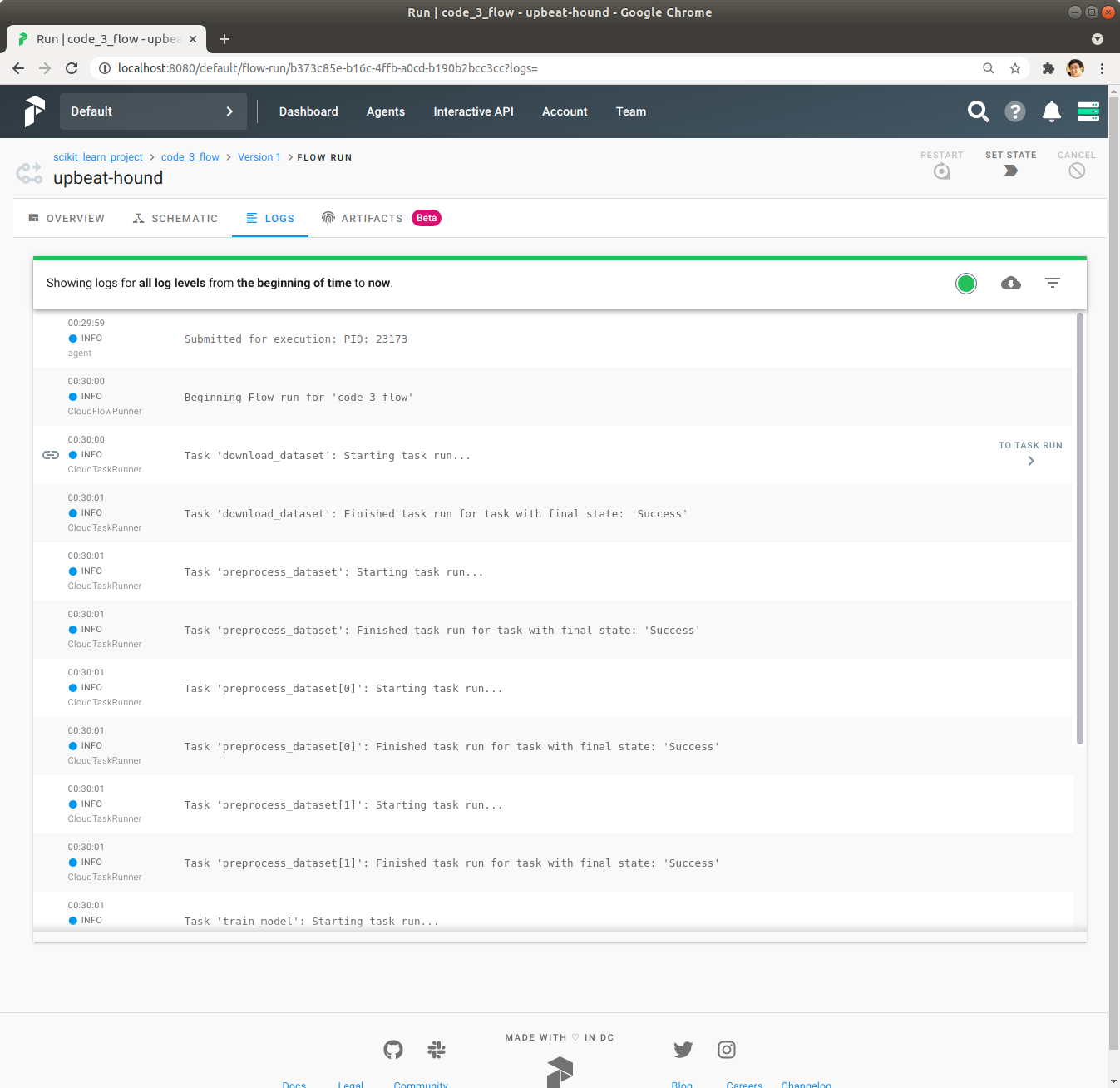
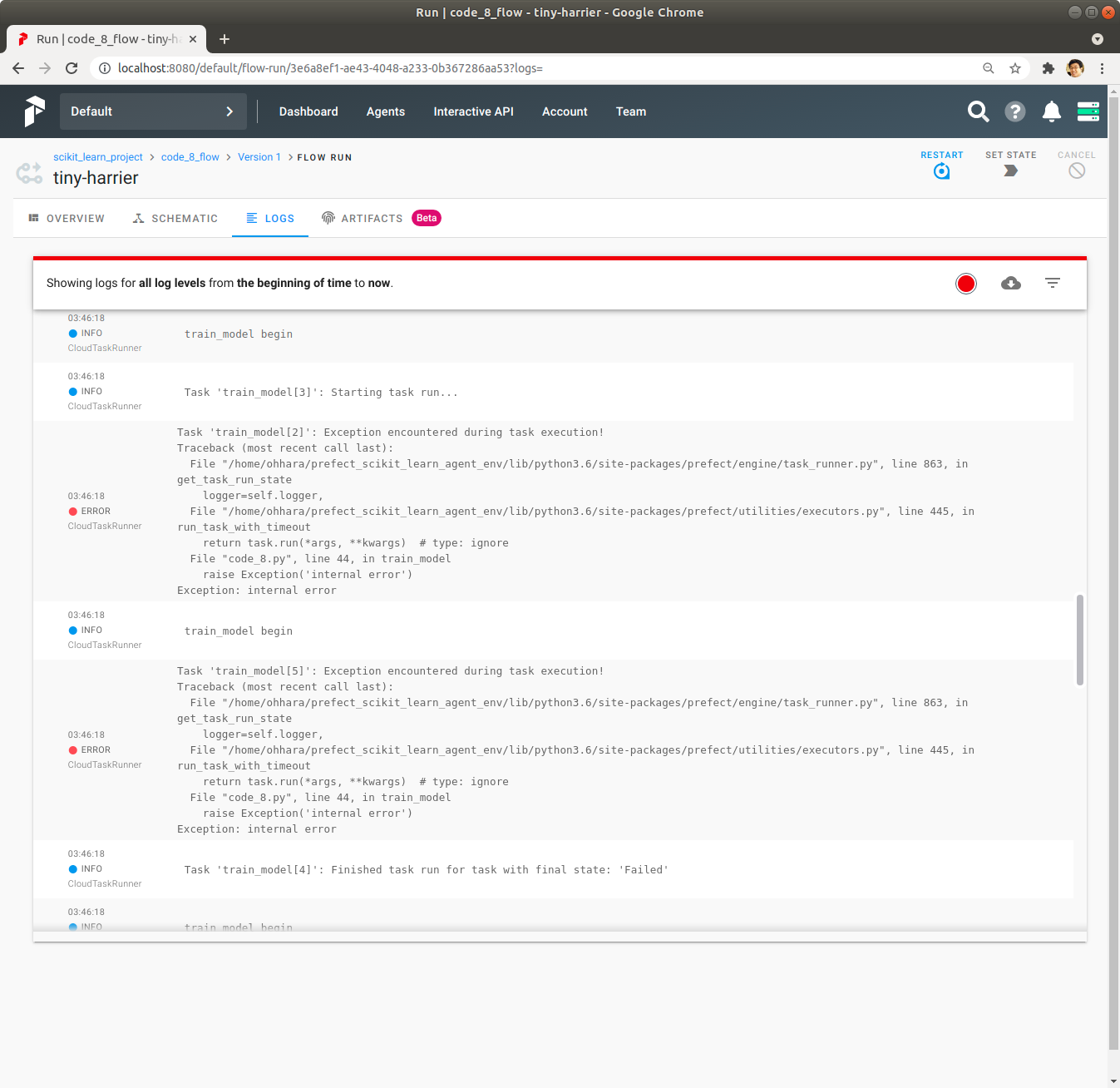
좌측 상단에 있는 Logs을 Click하여 Log를 확인합니다. Logs의 내용을 보면 print를 사용해서 출력한 내용은 확인이 불가능합니다.
Flow의 실행 후에 다음과 같이 Agent를 실행한 Directory를 확인해 보면 Code 2과 동일하게 정상적으로 실행되었습니다.
$ ls
code_3.py eval_model_train_dataset.txt test_dataset.csv
dataset.csv model_train_dataset.joblib train_dataset.csv
$ cat eval_model_train_dataset.txt
9.655153179853411816e-01
$
Code 4
from pathlib import Path
import numpy as np
from joblib import dump, load
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from prefect import task, Flow, Client
@task(log_stdout=True)
def download_dataset():
print('download_dataset begin')
dataset_filename = 'dataset.csv'
random_state = np.random.RandomState(seed=17)
a, b = random_state.uniform(-10, 10, 2)
x_data = random_state.uniform(-10, 10, size=100)
y_data = a * x_data + b + random_state.uniform(-10, 10, size=100)
dataset = np.column_stack((x_data, y_data))
np.savetxt(dataset_filename, dataset, delimiter=',')
print('download_dataset end')
return dataset_filename
@task(log_stdout=True)
def preprocess_dataset(dataset_filename):
print('preprocess_dataset begin')
train_dataset_filename = f'train_{dataset_filename}'
test_dataset_filename = f'test_{dataset_filename}'
dataset = np.loadtxt(dataset_filename, delimiter=',')
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, 0], dataset[:, 1], random_state=23)
train_dataset = np.column_stack((x_train, y_train))
test_dataset = np.column_stack((x_test, y_test))
np.savetxt(train_dataset_filename, train_dataset, delimiter=',')
np.savetxt(test_dataset_filename, test_dataset, delimiter=',')
print('preprocess_dataset end')
return train_dataset_filename, test_dataset_filename
@task(log_stdout=True)
def train_model(train_dataset_filename, alpha):
print('train_model begin')
model_filename = str(
Path(f'model_{alpha}_{train_dataset_filename}').with_suffix('.joblib'))
dataset = np.loadtxt(train_dataset_filename, delimiter=',')
model = Ridge(alpha=alpha).fit(dataset[:, 0:1], dataset[:, 1])
dump(model, model_filename)
print('train_model end')
return model_filename
@task(log_stdout=True)
def evaluate_model(model_filename, test_dataset_filename):
print('evaluate_model begin')
eval_model_filename = str(Path(f'eval_{model_filename}').with_suffix('.txt'))
model = load(model_filename)
dataset = np.loadtxt(test_dataset_filename, delimiter=',')
score = model.score(dataset[:, 0:1], dataset[:, 1])
np.savetxt(eval_model_filename, [score])
print('evaluate_model end')
return eval_model_filename
with Flow('code_4_flow') as flow:
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filename = train_model(train_test_dataset_filename[0], 1.0)
eval_model_filename = evaluate_model(
model_filename, train_test_dataset_filename[1])
print('dataset_filename', dataset_filename)
print('train_Test_dataset_filename', train_test_dataset_filename)
print('model_filename', model_filename)
print('eval_model_filename', eval_model_filename)
PROJECT_NAME = 'scikit_learn_project'
Client().create_project(project_name=PROJECT_NAME)
flow.register(project_name=PROJECT_NAME, labels=['scikit_learn_code_4_label'])
Code 3를 에서 Model을 LinearRegression을 사용했는데 Ridge로 변경하고 Hyperparameter인 alpha를 설정할 수 있도록 합니다. 주요 변경사항은 다음과 같습니다.
train_model에서LinearRegression대신에Ridge를 사용하고 Hyperparameter인alpha를 설정합니다.train_model에서 Model을 생성할 때alpha에 따라 다른 File에 저장합니다.train_modelTask를 Flow에서 호출할 때alpha를1.0으로 설정합니다.print로 출력하면 Prefect Server UI의 Logs에서 출력한 내용의 확인이 불가능해서,@task(log_stdout=True)로 Decorator를 변경하여,print를 사용해서 출력한 내용도 Prefect Server UI의 Logs에서 확인이 가능하도록 합니다.
