Reinforcement Learning
안녕하세요. 오태호입니다.
이 글에서는 Reinforcement Learning(강화학습)의 기본 개념을 설명하여 Reinforcement Learning에 대해 잘 모르는 사람이 Reinforcement Learning의 기초에 대해 이해할 수 있도록 도와드립니다.
이 글을 이해하기 위해서는 Probability, Statistics, Machine Learning, PyTorch에 대한 기초지식이 필요합니다.
Frozen Lake
OpenAI Gym에 있는 Frozen Lake 문제를 살펴봅시다.
Frozen Lake 문제는 얼어있는 호수에서 Robot을 조종해서 호수 중간중간에 있는 구멍을 피해서 목표지점까지 가는 문제입니다. 4x4크기의 얼어있는 호수에 Robot이 있습니다. 구멍에 빠지면 문제의 목표달성에 실패하게 됩니다. Robot에는 4방향(상,하,좌,우)으로 움직이는 명령을 내릴 수 있는데 호수가 얼어있어서 Robot이 가고자 하는 방향과 다른 방향으로 미끄러져서 이동할 수도 있습니다. 그래도 Robot이 미끄러지더라도 가고자 하는 방향의 반대방향으로 이동하지는 않습니다. 즉, 왼쪽으로 가려고 하는데 오른쪽으로 이동하는 경우는 없습니다.
Frozen Lake의 환경은 간단하게 표현하면 다음과 같이 표현할 수 있습니다.
SFFF
FHFH
FFFH
HFFG
S는 시작지점, G는 목표지점, H는 구멍, F는 얼어있는 호수입니다.
이 문제를 Reinforcement Learning을 사용해서 풀어보도록 하겠습니다.
Reinforcement Learning
Reinforcement Learning의 기본적인 개념에 대해서 살펴봅시다.
Reinforcement Learning은 크게 다음과 같은 형태로 표현할 수 있습니다.

Environment(환경)에 있는 Agent가 어떤 Action을 취하면 Interpreter가 Agent의 Action으로 인한 결과를 보고 State(상태)와 Reward(보상)을 Agent에게 알려줍니다.
Frozen Lake의 상황에 맞추어서 구성해 보면, Agent는 Robot이고, Environment는 얼어있는 호수이고, Action은 Robot에게 내릴 수 있는 명령(상,하,좌,우)이고, Reward는 목표지점에 도착할 때 1이고 그 외에는 0이며, State는 Robot이 4x4크기의 얼어있는 호수에서 어디에 있는지 현재 위치로 구성해 볼 수 있습니다. 참고로 Frozen Lake 문제를 Reinforcement Learning로 풀기 위해서 반드시 이렇게 구성해야 되는 것은 아니며 구성할 수 있는 방법은 매우 다양합니다. 예를 들어, 구멍 근처로 이동할 때 Reward가 -1이 되도록 구성할 수도 있고, State를 Robot의 상하좌우 주변의 구멍의 유무로 구성할 수도 있습니다.
여기서는 Frozen Lake의 State를 Robot이 현재 얼어있는 호수의 어디에 있는지에 따라 다음과 같이 정의합니다. 0이 시작지점이고 15가 목표지점이며 5, 7, 11, 12가 구멍입니다.
0 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15
그리고 Robot이 취할 수 있는 Action은 좌(0), 하(1), 우(2), 상(3)으로 정의합니다.
Agent는 현재 State에서 Reward가 최대가 될 것으로 예상되는 Action을 취해서 행동하기를 시도합니다. 하지만 이것이 생각보다 쉽지 않은 문제입니다. Reward를 최대로 하기 위해서 당장의 Reward만 최대화 하는 것이 중요한 것이 아니고 장기적인 관점에서 Reward를 최대화시키는 것이 중요할 수도 있습니다. 현재 State에서 특정 Action을 취했을 때 당장 Reward가 -1이 되더라도 장기적으로 봤을 때 Reward를 100을 얻을 수 있다면 Reward가 -1이 되는 Action을 취하는 것이 최적의 선택이 될 수도 있습니다.
Deep Neural Network을 구성하여 Machine Learning으로 고양이와 개의 사진을 구분하고자 할 때 Deep Neural Network의 Hidden Layer의 수, Hidden Layer에서 Neuron의 수, Loss Function 등을 직접 사람이 설정해 주고 학습을 진행해야 합니다. 마찬가지로 Reinforcement Learning으로 Robot이 Frozen Lake 문제를 풀도록 Agent가 행동하도록 하게 하기 위해서는 State, Reward, Objective Function 등을 직접 사람이 설정해 주고 학습을 진행해야 합니다.
