ELK란? Dable에서의 ELK 활용 소개
시작하며
안녕하세요 데이블 Advertiser Platform 팀(AP팀)의 한갑종입니다. 이번 포스팅에서는 데이터 수집 및 수집된 데이터를 바탕으로 한 검색 및 시각화를 할 수 있는 시스템인 ELK에 대한 개괄과 데이블에서의 사용 사례를 간단하게 소개해보고자 합니다.
ELK란?
다들 아시는 것처럼 ELK는 3가지의 오픈 소스 프로젝트들의 첫 글자를 따온 것으로 그 각각은 Elasticsearch, Logstash, Kibana 를 말합니다. 여기서 Elasticsearch는 검색과 분석을 위해서 사용되는 엔진이며, Logstash는 다양한 소스로부터 데이터를 받아서 처리할 수 있는 데이터 처리 파이프라인으로 Elasticsearch에 데이터를 공급하는 역할을 합니다. 마지막으로 Kibana는 데이터 시각화 및 탐색 툴로 Elasticsearch 상의 데이터를 쉽게 다룰 수 있게 해줍니다.
Elasticsearch
Elasticsearch는 Apache Lucene를 기반으로 만들어진 검색엔진 솔루션입니다. 대용량 데이터 검색을 매우 빠른 속도로 처리하는데 많은 장점 있으며 database들의 순위을 매기는 DB-engines에서도 2021년 3월 현재 전체 8위, 검색엔진 랭킹 1위를 차지하고 있습니다. Elasticsearch는 다양한 기능이 있는데 이러한 기능을 제대로 활용하기 위해서는 단순 검색이 아니라 API를 활용하는 방법을 따로 학습해야 하는데 Kibana를 사용하면 상대적으로 간단하게 그 기능들을 활용하면서 데이터 시각화나 모니터링 등의 고급 기능들을 사용할 수 있는 장점이 있어서 데이블에서도 Kibana를 활용하고 있습니다. 이번 포스팅에서는 데이블에서 어떤 식으로 ELK를 사용하는지 활용 예제 중심으로 설명할 예정이기 때문에 Elasticsearch나 ELK stack의 세부적인 구조나 동작 등에 대해서는 다루지 않을 예정입니다.
Elastic License vs AWS managed Elasticsearch service
데이블에서는 개인화 추천 서비스를 제공하기 위해서 cloud service platform으로 Amazon의 AWS를 사용하고 있습니다. ELK 스택을 구축하던 초창기에는 데이블에서도 자체 구축 서버를 활용하여 Elasticsearch을 사용하고 있었으나, 현재는 AWS에서 제공하는 Elasticsearch service를 사용하고 있습니다. 비용면에서는 AWS 상의 서비스를 활용하는 것이 더 클 수도 있으나, 관리에 드는 비용과 고가용성을 감안하여 내린 결정입니다. 최근(2021년 1월)에 바뀐 Elastic License에 대한 정책은 데이블에서도 관심을 가지고 지켜보고 있는 상황입니다.
Logstash
Logstash는 다양한 플랫폼에서 주어지는 데이터를 적절하게 소화하여 Elasticsearch에 적재해주는 장점이 있습니다. 데이블에서는 기본적으로 nodejs를 활용한 웹서버들을 많이 사용하고 있습니다. 따라서 데이블에서는 nodejs에서 많이 사용하는 로그 라이브러리인 log4js, winston에 대응할 수 있는 logstash 용 모듈을 개선하여 사용하고 있습니다. 내부적으로는 Logstash TCP 플러그인을 활용하고 있으며 기존에 log4js, winston을 사용하고 있다면 간단한 수정만으로 적용할 수 있다는 장점이 있습니다.
Kibana
Kibana는 웹상에서 Elasticsearch에 존재하는 데이터를 쉽게 탐색하고 분석할 수 있게 해주는 도구입니다. Elasticsearch에서 제공하는 수많은 기능을 상대적으로 쉬운 인터페이스를 통해서 접근할 수 있게 해주어서 데이블에서도 다양하게 활용하고 있습니다.