이 Code의 실행을 위한 Agent는 다음과 같이 실행합니다. Agent는 한 개만 실행해 두고 여러 Flow가 공유해서 사용하는 것이 일반적이지만, 이 글에서는 쉬운 이해를 위해 Flow마다 별도의 Agent를 사용합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_4
$ cd ~/work/prefect_scikit_learn/code_4
$ prefect agent local start --api http://localhost:4200 --label scikit_learn_code_4_label
이 Code의 환경설정과 실행은 다음과 같이 합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_4
$ cd ~/work/prefect_scikit_learn/code_4
$ vi code_4.py
$ python code_4.py
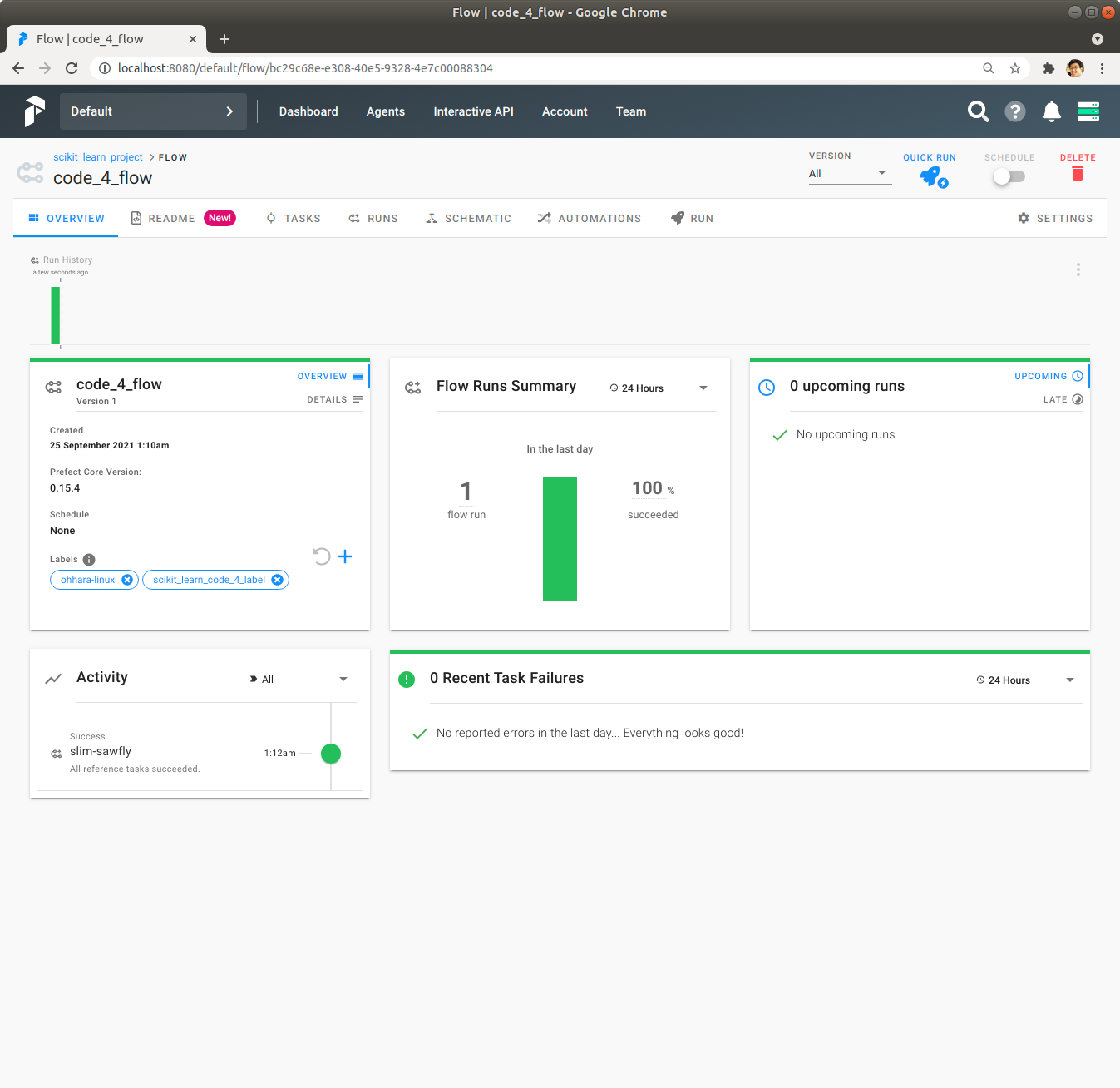
Prefect Server UI를 사용해서 code_4_flow Flow를 Quick Run을 Click하여 실행하여 실행이 성공적으로 완료된 것을 확인합니다.
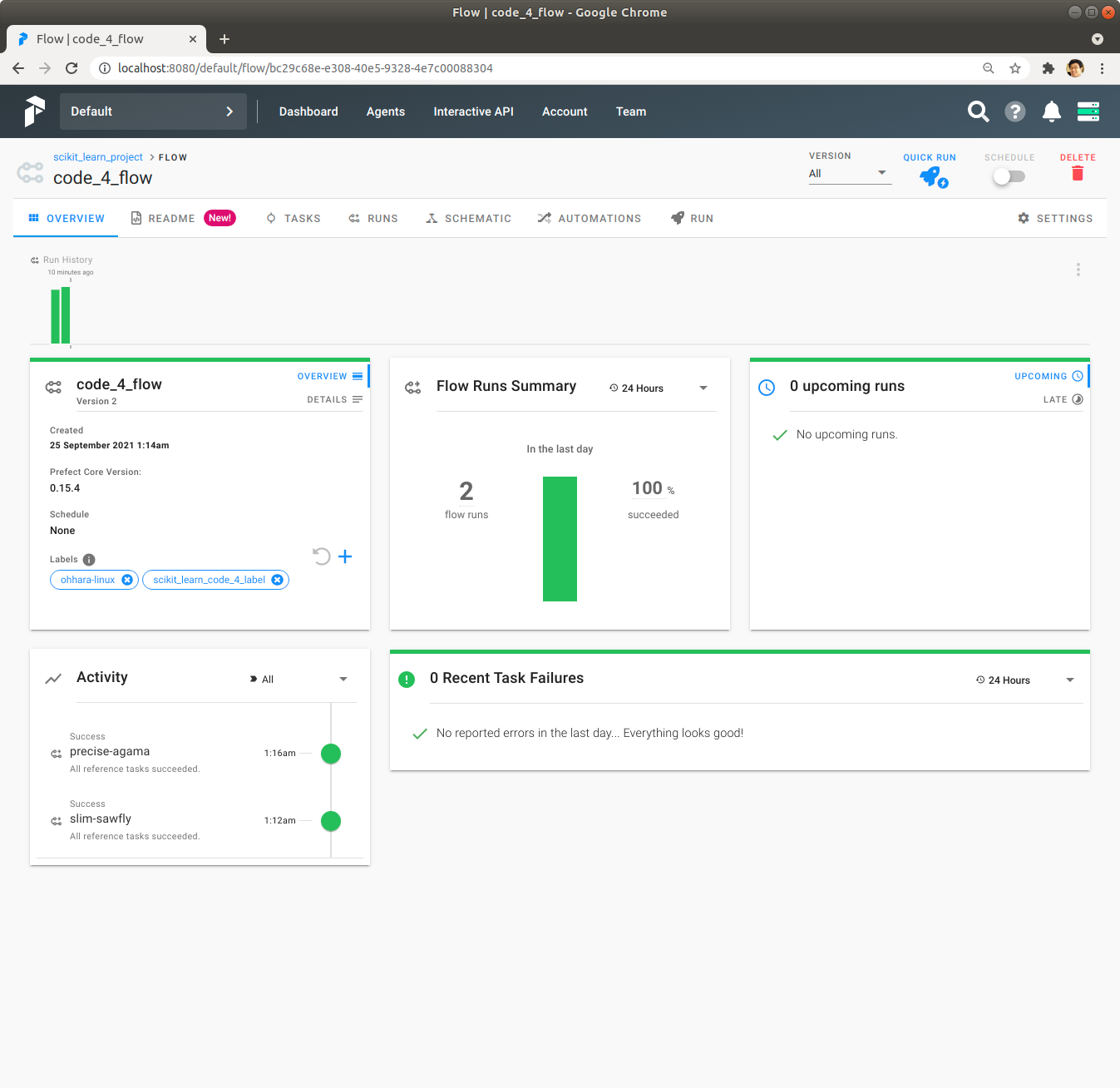
code_4.py에서 alpha를 1.0으로 설정하고 있는 부분을 0.1로 설정하도록 변경하고, 다시 python code_4.py를 실행하여 Prefect Server에 등록하고, Prefect Server UI에서 앞에서와 동일한 방법으로 code_4_flow Flow를 Quick Run을 Click하여 실행하여 실행이 성공적으로 완료된 것을 확인합니다. 여기서 좌측 중앙의 code_4_flow Flow의 정보를 살펴보면 이번 Flow실행은 이전 Flow실행과 다르게 Version 2의 code_4_flow Flow를 실행했다는 것을 확인할 수 있습니다. 이와 같이 Prefect에서는 Flow를 Prefect Server에 다시 등록하면, 자동으로 Version이 갱신되어, 같은 이름의 Flow가 실행되었더라도 다른 Version의 Flow가 실행되었다는 사실을 확인할 수 있습니다.
Flow를 alpha를 바꿔서 새로 등록해 가며 2번 실행한 후에 다음과 같이 Agent를 실행한 Directory에서 Flow가 2번 실행된 결과물을 확인합니다.
$ ls
code_4.py model_0.1_train_dataset.joblib
dataset.csv model_1.0_train_dataset.joblib
eval_model_0.1_train_dataset.txt test_dataset.csv
eval_model_1.0_train_dataset.txt train_dataset.csv
$
Code 5
from pathlib import Path
import numpy as np
from joblib import dump, load
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from prefect import task, Flow, Client, Parameter
@task(log_stdout=True)
def download_dataset():
print('download_dataset begin')
dataset_filename = 'dataset.csv'
random_state = np.random.RandomState(seed=17)
a, b = random_state.uniform(-10, 10, 2)
x_data = random_state.uniform(-10, 10, size=100)
y_data = a * x_data + b + random_state.uniform(-10, 10, size=100)
dataset = np.column_stack((x_data, y_data))
np.savetxt(dataset_filename, dataset, delimiter=',')
print('download_dataset end')
return dataset_filename
@task(log_stdout=True)
def preprocess_dataset(dataset_filename):
print('preprocess_dataset begin')
train_dataset_filename = f'train_{dataset_filename}'
test_dataset_filename = f'test_{dataset_filename}'
dataset = np.loadtxt(dataset_filename, delimiter=',')
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, 0], dataset[:, 1], random_state=23)
train_dataset = np.column_stack((x_train, y_train))
test_dataset = np.column_stack((x_test, y_test))
np.savetxt(train_dataset_filename, train_dataset, delimiter=',')
np.savetxt(test_dataset_filename, test_dataset, delimiter=',')
print('preprocess_dataset end')
return train_dataset_filename, test_dataset_filename
@task(log_stdout=True)
def train_model(train_dataset_filename, alpha):
print('train_model begin')
model_filename = str(
Path(f'model_{alpha}_{train_dataset_filename}').with_suffix('.joblib'))
dataset = np.loadtxt(train_dataset_filename, delimiter=',')
model = Ridge(alpha=alpha).fit(dataset[:, 0:1], dataset[:, 1])
dump(model, model_filename)
print('train_model end')
return model_filename
@task(log_stdout=True)
def evaluate_model(model_filename, test_dataset_filename):
print('evaluate_model begin')
eval_model_filename = str(Path(f'eval_{model_filename}').with_suffix('.txt'))
model = load(model_filename)
dataset = np.loadtxt(test_dataset_filename, delimiter=',')
score = model.score(dataset[:, 0:1], dataset[:, 1])
np.savetxt(eval_model_filename, [score])
print('evaluate_model end')
return eval_model_filename
with Flow('code_5_flow') as flow:
alpha = Parameter('alpha')
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filename = train_model(train_test_dataset_filename[0], alpha)
eval_model_filename = evaluate_model(
model_filename, train_test_dataset_filename[1])
print('dataset_filename', dataset_filename)
print('train_Test_dataset_filename', train_test_dataset_filename)
print('model_filename', model_filename)
print('eval_model_filename', eval_model_filename)
PROJECT_NAME = 'scikit_learn_project'
Client().create_project(project_name=PROJECT_NAME)
flow.register(project_name=PROJECT_NAME, labels=['scikit_learn_code_5_label'])
Code 4를 Prefect의 Parameter를 사용해서 Flow를 실행할 때 동적으로 변경이 가능하도록 하여 alpha를 변경할 때마다 Flow를 수정하지 Prefect Server에 등록하지 않아도 되도록 합니다. 주요 변경사항은 다음과 같습니다.