Episode
Agent입장에서 보면 현재 State에서 어떤 Action을 취하면 Reward를 받고 다음 State를 받습니다. 그리고 새로 받은 State에서 또 다른 Action을 취하고 또 다른 Reward를 받고 또 다른 다음 State를 받습니다. 이런 작업을 Agent는 더 이상 진행이 불가능할 때까지(Frozen Lake에서 Robot이 구멍에 빠지거나 목표지점에 도달할 때까지) 계속 반복하게 됩니다. 이것을 State를 $s_t$, Action을 $a_t$, Reward를 $r_t$로 표현하면 다음과 같이 나열할 수 있으며 이것을 Episode라고 부릅니다. Episode나 Episode의 일부를 Trajectory 혹은 Rollout이라고 부르기도 합니다.
\[(s_0, a_0, r_0), (s_1, a_1, r_1), \cdots, (s_T, a_T, r_T)\]Frozen Lake에서 목표지점까지 도착하는 Episode의 예는 다음과 같습니다.
(0, 2, 0), // 현재위치 0, 오른쪽으로 이동 시도, Reward 0를 획득
(4, 1, 0), // 미끄러져서 아래쪽으로 이동하여 현재위치 4, 아래쪽으로 이동 시도, Reward 0
(8, 2, 0), // 의도대로 아래쪽으로 이동하여 현재위치 8, 오른쪽으로 이동 시도, Reward 0
(9, 1, 0), // 의도대로 오른쪽으로 이동하여 현재위치 9, 아래쪽으로 이동 시도, Reward 0
(10, 1, 0), // 미끄러져서 오른쪽으로 이동하여 현재위치 10, 아래쪽으로 이동 시도, Reward 0
(14, 2, 0), // 의도대로 아래쪽으로 이동하여 현재위치 14, 오른쪽으로 이동 시도, Reward 0
(14, 2, 1), // 미끄러져서 이동하지 못하고 현재위치 14, 오른쪽으로 이동 시도, Reward 1
(15) // 의도대로 오른쪽으로 이동하여 목표위치 15에 도착, 더 이상의 Action, Reward가 없음
Frozen Lake에서 구멍에 빠지는 Episode의 예는 다음과 같습니다.
(0, 2, 0), // 현재위치 0, 오른쪽으로 이동 시도, Reward 0
(1, 2, 0), // 의도대로 오른쪽으로 이동하여 현재위치 1, 오른쪽으로 이동 시도, Reward 0
(5) // 미끄러져서 아래쪽으로 이동하여 구멍위치 5에 도착, 더 이상의 Action, Reward가 없음
Policy
$s_t$ State에서 어떤 $a_t$ Action을 취할 것인가에 대한 정책을 Policy라고 부릅니다. Policy는 $\pi(a_t|s_t)$와 같이 표현하며, 이것은 $s_t$ State에서 $a_t$ Action을 취할 확률을 Return하는 Function입니다.
Frozen Lake에서 단순하게 벽이나 구멍을 향해서 가지 않도록 Action을 취하는 Policy Function의 예는 아래와 같습니다. 1의 위치에서 위(벽)나 아래(구멍)로 움직이는 Action을 취할 확률은 각각 $0.0$이고 왼쪽이나 오른쪽으로 움직이는 Action을 취할 확률은 각각 $0.5$입니다.
\[\pi(a_t=0|s_t=1)=0.5 \\ \pi(a_t=1|s_t=1)=0.0 \\ \pi(a_t=2|s_t=1)=0.5 \\ \pi(a_t=3|s_t=1)=0.0\]State Transition
$s_t$ State에서 $a_t$ Action을 취했을 때 State가 $s_{t+1}$ State로 변하는 것을 State Transition이라고 부릅니다. State Transition은 $P(s_{t+1}|s_t,a_t)$와 같이 표현하며, 이것은 $s_t$ State에서 $a_t$ Action을 취했을 때 State가 $s_{t+1}$ State로 변할 확률을 Return하는 Function입니다.