Dable에서의 ELK stack 구축
ELK의 소개는 간략히 하고 실제로 Dable에서 어떤 식으로 ELK stack을 구축하였는지를 살펴보겠습니다. 위에서 언급한 것처럼 Elasticsearch 서버는 AWS에서 제공하는 Amazon Elasticsearch Service를 사용하고 있습니다. 해당 서비스에서 사용 중인 클러스터(도메인)는 두 개인데, 하나는 개인화 추천에 사용하고 있으며, 다른 하나는 로그 수집 및 모니터링용으로 사용하고 있습니다. AP팀에서는 후자를 사용하고 있으며 이 기준으로 구축된 서버들에 대한 설명을 진행하려고 합니다.
ELK 연동
아마존에서 제공하는 서비스를 사용하면 Elasticsearch와 Kibana에 대한 엔드포인트가 제공됩니다.
즉 Stack에 필요한 서버 중 두 가지는 별도의 구축 과정이 필요 없습니다.
AP팀에서 현재 사용하고 있는 Elasticsearch 서버의 설정은 특별한 부분은 없고 최소 노드를 설정해서 사용 중입니다.
그리고 AP팀에서는 현재 Kibana를 통해서 Elasticsearch를 사용하므로 Kibana 서버에 접근할 수 있도록 설정하는 것이 필요합니다. 이때 기본적으로 보안 이슈 때문에 직접적으로 서버에 접근할 수 있는 경로를 만들기보다는 접근 가능한 서버를 별도로 마련하고 해당 서버를 통해서 우회 접근할 수 있도록 하고 있습니다.
이를 위해서 proxy 서버를 구축하여 사용하고 있으며, 해당 서버에 Logstash 서버도 설치해서 로그 수집 과정도 해당 서버를 통해서 수행하도록 설정된 상태입니다. Logstash 서버는 아래와 같이 TCP를 통해서 데이터를 받을 수 있도록 설정된 상태입니다.
input {
tcp {
codec => "json"
port => "xxxx"
type => "tcp-input"
}
}
filter {
}
output {
elasticsearch {
hosts => [ "amazon endpoint" ]
}
}
위에서 언급한 것처럼 nodejs 서버들에서 라이브러리를 활용하여 Logstash 서버로 데이터를 전송하고 있으며, 전송된 데이터는 최종적으로 Elasticsearch에 적재됩니다. 이렇게 적재된 데이터를 Kibana 서버에서 분석하고 보여주게 되는데, 외부에서의 접속 경로는 proxy 서버로 제한되고 있으며, 해당 서버는 회사 내부 네트워크나 VPN을 통해서만 접속 가능합니다.
winston, log4js 연동
로깅 라이브러리에서 사용하는 모듈들의 개선에 참고한 라이브러리들은 아래와 같습니다. 바로 가져다 쓰지 않은 이유는 현재 버전의 라이브러리나 Elasticsearch, Logstash와 호환이 되지 않는 문제 때문입니다.
Dable에서의 ELK 활용
AP팀에서는 ELK 환경을 로그 수집 및 모니터링으로 활용하고 있다고 위에서 말씀드렸었던 것 같은데, 그 세부적인 활용 방안을 몇 가지 사례를 통해서 살펴보도록 하겠습니다.
Error tracking
가장 기본적인 활용 용도는 서버 상에서 발생하고 있는 에러 로그들을 전송하고, 이를 차후에 검색해서 에러의 원인을 확인하는데 사용하는 것입니다. nodejs 서버나 클라이언트에서 에러가 발생할 때, 로깅이 필요하다고 판단되는 에러들을 전송하여 에러의 빈도수, 에러의 종류, 에러의 내용을 바탕으로 해서 원인과 심각도를 판단한 뒤 버그를 잡는데 활용됩니다.