- Flow를 정의할 때
alpha = Parameter('alpha')와 같이 Prefect의 Parameter를 사용합니다.
이 Code의 실행을 위한 Agent는 다음과 같이 실행합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_5
$ cd ~/work/prefect_scikit_learn/code_5
$ prefect agent local start --api http://localhost:4200 --label scikit_learn_code_5_label
이 Code의 환경설정과 실행은 다음과 같이 합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_5
$ cd ~/work/prefect_scikit_learn/code_5
$ vi code_5.py
$ python code_5.py
Prefect Server UI에서 code_5_flow Flow를 살펴보면 Flow의 실행을 위해 alpha Parameter의 설정이 필요하기 때문에 Quick Run이 불가능하여 Quick Run Button이 비활성화되어 있습니다.
중앙 상단에 있는 Run을 Click합니다. alpha Parameter가 null로 설정되어 있습니다.
alpha Parameter를 0.01로 설정하고 Run을 Click하여 Flow를 실행합니다.
Agent를 실행한 Directory에서 alpha를 0.01로 설정하고 Flow를 실행한 결과물을 확인합니다.
$ ls
code_5.py eval_model_0.01_train_dataset.txt test_dataset.csv
dataset.csv model_0.01_train_dataset.joblib train_dataset.csv
$
Code 6
import time
from pathlib import Path
import numpy as np
from joblib import dump, load
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from prefect import task, Flow, Client, Parameter, unmapped
@task(log_stdout=True)
def download_dataset():
print('download_dataset begin')
dataset_filename = 'dataset.csv'
random_state = np.random.RandomState(seed=17)
a, b = random_state.uniform(-10, 10, 2)
x_data = random_state.uniform(-10, 10, size=100)
y_data = a * x_data + b + random_state.uniform(-10, 10, size=100)
dataset = np.column_stack((x_data, y_data))
np.savetxt(dataset_filename, dataset, delimiter=',')
time.sleep(5)
print('download_dataset end')
return dataset_filename
@task(log_stdout=True)
def preprocess_dataset(dataset_filename):
print('preprocess_dataset begin')
train_dataset_filename = f'train_{dataset_filename}'
test_dataset_filename = f'test_{dataset_filename}'
dataset = np.loadtxt(dataset_filename, delimiter=',')
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, 0], dataset[:, 1], random_state=23)
train_dataset = np.column_stack((x_train, y_train))
test_dataset = np.column_stack((x_test, y_test))
np.savetxt(train_dataset_filename, train_dataset, delimiter=',')
np.savetxt(test_dataset_filename, test_dataset, delimiter=',')
time.sleep(5)
print('preprocess_dataset end')
return train_dataset_filename, test_dataset_filename
@task(log_stdout=True)
def train_model(train_dataset_filename, alpha):
print('train_model begin')
model_filename = str(
Path(f'model_{alpha}_{train_dataset_filename}').with_suffix('.joblib'))
dataset = np.loadtxt(train_dataset_filename, delimiter=',')
model = Ridge(alpha=alpha).fit(dataset[:, 0:1], dataset[:, 1])
dump(model, model_filename)
time.sleep(5)
print('train_model end')
return model_filename
@task(log_stdout=True)
def evaluate_model(model_filename, test_dataset_filename):
print('evaluate_model begin')
eval_model_filename = str(Path(f'eval_{model_filename}').with_suffix('.txt'))
model = load(model_filename)
dataset = np.loadtxt(test_dataset_filename, delimiter=',')
score = model.score(dataset[:, 0:1], dataset[:, 1])
np.savetxt(eval_model_filename, [score])
time.sleep(5)
print('evaluate_model end')
return eval_model_filename
with Flow('code_6_flow') as flow:
alphas = Parameter('alphas')
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filenames = train_model.map(
unmapped(train_test_dataset_filename[0]), alphas)
eval_model_filenames = evaluate_model.map(
model_filenames, unmapped(train_test_dataset_filename[1]))
print('dataset_filename', dataset_filename)
print('train_Test_dataset_filename', train_test_dataset_filename)
print('model_filenames', model_filenames)
print('eval_model_filenames', eval_model_filenames)
PROJECT_NAME = 'scikit_learn_project'
Client().create_project(project_name=PROJECT_NAME)
flow.register(project_name=PROJECT_NAME, labels=['scikit_learn_code_6_label'])
Code 5에서 alpha Parameter대신에 alphas Parameter를 추가하여 Flow를 한 번 실행할 때 여러 alpha를 한 번에 설정해서할 수 있도록 합니다. 주요 변경사항은 다음과 같습니다.
time.sleep(5)를 사용해서 Task들의 실행 시간을 의도적으로 길게 하여 Task의 작동양상을 좀 더 자세히 살펴볼 수 있도록 합니다.alphasParameter로 여러alpha를 설정합니다.alphas는 Task에 넘길 때map으로 넘겨서alpha의 수만큼 Task를 병렬로 실행하도록 합니다.map을 사용해서 Task를 실행할 때, 실행되는 모든 Task에 같은 값을 전해주는 경우에는unmapped를 사용해서 전달합니다.
이 Code의 실행을 위한 Agent는 다음과 같이 실행합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_6
$ cd ~/work/prefect_scikit_learn/code_6
$ prefect agent local start --api http://localhost:4200 --label scikit_learn_code_6_label
이 Code의 환경설정과 실행은 다음과 같이 합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_6
$ cd ~/work/prefect_scikit_learn/code_6
$ vi code_6.py
$ python code_6.py
alphas Parameter를 [1.0, 0.1, 0.01, 0.001, 0.0001, 0.00001]와 같이 6개의 alpha를 한 번에 설정하고 Run을 Click하여 code_6_flow Flow를 실행합니다.
Task들이 map을 사용하여 실행되는 것을 확인합니다. map을 사용했지만 map을 사용한 Task가 의도와는 다르게 병렬로 실행되지 않고 순차적으로 실행되어서 실행시간이 오래 걸리는 것을 확인합니다. 실행시간은 중앙 좌측의 Duration에서 1분 13초인 것을 확인합니다.
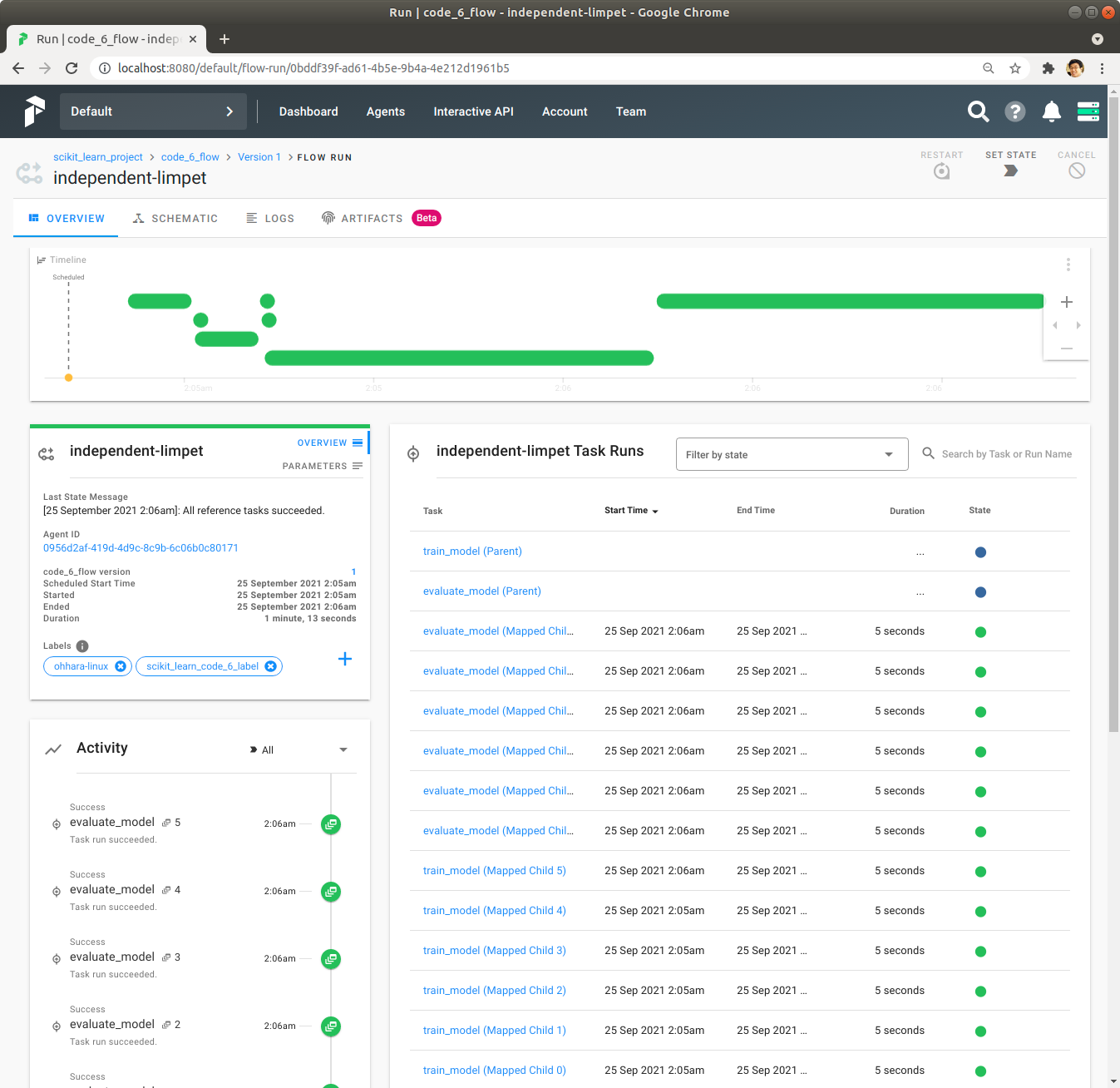
Agent를 실행한 Directory에서 alpha의 설정으로 Flow를 실행한 결과물을 확인합니다.
$ ls
code_6.py model_0.0001_train_dataset.joblib
dataset.csv model_0.001_train_dataset.joblib
eval_model_0.0001_train_dataset.txt model_0.01_train_dataset.joblib
eval_model_0.001_train_dataset.txt model_0.1_train_dataset.joblib
eval_model_0.01_train_dataset.txt model_1e-05_train_dataset.joblib
eval_model_0.1_train_dataset.txt model_1_train_dataset.joblib
eval_model_1e-05_train_dataset.txt test_dataset.csv
eval_model_1_train_dataset.txt train_dataset.csv
$
Code 7
import time
from pathlib import Path
import numpy as np
from joblib import dump, load
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from prefect import task, Flow, Client, Parameter, unmapped
from prefect.executors import LocalDaskExecutor
@task(log_stdout=True)
def download_dataset():
print('download_dataset begin')
dataset_filename = 'dataset.csv'
random_state = np.random.RandomState(seed=17)
a, b = random_state.uniform(-10, 10, 2)
x_data = random_state.uniform(-10, 10, size=100)
y_data = a * x_data + b + random_state.uniform(-10, 10, size=100)
dataset = np.column_stack((x_data, y_data))
np.savetxt(dataset_filename, dataset, delimiter=',')
time.sleep(5)
print('download_dataset end')
return dataset_filename
@task(log_stdout=True)
def preprocess_dataset(dataset_filename):
print('preprocess_dataset begin')
train_dataset_filename = f'train_{dataset_filename}'
test_dataset_filename = f'test_{dataset_filename}'
dataset = np.loadtxt(dataset_filename, delimiter=',')
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, 0], dataset[:, 1], random_state=23)
train_dataset = np.column_stack((x_train, y_train))
test_dataset = np.column_stack((x_test, y_test))
np.savetxt(train_dataset_filename, train_dataset, delimiter=',')
np.savetxt(test_dataset_filename, test_dataset, delimiter=',')
time.sleep(5)
print('preprocess_dataset end')
return train_dataset_filename, test_dataset_filename
@task(log_stdout=True)
def train_model(train_dataset_filename, alpha):
print('train_model begin')
model_filename = str(
Path(f'model_{alpha}_{train_dataset_filename}').with_suffix('.joblib'))
dataset = np.loadtxt(train_dataset_filename, delimiter=',')
model = Ridge(alpha=alpha).fit(dataset[:, 0:1], dataset[:, 1])
dump(model, model_filename)
time.sleep(5)
print('train_model end')
return model_filename
@task(log_stdout=True)
def evaluate_model(model_filename, test_dataset_filename):
print('evaluate_model begin')
eval_model_filename = str(Path(f'eval_{model_filename}').with_suffix('.txt'))
model = load(model_filename)
dataset = np.loadtxt(test_dataset_filename, delimiter=',')
score = model.score(dataset[:, 0:1], dataset[:, 1])
np.savetxt(eval_model_filename, [score])
time.sleep(5)
print('evaluate_model end')
return eval_model_filename
with Flow('code_7_flow', executor=LocalDaskExecutor()) as flow:
alphas = Parameter('alphas', default=[1.0, 0.1, 0.01, 0.001, 0.0001, 0.00001])
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filenames = train_model.map(
unmapped(train_test_dataset_filename[0]), alphas)
eval_model_filenames = evaluate_model.map(
model_filenames, unmapped(train_test_dataset_filename[1]))
print('dataset_filename', dataset_filename)
print('train_Test_dataset_filename', train_test_dataset_filename)
print('model_filenames', model_filenames)
print('eval_model_filenames', eval_model_filenames)
PROJECT_NAME = 'scikit_learn_project'
Client().create_project(project_name=PROJECT_NAME)
flow.register(project_name=PROJECT_NAME, labels=['scikit_learn_code_7_label'])
Code 6의 Executor를 변경하여 map을 좀 더 효율적으로 실행하도록 합니다. 주요 변경사항은 다음과 같습니다.
- Flow의 executor를
LocalDaskExecutor로 설정하여map을 순차적으로 실행하지 않고 병렬로 실행하도록 합니다.- Flow에
executor를 설정하지 않으면LocalExecutor가 사용되는데 이것은 Single Thread로 Task를 순차적으로 실행합니다.
- Flow에
alphasParameter에 Default값을[1.0, 0.1, 0.01, 0.001, 0.0001, 0.00001]로 설정하여alphasParameter를 설정하지 않더라도 Flow의 실행이 가능하도록 합니다.
이 Code의 실행을 위한 Agent는 다음과 같이 실행합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_7
$ cd ~/work/prefect_scikit_learn/code_7
$ prefect agent local start --api http://localhost:4200 --label scikit_learn_code_7_label
이 Code의 환경설정과 실행은 다음과 같이 합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_7
$ cd ~/work/prefect_scikit_learn/code_7
$ vi code_7.py
$ python code_7.py
alphas Parameter에 Default값을 설정했기 때문에, Prefect Server UI에서 code_7_flow Flow의 Quick Run Button이 활성화되어 있습니다.
Quick Run을 Click하여 code_7_flow Flow를 실행합니다. LocalDaskExecutor를 사용해서 Task들이 병렬로 실행되어서 실행시간이 22초로 대폭 줄었습니다.
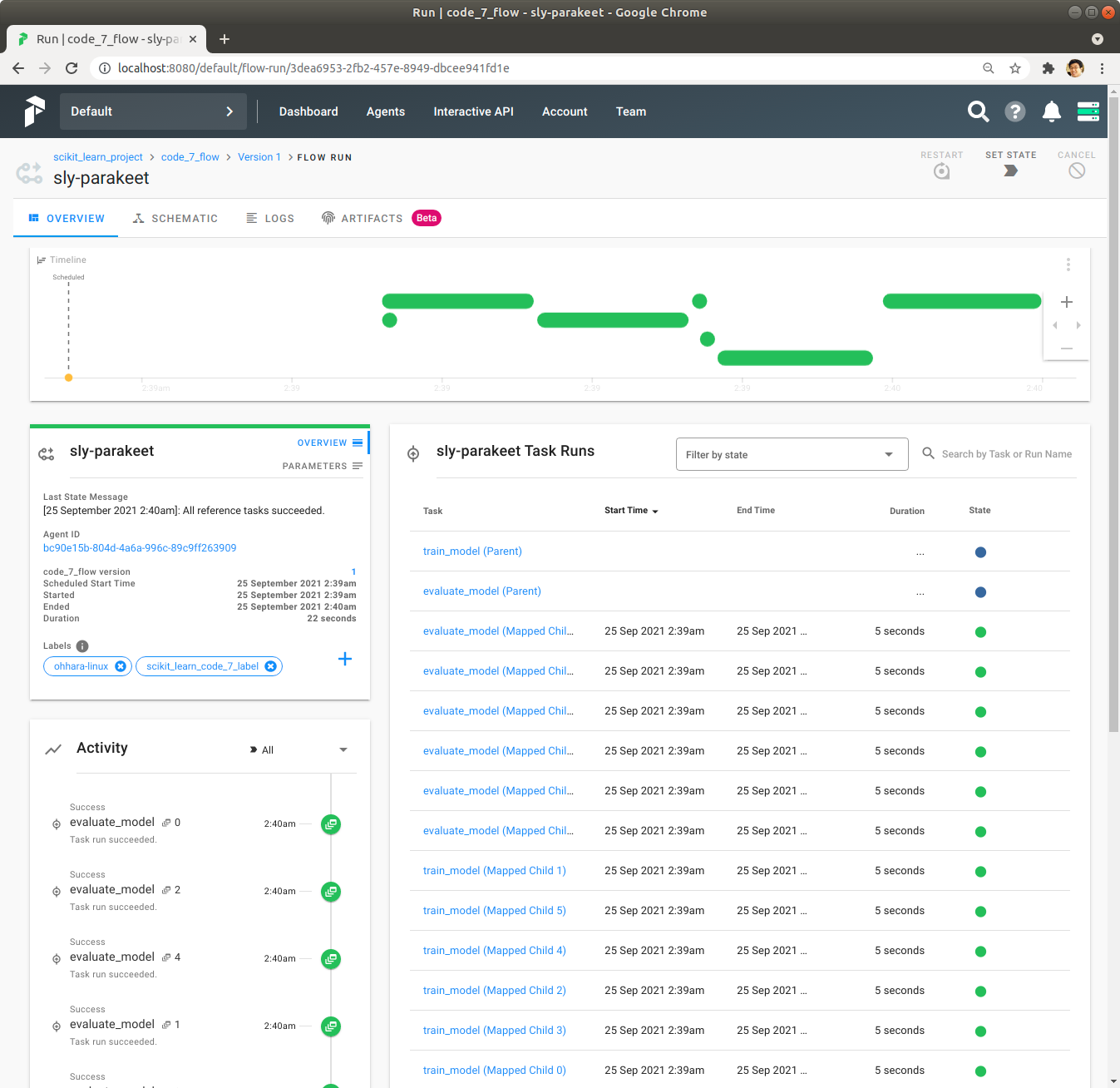
Agent를 실행한 Directory에서 Flow를 실행한 결과물을 확인합니다.
$ ls
code_7.py model_0.0001_train_dataset.joblib
dataset.csv model_0.001_train_dataset.joblib
eval_model_0.0001_train_dataset.txt model_0.01_train_dataset.joblib
eval_model_0.001_train_dataset.txt model_0.1_train_dataset.joblib
eval_model_0.01_train_dataset.txt model_1e-05_train_dataset.joblib
eval_model_0.1_train_dataset.txt model_1_train_dataset.joblib
eval_model_1e-05_train_dataset.txt test_dataset.csv
eval_model_1_train_dataset.txt train_dataset.csv
$
Code 8
import time
import random
from pathlib import Path
import numpy as np
from joblib import dump, load
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from prefect import task, Flow, Client, Parameter, unmapped
from prefect.executors import LocalDaskExecutor
@task(log_stdout=True)
def download_dataset():
print('download_dataset begin')
dataset_filename = 'dataset.csv'
random_state = np.random.RandomState(seed=17)
a, b = random_state.uniform(-10, 10, 2)
x_data = random_state.uniform(-10, 10, size=100)
y_data = a * x_data + b + random_state.uniform(-10, 10, size=100)
dataset = np.column_stack((x_data, y_data))
np.savetxt(dataset_filename, dataset, delimiter=',')
time.sleep(5)
print('download_dataset end')
return dataset_filename
@task(log_stdout=True)
def preprocess_dataset(dataset_filename):
print('preprocess_dataset begin')
train_dataset_filename = f'train_{dataset_filename}'
test_dataset_filename = f'test_{dataset_filename}'
dataset = np.loadtxt(dataset_filename, delimiter=',')
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, 0], dataset[:, 1], random_state=23)
train_dataset = np.column_stack((x_train, y_train))
test_dataset = np.column_stack((x_test, y_test))
np.savetxt(train_dataset_filename, train_dataset, delimiter=',')
np.savetxt(test_dataset_filename, test_dataset, delimiter=',')
time.sleep(5)
print('preprocess_dataset end')
return train_dataset_filename, test_dataset_filename
@task(log_stdout=True)
def train_model(train_dataset_filename, alpha):
print('train_model begin')
if random.random() < 0.5:
raise Exception('internal error')
model_filename = str(
Path(f'model_{alpha}_{train_dataset_filename}').with_suffix('.joblib'))
dataset = np.loadtxt(train_dataset_filename, delimiter=',')
model = Ridge(alpha=alpha).fit(dataset[:, 0:1], dataset[:, 1])
dump(model, model_filename)
time.sleep(5)
print('train_model end')
return model_filename
@task(log_stdout=True)
def evaluate_model(model_filename, test_dataset_filename):
print('evaluate_model begin')
eval_model_filename = str(Path(f'eval_{model_filename}').with_suffix('.txt'))
model = load(model_filename)
dataset = np.loadtxt(test_dataset_filename, delimiter=',')
score = model.score(dataset[:, 0:1], dataset[:, 1])
np.savetxt(eval_model_filename, [score])
time.sleep(5)
print('evaluate_model end')
return eval_model_filename
with Flow('code_8_flow', executor=LocalDaskExecutor()) as flow:
alphas = Parameter('alphas', default=[1.0, 0.1, 0.01, 0.001, 0.0001, 0.00001]);
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filenames = train_model.map(
unmapped(train_test_dataset_filename[0]), alphas)
eval_model_filenames = evaluate_model.map(
model_filenames, unmapped(train_test_dataset_filename[1]))
print('dataset_filename', dataset_filename)
print('train_Test_dataset_filename', train_test_dataset_filename)
print('model_filenames', model_filenames)
print('eval_model_filenames', eval_model_filenames)
PROJECT_NAME = 'scikit_learn_project'
Client().create_project(project_name=PROJECT_NAME)
flow.register(project_name=PROJECT_NAME, labels=['scikit_learn_code_8_label'])
Code 7에서 train_model이 Random하게 실패하도록 하여 Resource부족으로 가끔 실패하는 것과 같은 상황을 만듭니다. 주요 변경사항은 다음과 같습니다.
train_model에서 Random하게 50%의 확률로 Exception을 Raise합니다.