사용 방식은 검색창에 원하는 종류의 쿼리를 날리고 결과를 확인하는 방식이며, 필요한 경우 time-range를 지정하여 기간을 설정하면 됩니다. 검색 방식은 일반적인 검색 엔진을 사용하는 것과 유사하며, 적재하는 데이터 형식을 JSON으로 할 경우 key를 한정하여 검색가능합니다.
server_name: "api" AND message: "ERROR"
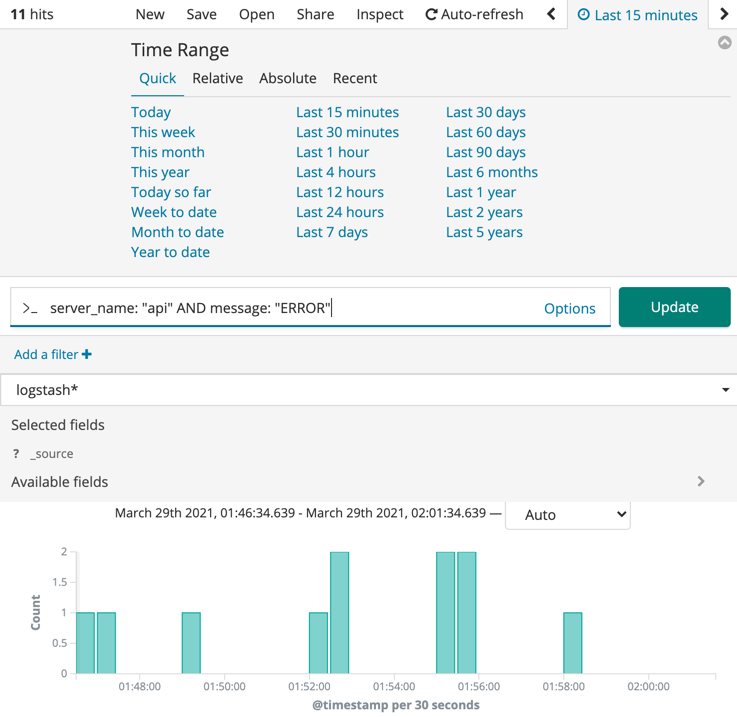
Log format
전송하는 로그 형식을 JSON으로 전달하고 있는데, 기본적으로 정해 놓은 format이 있으면 Kibana에서 분석할 때 편리합니다. Kibana에서는 전송된 데이터에서 많이 사용되고 있는 key들을 미리 보여주고, 이를 쉽게 쿼리문에 추가할 수 있도록 제공합니다. 그리고 쿼리를 날리는 입장에서도 정해진 format이 있으면 자신이 원하는 데이터를 뽑는데 좀 더 적은 시간과 노력이 필요하게 됩니다. 데이블에서 기본적으로 사용하는 로그 포맷은 아래와 같습니다. 사용하는 서버에 따라서 세부적인 사항들을 조금씩 다릅니다. 실제 사용시에는 level을 지정하고 message, fields(전송하고 싶은 data)에 해당하는 값들만 채워주면 됩니다.
{
server_name: 전송하는 서버명,
env: 서버 환경,
pid: process id (thread 확인용),
level: 로그 레벨,
message: 로그 메시지,
fields: json으로 전달할 data
}
Data analysis
두 번째 활용 용도는 로그를 전송할 수 있다는 점에 착안하여 수집하고 싶은 데이터를 전송하고, 이를 데이터 분석에 활용하는 것입니다. 아래 예시는 특정한 로그 중 많이 접속하는 사이들을 1위부터 5위까지 표시한 내용입니다. 이처럼 Kibana를 잘 활용하면 원하는 데이터를 전송하고, 통계를 내는 등의 분석 작업을 수행할 수 있습니다. 또한 Kibana 자체적으로 시각화 도구를 많이 갖추고 있으므로 유용하게 활용 가능하며 이렇게 정리된 데이터를 dashboard를 통해서 한눈에 확인할 수도 있습니다.