이 Code의 실행을 위한 Agent는 다음과 같이 실행합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_8
$ cd ~/work/prefect_scikit_learn/code_8
$ prefect agent local start --api http://localhost:4200 --label scikit_learn_code_8_label
이 Code의 환경설정과 실행은 다음과 같이 합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_8
$ cd ~/work/prefect_scikit_learn/code_8
$ vi code_8.py
$ python code_8.py
Prefect Server UI를 사용해서 code_8_flow Flow를 실행하면 잠시 후에 Flow의 실행이 실패했다는 표시로 빨간색 막대가 표시됩니다.
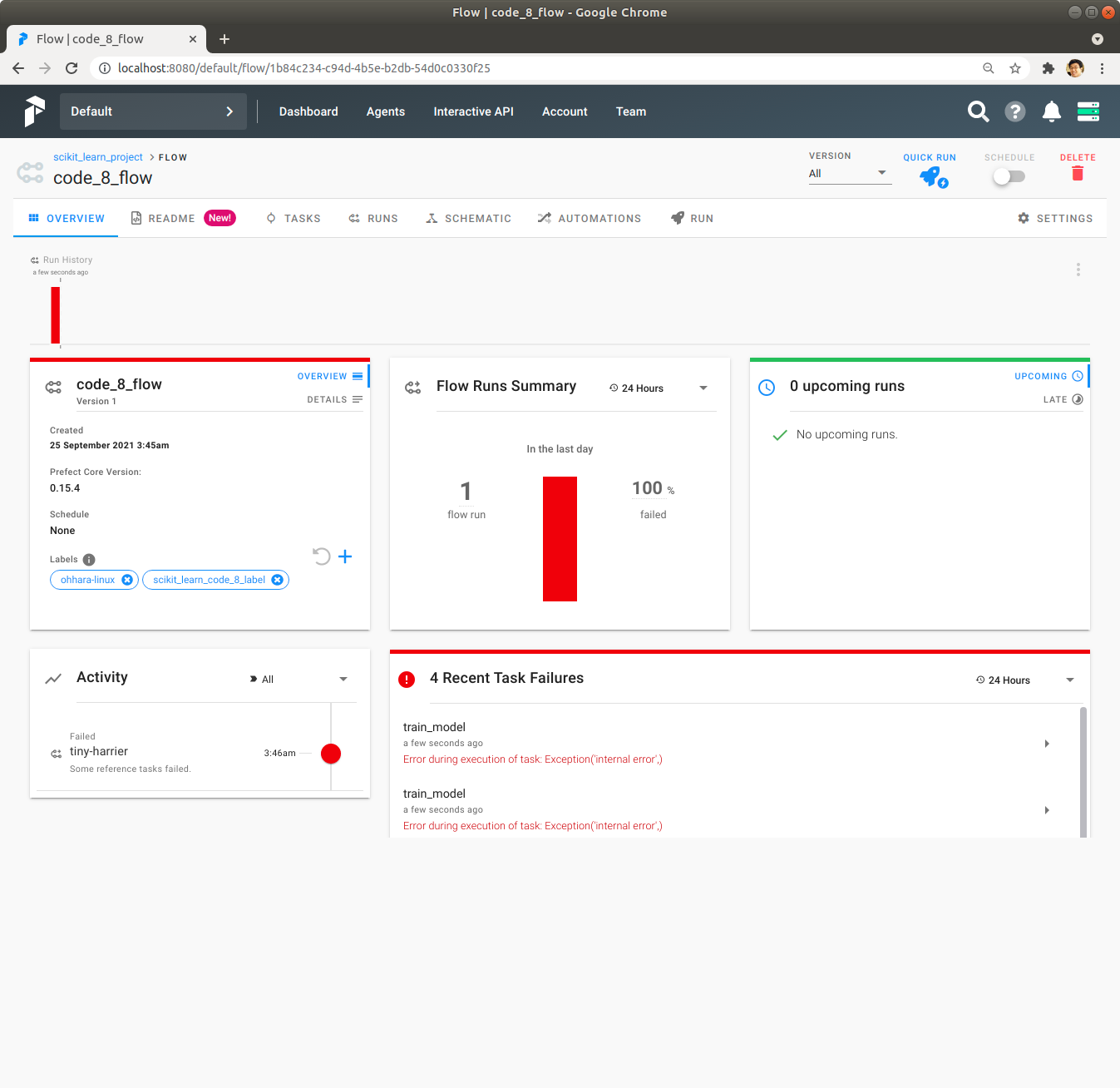
빨간색 막대를 Click해 보면 train_model을 map을 통해서 6번 실행했는데 그 중에 2번 성공하고 4번 실패한 것이 보입니다. 그리고 일부 train_model이 실패해서 일부 evaluate_model은 실행을 시작하지 못하고 실패로 처리되었습니다.
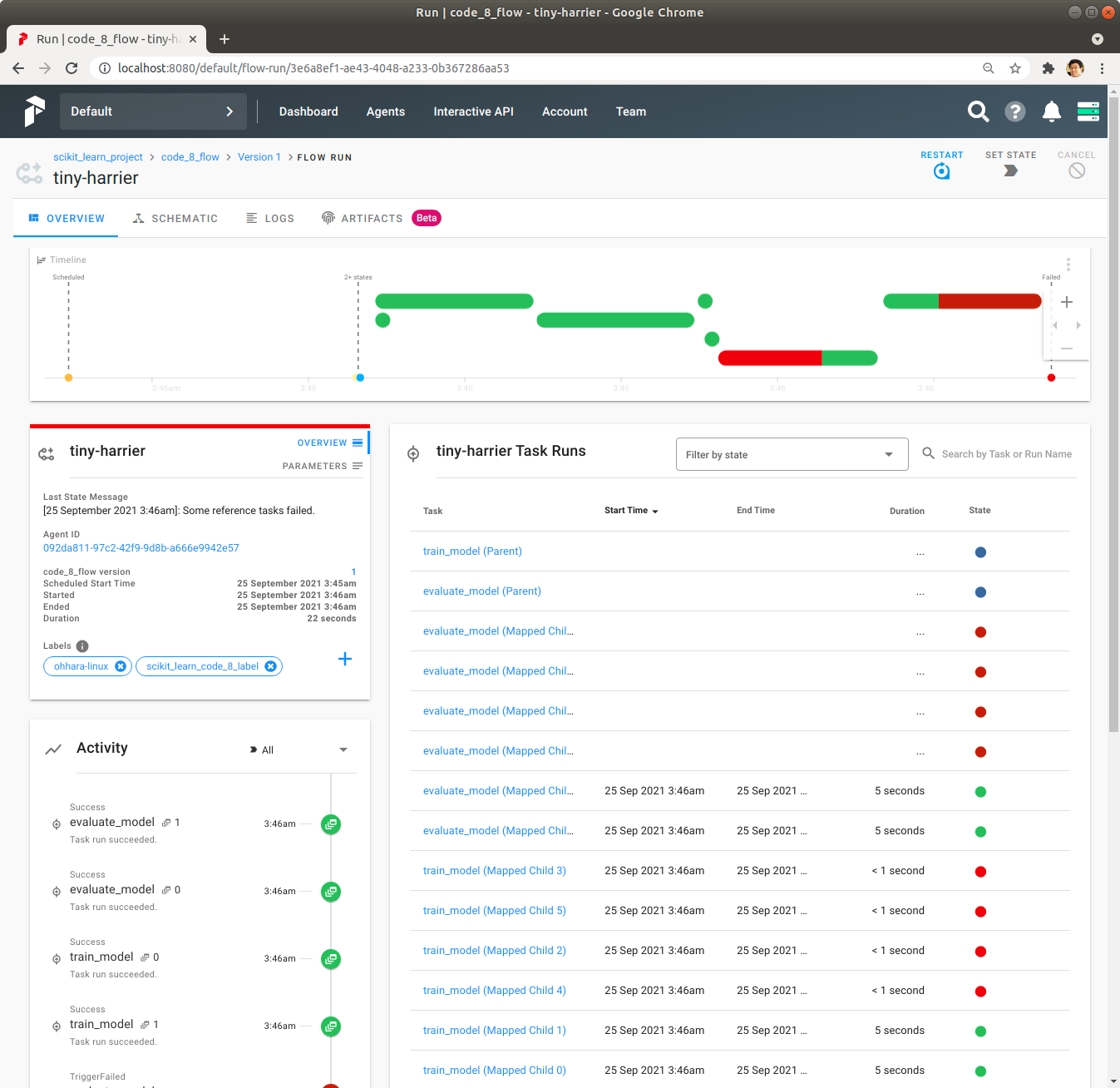
Schematic을 통해서 실패 내용을 확인합니다.
Logs를 통해서 실패 내용을 확인합니다.
오른쪽 상단에 있는 Restart를 Click하여 Flow를 재실행합니다. 이 때, Prefect Server는 실패했던 Task의 Input을 저장해 놨다가 동일하게 Input을 Task에 전달해서 실행합니다. 성공했던 Task는 재실행하지 않습니다. 재실행으로 이전에 실패했던 Task일부가 성공한 것을 확인합니다.