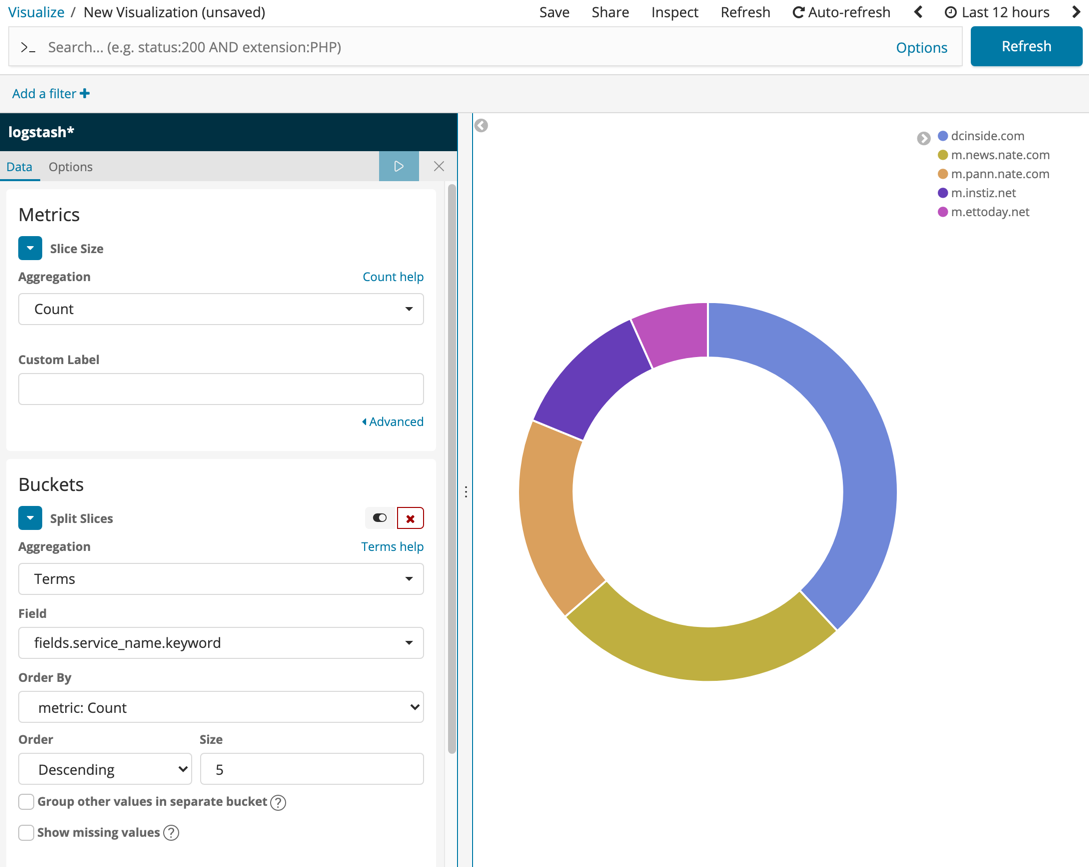
이러한 기능을 잘 활용하기 위해서는 Elasticsearch에서 사용되는 쿼리문에 대해서 좀 더 깊은 이해가 필요할 수도 있습니다. 이번 포스팅에서는 세부적인 내용에 대해서 다루지는 않을 예정이지만 잘 설명하고 있는 책들이 많으니 사보는 것을 추천해 드립니다. Kibana에서 날리는 쿼리문에 대응되는 Elasticsearch의 쿼리문을 확인하고 싶으신 경우 Kibana 우측 상단에 존재하는 Inspect 메뉴에서 Requests를 클릭하여 실제 요청/응답을 살펴보시면 공부하는 데 많은 도움이 되실 것 같습니다.
Server monitoring and alarm
마지막으로 수집된 데이터를 바탕으로 필요한 경우 실시간 알림을 보낼 수 있습니다. 특정 index나 특정 쿼리 조건에 맞는 숫자를 지정된 기간 모니터링하여 trigger 조건에 걸리게 되면 알림을 보내게 됩니다. 알림 방식은 Slack이나 AWS SNS, Custom webhook을 사용가능합니다.
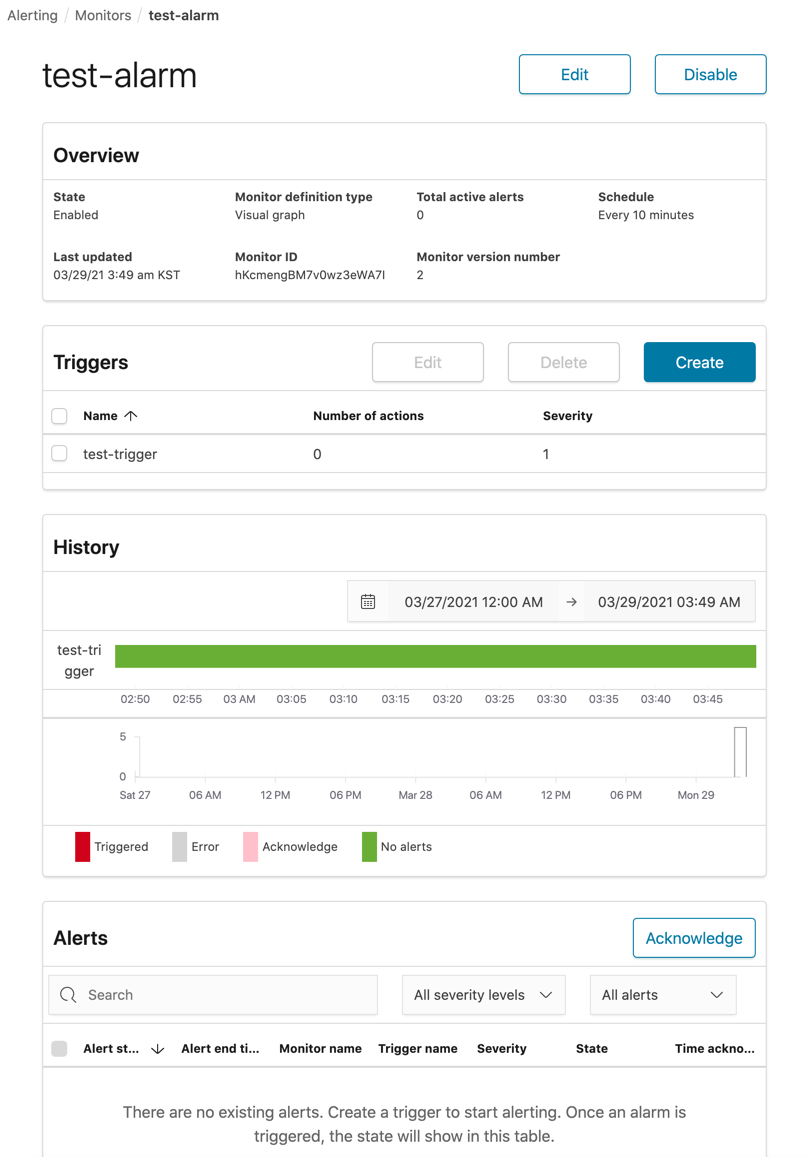
맺으며
이렇게 데이블에서 ELK 환경을 구축하고 활용하는 방법을 소개해보았습니다. 사실 위에 소개해 드린 방식 외에도 다양하게 Elasticsearch를 활용하시는 분들도 많을 것 같습니다. ELK stack(혹은 Elastic stack)은 다양한 방법으로 활용할 수 있고 확장성이 높은 플랫폼이며, 생각보다 쉽게 설치하고 활용 가능합니다. 이 포스팅이 ELK가 어떤 것인지 모르시는 분들이든 이미 잘 활용하고 계신 분들이든 도움이 되었으면 좋겠습니다.