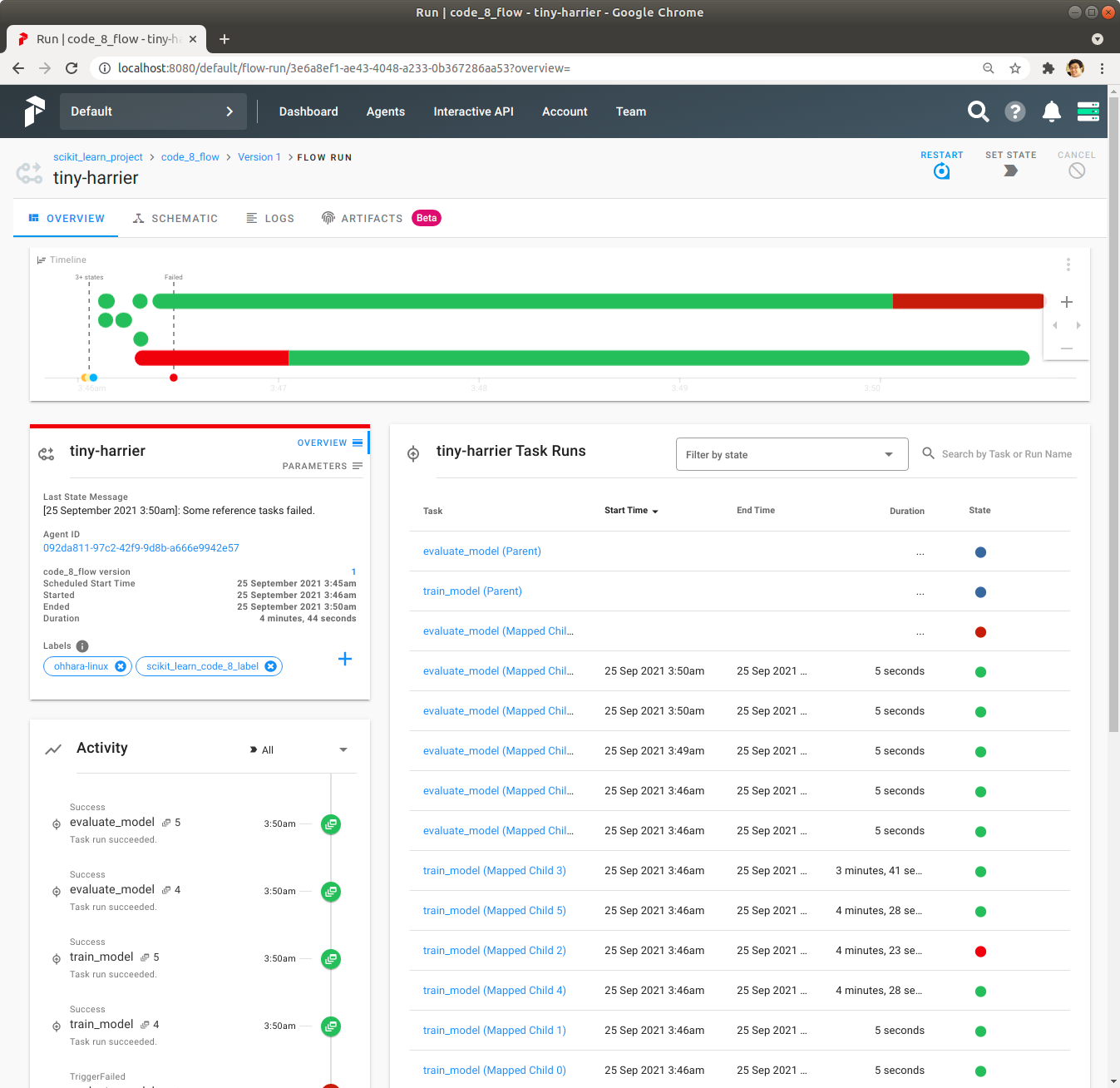
또 Restart를 Click하여 Flow가 성공적으로 종료된 것을 확인합니다.
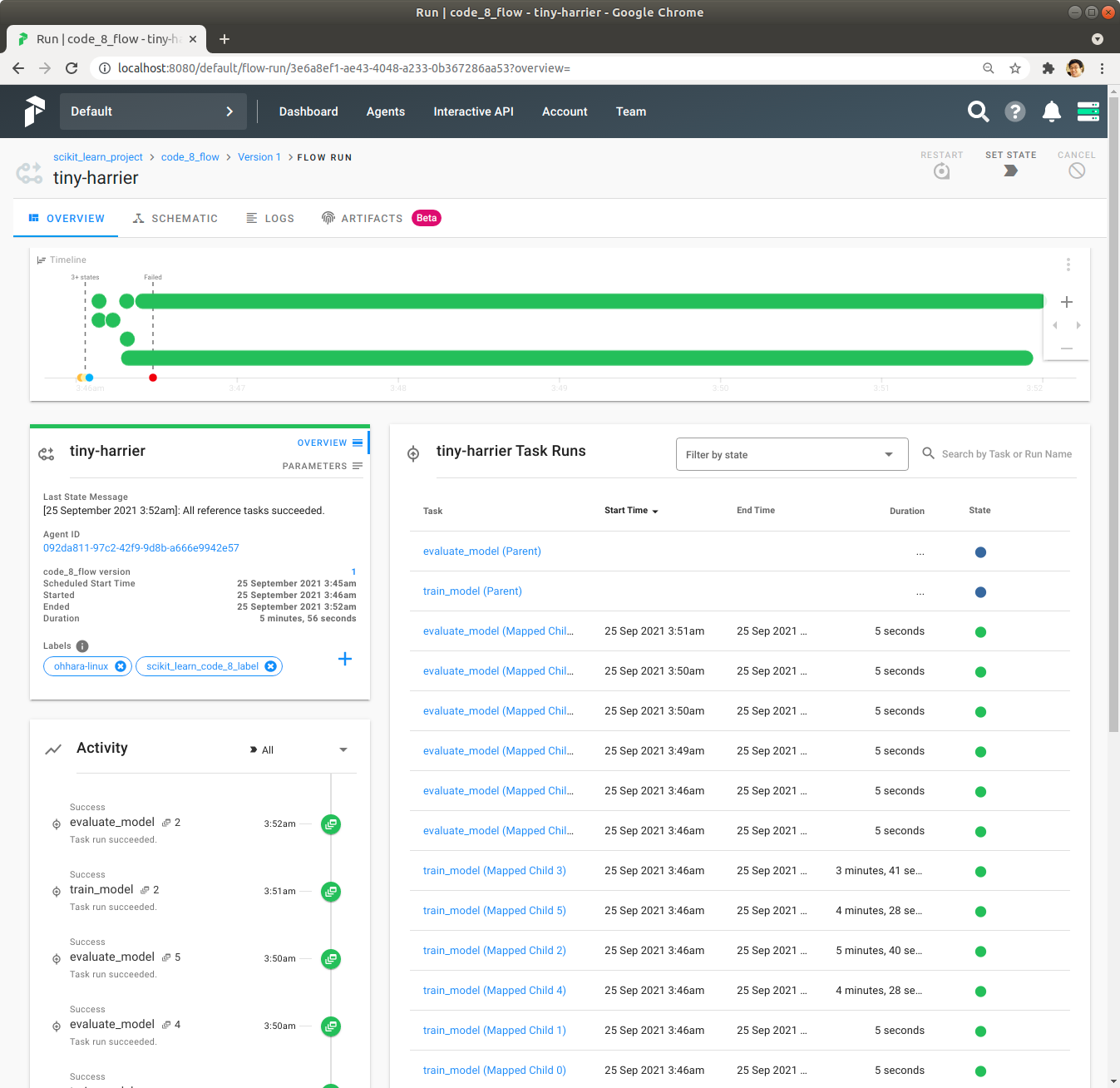
Agent를 실행한 Directory에서 Flow를 실행한 결과물을 확인합니다.
$ ls
code_8.py model_0.0001_train_dataset.joblib
dataset.csv model_0.001_train_dataset.joblib
eval_model_0.0001_train_dataset.txt model_0.01_train_dataset.joblib
eval_model_0.001_train_dataset.txt model_0.1_train_dataset.joblib
eval_model_0.01_train_dataset.txt model_1e-05_train_dataset.joblib
eval_model_0.1_train_dataset.txt model_1_train_dataset.joblib
eval_model_1e-05_train_dataset.txt test_dataset.csv
eval_model_1_train_dataset.txt train_dataset.csv
$
Code 9
import time
from pathlib import Path
import numpy as np
from joblib import dump, load
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from prefect import task, Flow, Client, Parameter, unmapped, flatten
from prefect.executors import LocalDaskExecutor
@task(log_stdout=True)
def download_dataset():
print('download_dataset begin')
dataset_filename = 'dataset.csv'
random_state = np.random.RandomState(seed=17)
a, b = random_state.uniform(-10, 10, 2)
x_data = random_state.uniform(-10, 10, size=100)
y_data = a * x_data + b + random_state.uniform(-10, 10, size=100)
dataset = np.column_stack((x_data, y_data))
np.savetxt(dataset_filename, dataset, delimiter=',')
time.sleep(5)
print('download_dataset end')
return dataset_filename
@task(log_stdout=True)
def preprocess_dataset(dataset_filename):
print('preprocess_dataset begin')
train_dataset_filename = f'train_{dataset_filename}'
test_dataset_filename = f'test_{dataset_filename}'
dataset = np.loadtxt(dataset_filename, delimiter=',')
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, 0], dataset[:, 1], random_state=23)
train_dataset = np.column_stack((x_train, y_train))
test_dataset = np.column_stack((x_test, y_test))
np.savetxt(train_dataset_filename, train_dataset, delimiter=',')
np.savetxt(test_dataset_filename, test_dataset, delimiter=',')
time.sleep(5)
print('preprocess_dataset end')
return train_dataset_filename, test_dataset_filename
@task(log_stdout=True)
def train_model(train_dataset_filename, alpha):
print('train_model begin')
model_filename = str(
Path(f'model_{alpha}_{train_dataset_filename}').with_suffix('.joblib'))
dataset = np.loadtxt(train_dataset_filename, delimiter=',')
model = Ridge(alpha=alpha).fit(dataset[:, 0:1], dataset[:, 1])
dump(model, model_filename)
time.sleep(5)
print('train_model end')
return model_filename
@task(log_stdout=True)
def evaluate_model(model_filename, test_dataset_filename):
print('evaluate_model begin')
eval_model_filename = str(Path(f'eval_{model_filename}').with_suffix('.txt'))
model = load(model_filename)
dataset = np.loadtxt(test_dataset_filename, delimiter=',')
score = model.score(dataset[:, 0:1], dataset[:, 1])
np.savetxt(eval_model_filename, [score])
time.sleep(5)
print('evaluate_model end')
return eval_model_filename
@task(log_stdout=True)
def cleanup_file(filename):
print('cleanup_dataset begin')
Path(filename).unlink()
time.sleep(5)
print('cleanup_dataset begin')
with Flow('code_9_flow', executor=LocalDaskExecutor()) as flow:
alphas = Parameter('alphas', default=[1.0, 0.1, 0.01, 0.001, 0.0001, 0.00001]);
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filenames = train_model.map(
unmapped(train_test_dataset_filename[0]), alphas)
eval_model_filenames = evaluate_model.map(
model_filenames, unmapped(train_test_dataset_filename[1]))
cleanup_files = cleanup_file.map(
flatten([[dataset_filename], model_filenames, train_test_dataset_filename]))
cleanup_files.set_upstream(eval_model_filenames)
print('dataset_filename', dataset_filename)
print('train_Test_dataset_filename', train_test_dataset_filename)
print('model_filenames', model_filenames)
print('eval_model_filenames', eval_model_filenames)
PROJECT_NAME = 'scikit_learn_project'
Client().create_project(project_name=PROJECT_NAME)
flow.register(project_name=PROJECT_NAME, labels=['scikit_learn_code_9_label'])
Code 7에 중간 생성 결과물을 Flow실행이 끝나면 삭제하도록 합니다. 주요 변경사항은 다음과 같습니다.
cleanup_fileTask를 추가합니다.evaluate_modelTask의 결과물만 남기고 나머지 중간에 생성된 File들은cleanup_file에map을 사용해서 삭제하도록 Flow에 추가합니다.set_upstream을 사용해서eval_model_filenames이 완료된 후에cleanup_file을 실행하도록 지정해 줍니다. 이렇게 해 주지 않으면cleanup_file에 전달되는dataset_filename,model_filenames,train_test_dataset_filename이 완료된 후에cleanup_file이 실행되게 되어evaluate_model과cleanup_file이 동시에 실행되게 되어cleanup_fileTask가 오작동할 수 있습니다.map의 결과물을 가지고 또map을 사용하면 List의 List를 다뤄야 해서 불편하므로flatten을 사용해서 List의 List를 List로 변환합니다.
이 Code의 실행을 위한 Agent는 다음과 같이 실행합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_9
$ cd ~/work/prefect_scikit_learn/code_9
$ prefect agent local start --api http://localhost:4200 --label scikit_learn_code_9_label
이 Code의 환경설정과 실행은 다음과 같이 합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_9
$ cd ~/work/prefect_scikit_learn/code_9
$ vi code_9.py
$ python code_9.py
Prefect Server UI를 통해 code_9_flow Flow를 실행하고 cleanup_file Task도 잘 실행되었는지 확인합니다.
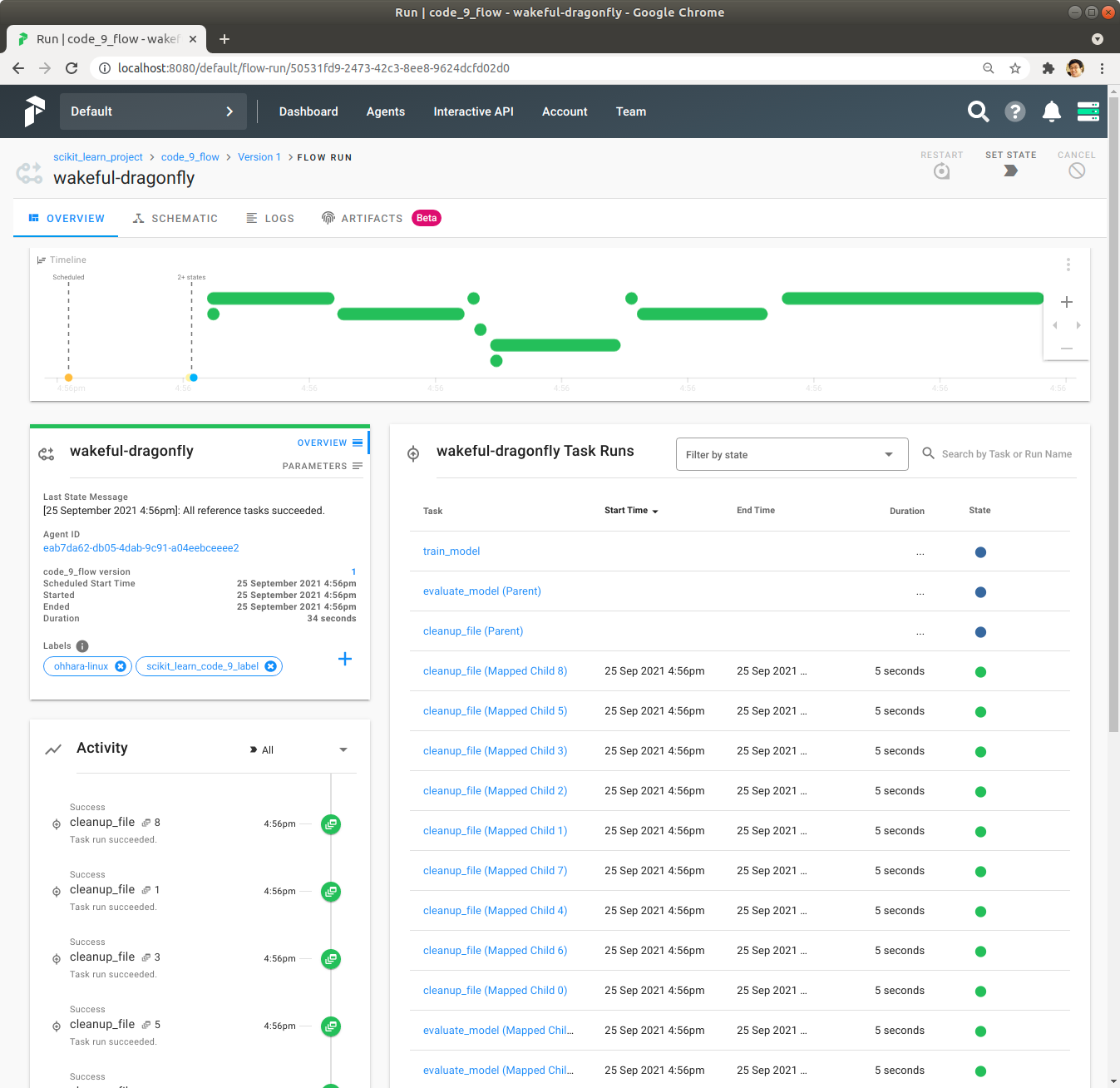
Schematic을 통해서 cleanup_file Task가 evaluate_model Task다음에 실행이 되도록 Dependency가 잘 설정되어 있는지 확인합니다.
Agent를 실행한 Directory에서 Flow를 실행한 결과물을 확인합니다. evaluate_model Task의 결과물만 남고 나머지는 모두 삭제된 것을 확인합니다.
$ ls
code_9.py eval_model_0.1_train_dataset.txt
eval_model_0.0001_train_dataset.txt eval_model_1.0_train_dataset.txt
eval_model_0.001_train_dataset.txt eval_model_1e-05_train_dataset.txt
eval_model_0.01_train_dataset.txt
$
Code 10
import time
from pathlib import Path
import numpy as np
from joblib import dump, load
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
import prefect
from prefect import task, Flow, Client, Parameter, unmapped, flatten
from prefect.executors import LocalDaskExecutor
from prefect.schedules import CronSchedule
@task(log_stdout=True)
def download_dataset():
print('download_dataset begin')
dt = prefect.context.get('scheduled_start_time')
print('scheduled_start_time', dt)
seed = int(dt.timestamp())
print('seed', seed)
dataset_filename = f'dataset_{dt.format("YYYYMMDDHHmmss")}.csv'
random_state = np.random.RandomState(seed=seed)
a, b = random_state.uniform(-10, 10, 2)
x_data = random_state.uniform(-10, 10, size=100)
y_data = a * x_data + b + random_state.uniform(-10, 10, size=100)
dataset = np.column_stack((x_data, y_data))
np.savetxt(dataset_filename, dataset, delimiter=',')
time.sleep(5)
print('download_dataset end')
return dataset_filename
@task(log_stdout=True)
def preprocess_dataset(dataset_filename):
print('preprocess_dataset begin')
train_dataset_filename = f'train_{dataset_filename}'
test_dataset_filename = f'test_{dataset_filename}'
dataset = np.loadtxt(dataset_filename, delimiter=',')
x_train, x_test, y_train, y_test = train_test_split(
dataset[:, 0], dataset[:, 1], random_state=23)
train_dataset = np.column_stack((x_train, y_train))
test_dataset = np.column_stack((x_test, y_test))
np.savetxt(train_dataset_filename, train_dataset, delimiter=',')
np.savetxt(test_dataset_filename, test_dataset, delimiter=',')
time.sleep(5)
print('preprocess_dataset end')
return train_dataset_filename, test_dataset_filename
@task(log_stdout=True)
def train_model(train_dataset_filename, alpha):
print('train_model begin')
model_filename = str(
Path(f'model_{alpha}_{train_dataset_filename}').with_suffix('.joblib'))
dataset = np.loadtxt(train_dataset_filename, delimiter=',')
model = Ridge(alpha=alpha).fit(dataset[:, 0:1], dataset[:, 1])
dump(model, model_filename)
time.sleep(5)
print('train_model end')
return model_filename
@task(log_stdout=True)
def evaluate_model(model_filename, test_dataset_filename):
print('evaluate_model begin')
eval_model_filename = str(Path(f'eval_{model_filename}').with_suffix('.txt'))
model = load(model_filename)
dataset = np.loadtxt(test_dataset_filename, delimiter=',')
score = model.score(dataset[:, 0:1], dataset[:, 1])
np.savetxt(eval_model_filename, [score])
time.sleep(5)
print('evaluate_model end')
return eval_model_filename
@task(log_stdout=True)
def cleanup_file(filename):
print('cleanup_dataset begin')
Path(filename).unlink()
time.sleep(5)
print('cleanup_dataset begin')
with Flow('code_10_flow', executor=LocalDaskExecutor(),
schedule=CronSchedule('*/1 * * * *')) as flow:
alphas = Parameter('alphas', default=[1.0, 0.1, 0.01, 0.001, 0.0001, 0.00001]);
dataset_filename = download_dataset()
train_test_dataset_filename = preprocess_dataset(dataset_filename)
model_filenames = train_model.map(
unmapped(train_test_dataset_filename[0]), alphas)
eval_model_filenames = evaluate_model.map(
model_filenames, unmapped(train_test_dataset_filename[1]))
cleanup_files = cleanup_file.map(
flatten([[dataset_filename], model_filenames, train_test_dataset_filename]))
cleanup_files.set_upstream(eval_model_filenames)
print('dataset_filename', dataset_filename)
print('train_Test_dataset_filename', train_test_dataset_filename)
print('model_filenames', model_filenames)
print('eval_model_filenames', eval_model_filenames)
PROJECT_NAME = 'scikit_learn_project'
Client().create_project(project_name=PROJECT_NAME)
flow.register(project_name=PROJECT_NAME, labels=['scikit_learn_code_10_label'])
Code 9를 1분에 한 번씩 주기적으로 실행하도록 합니다. 주요 변경사항은 다음과 같습니다.
download_dataset이 Flow가 Schedule된 시간을 기준으로 다른 Dataset을 생성하고 이때 저장되는 File명에도 시간 정보를 추가합니다.- Flow를 생성할 때
schedule을CronSchedule('*/1 * * * *')로 설정해서 Flow가 1분마다 실행되도록 합니다.
이 Code의 실행을 위한 Agent는 다음과 같이 실행합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_10
$ cd ~/work/prefect_scikit_learn/code_10
$ prefect agent local start --api http://localhost:4200 --label scikit_learn_code_10_label
이 Code의 환경설정과 실행은 다음과 같이 합니다.
$ source ~/prefect_scikit_learn_agent_env/bin/activate
$ mkdir -p ~/work/prefect_scikit_learn/code_10
$ cd ~/work/prefect_scikit_learn/code_10
$ vi code_10.py
$ python code_10.py
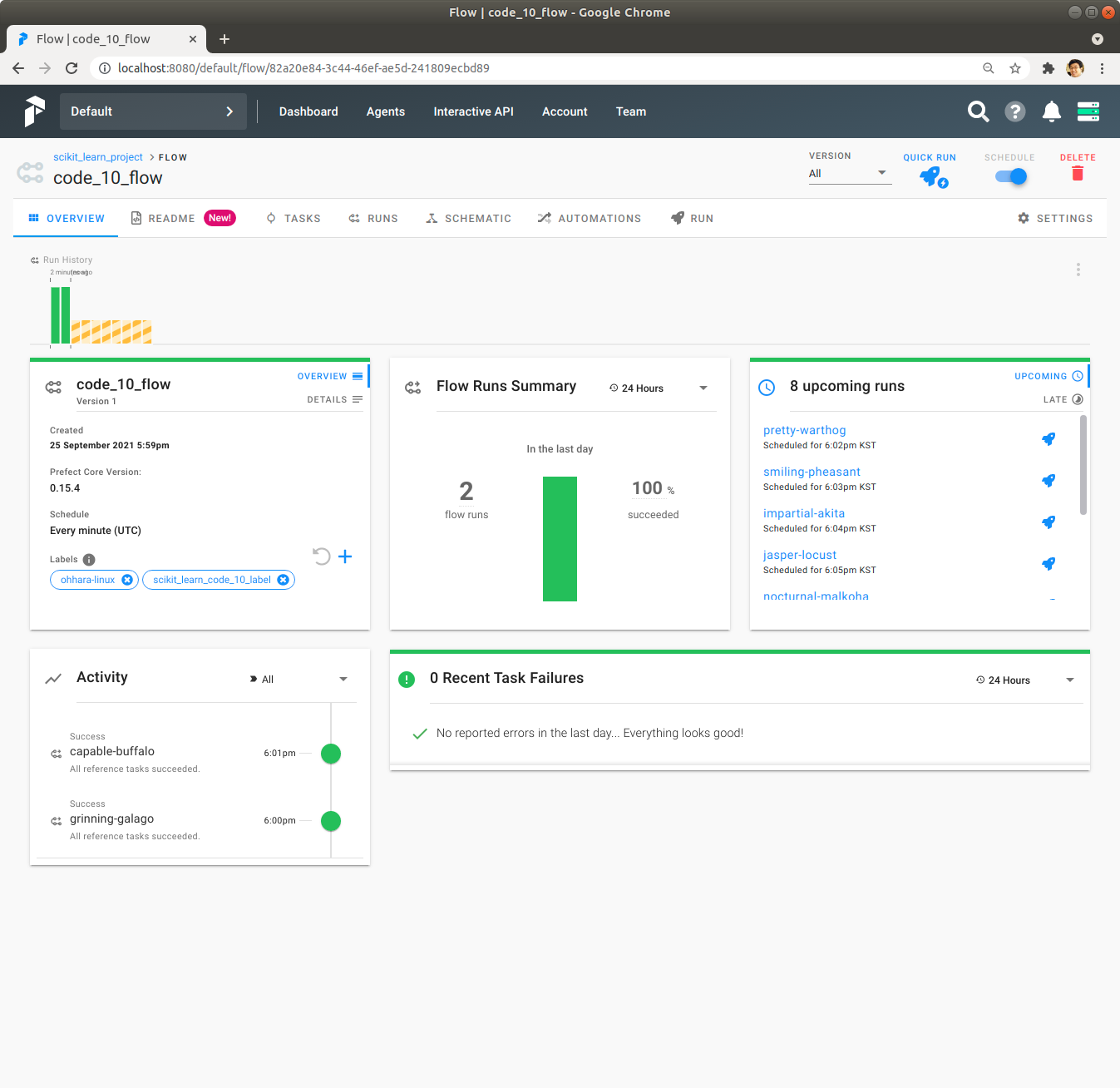
Prefect Server UI를 통해 Flows를 Click하면, code_10_flow Flow의 Schedule Check Box가 Check되어 있고, 이미 Flow가 한 번 실행해서 성공적으로 종료되었고, 두 번째 실행중인 것이 보입니다.
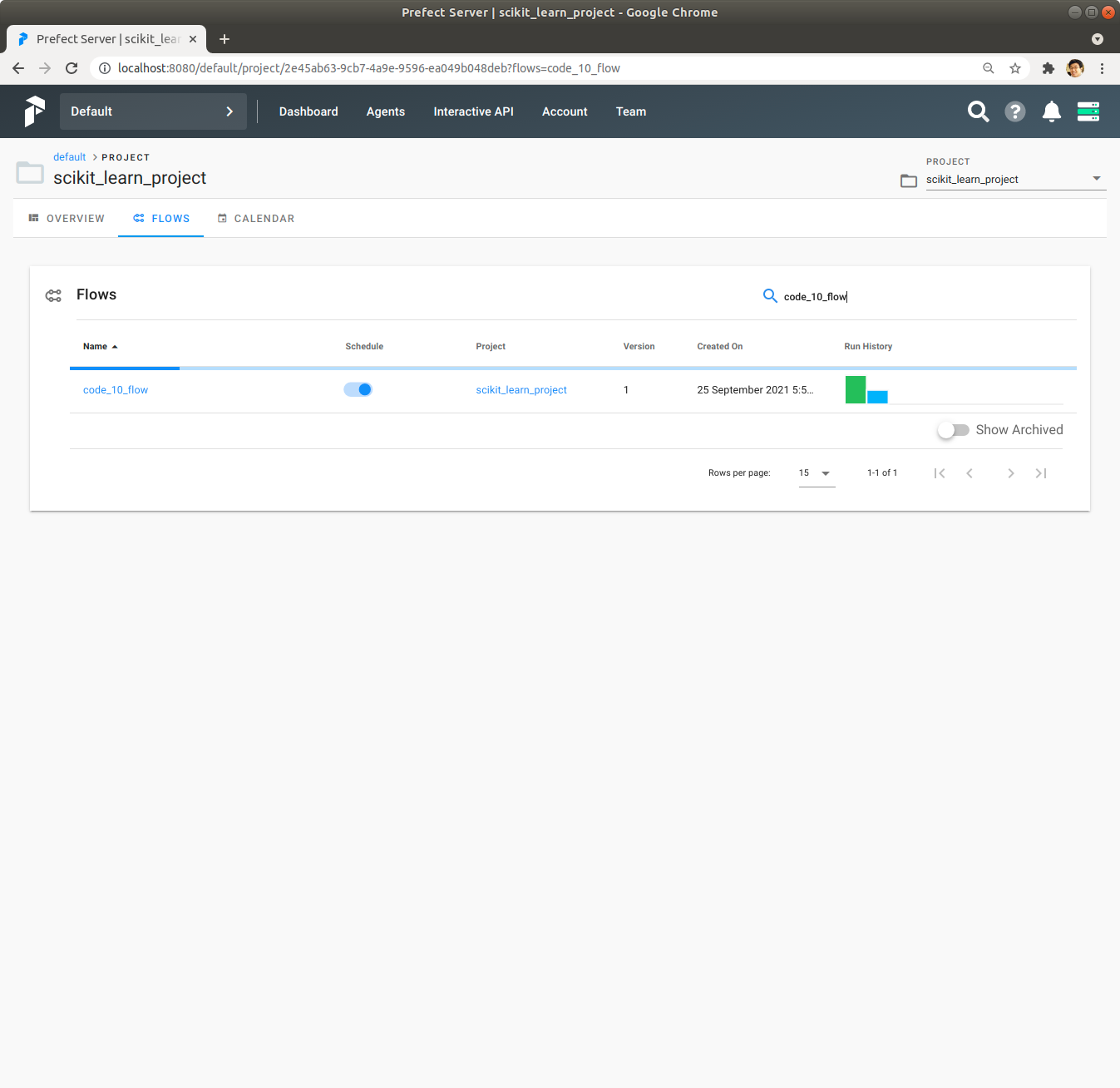
code_10_flow Flow를 Click해서 Flow의 앞으로 실행 예정 Schedule이 노란색 막대로 표시되어 있는 것을 확인합니다.
Note
이 글에서 다루려고 생각했었는데 지면관계상 자세히 설명하지 못한 몇 가지 내용을 정리하면 다음과 같습니다. 나중에 혹시 기회가 된다면 다음 내용에 대해서도 글을 작성해 보도록 하겠습니다.
- 각각의 Flow는 각각 다른 Agent에서 실행될 수 있습니다.
StartFlowRun을 사용하면 다른 Flow를 실행하는 Task를 만들 수 있습니다.- 이것을 이용하면 Flow에서 다른 Flow를 실행할 수 있으며 Flow간의 Dependency도 설정할 수 있습니다.
scheduled_start_time도 직접 설정할 수 있어서 이것을 이용하면 Backfill도 어렵지 않게 구현할 수 있습니다.
- Flow실행의 성공/실패 기준이 되는 Task를 Flow의
reference_tasks에 명시적으로 설정할 수 있습니다.- 명시적으로 설정하지 않으면 Flow의 최종 Task의 성공/실패 여부를 Flow의 성공/실패의 기준으로 봅니다.
- 어떤 Task는 Flow내에서 실패하더라도 Flow의 실패를 의미하지 않는 경우도 있는데(ex. Cleanup Task) 이런 경우에
reference_tasks를 적절한 Task들로 설정해 주면 편합니다.
- Flow는 ~/.prefect Directory에 저장되는데 Flow의
storage를 설정하면 Directory의 변경이 가능하며 Cloud Storage(ex. AWS의 S3)에 저장되도록 설정할 수 있습니다. LocalDaskExecutor에서num_workers를 설정하면 병렬로 실행할 Thread의 수를 설정할 수 있습니다.num_workers를 지나치게 크게 설정한 상태로 여러 Task들이 한 Server에(ex. SQL Server) 접속해서 작업을 하게 되면 Server에 과부하를 일으킬 수 있습니다.num_workers를 설정하지 않으면 CPU수로num_workers가 설정됩니다.
- Task가 실행되는 기준은 일반적으로는 Task가 필요로 하는 모든 다른 Task들이 성공적으로 종료되는 것을 기준으로 하지만, 이 기준은
@taskDecorator에서trigger를 설정하면 변경이 가능합니다.trigger의 Default는all_successful이며 다른 설정으로는all_failed,any_successful,any_failed,all_finished,manual_only이 있습니다.
- Task가 실패하면 자동으로 Retry하도록
@taskDecorator에서 설정할 수 있습니다.max_retries로 Retry의 횟수를 설정할 수 있으며,retry_delay로 Retry의 간격을 설정할 수 있습니다.
- 이 글에서는 이해를 돕기 위해 모든 Task를 직접 만들어서 사용했지만, Prefect에서 제공하는 다양한 Task를 가져다가 사용할 수도 있습니다.
- Task의 상태변화를 보고 특정 상황에 Notification(ex. Slack)을 보낼 수 있습니다.
- Task의 Input과 Output을 원하는 장소에 Cache하거나 저장하도록 설정할 수 있습니다.
- 이 글에서는 Task를 Function으로 구현했지만, Class로 구현하는 것도 가능합니다.
- Prefect는 Task가 Idempotent하다고 가정하지 않습니다.
- Task를 Idempotent하게 만드는 것이 힘든 경우에도 무리없이 Prefect를 사용할 수 있습니다.
- Task는 Idempotent한 것이 권장되지만 필수사항은 아닙니다.
- Prefect는 Flow를 실행할 때 Time정보를 필요로 하지 않습니다.
- Time정보가 없어도 실행이 가능하도록 Flow를 만들 수 있습니다.
- Prefect에서 Flow의 Version은 관리하지만 Task의 Version은 관리하지 않습니다.
- 예를 들어, 어떤 Task에서 어떤 Version의 Python Package를 Import했는지는 Prefect에서 관리하지 않습니다.
- Agent는 Flow가 실행되었으면 하는 환경에 따라 다르게 여러 종류로 만들어서 실행할 수 있습니다.
- 예를 들어, Tensorflow 1.x환경의 Agent, Tensorflow 2.x환경의 Agent등 Dependency나 호환성의 문제로 동시에 설치해서 사용하기 힘든 다양한 환경의 문제를, Agent를 여러개 생성해서 해결할 수 있습니다.
- 이 글에서는 Agent를 이해를 돕기 위해 Local Agent만 사용했는데 Docker Agent나 Kubernetes Agent등 여러가지 Agent를 사용할 수 있습니다.
- Prefect Server는 Flow나 Task의 Meta정보만 가지고 있으며 구체적인 Code에 대한 정보는 가지고 있지 않습니다.
- Prefect Server는 등록되어 있는 Flow를 등록되어 있는 적절한 Agent에게 실행을 명령합니다.
- 그래서 Prefect Cloud Service를 유료로 이용하더라도 Prefect Cloud에 Code를 Upload할 필요가 없습니다.
- Prefect Cloud Service는 유료 Service로 Open Source Version의 Prefect Server보다 많은 기능을 제공합니다.
- 하지만 Open Source Version의 Prefect Server도 기본적인 사용에는 큰 문제가 없습니다.
Conclusion
이 글에서는 Prefect의 사용법을 Code에 살을 조금씩 붙여가면서 살펴보았습니다. 이 글을 통해 Prefect를 이해하는데 조금이나마 도움이 되었으면 좋겠습니다.