Frozen Lake에서 의도대로 움직일 확률을 $0.50$이라고 하고 옆으로 미끄러질 확률을 $0.25$라고 하면 State Transition Function의 예는 아래와 같습니다. 10의 위치에서 왼쪽으로 움직이려고 하면 의도대로 9로 이동할 확률이 $0.50$이고 미끄러져서 6이나 11로 이동할 확률을 각각 $0.25$입니다.
\[P(s_{t+1}=6|s_t=10,a_t=0)=0.25 \\ P(s_{t+1}=9|s_t=10,a_t=0)=0.50 \\ P(s_{t+1}=14|s_t=10,a_t=0)=0.25\]Reward
$s_t$ State에서 $a_t$ Action을 취해서 State가 $s_{t+1}$ State로 변할 때 Reward를 얻습니다. 글마다 약간씩 정의가 차이가 있어서 헷갈릴 수 있으니 다시 한 번 이 글에서 사용하는 정의를 자세히 설명하면, Reward는 특정 State에서 있는 것만으로는 얻어지지 않으며, $s_t$ State에서 $a_t$ Action을 취해서 State가 $s_{t+1}$ State로 변할 때 얻어집니다. $s_t$ State에서 $a_t$ Action을 취해서 변한 $s_{t+1}$ State가 $s_t$ State와 동일해도 Reward를 얻습니다. Reward는 $r_t=R(s_t,a_t,s_{t+1})$와 같이 표현하며, 이것은 $s_t$ State에서 $a_t$ Action을 취해서 State가 $s_{t+1}$ State로 변할 때 얻는 Reward를 Return하는 Function입니다.
Frozen Lake에서는 State가 15로 변하는 순간에만 Reward가 1이고 나머지의 경우는 0이라 하면 Reward Function의 예는 아래와 같습니다.
\[R(s_t=14,a_t=2,s_{t+1}=15)=1 \\ R(s_t=14,a_t=2,s_{t+1}=14)=0 \\ R(s_t=14,a_t=2,s_{t+1}=10)=0 \\ R(s_t=14,a_t=3,s_{t+1}=10)=0 \\ R(s_t=14,a_t=3,s_{t+1}=13)=0 \\ R(s_t=14,a_t=3,s_{t+1}=15)=1\]Return
Trajectory $(s_0, a_0, r_0), (s_1, a_1, r_1), \cdots, (s_T, a_T, r_T)$를 $\tau$라고 하고, $\tau$ Trajectory에서 얻는 모든 Reward의 합을 Return이라고 부르며 다음과 같이 표현할 수 있습니다.
\[G_0(\tau)=\sum_{t=0}^{T}r_t\]하지만 이렇게 Return을 정의하면 $G_0(\tau)$가 무한대로 발산하는 방향으로 의도치 않은 결과가 나올 수도 있고, 먼 미래의 Reward와 가까운 미래의 Reward를 동일한 가치로 평가하는 불합리한 결과가 나올 수도 있으며, 무한히 먼 미래까지 고려해서 Return을 계산해야 하는 문제도 있어서, 일반적으로는 Return을 이렇게 정의하지 않습니다. 일반적으로는 먼 미래의 Reward는 가까운 미래의 Reward보다 Discount(할인)을 하여 합하도록 하여 다음과 같이 Return Function을 정의합니다.
\[G_0(\tau)=\sum_{t=0}^{T}\gamma^t r_t\]$\gamma$는 Discount Factor라고 부르며, $0.0$부터 $1.0$사이의 값을 설정하는데, $0.0$으로 설정하게 되면 당장 눈앞에 있는 Reward만 고려하고 미래의 Reward는 고려하지 않는 효과가 생기고, $0.9$처럼 $1.0$에 가까운 값으로 설정하면 미래의 Reward를 고려하는 효과가 생깁니다.
$r_0$부터가 아니라 $r_t$부터 시작해서 합산해서 Return을 계산하는 경우는 Return을 다음과 같이 표현합니다.
\[G_t(\tau)=\sum_{t'=t}^{T}\gamma^{t'-t} r_{t'}\]Return은 이번 Reward와 다음 Reward와의 관계를 이용하여 다음처럼 표현할 수도 있습니다.
\[\begin{aligned} G_t(\tau)&=\sum_{t'=t}^{T}\gamma^{t'-t} r_{t'} \\ &=r_t+\gamma r_{t+1}+\gamma^2 r_{t+2} + \cdots +\gamma^{T-t} r_T \\ &=r_t+\gamma G_{t+1}(\tau) \end{aligned}\]Frozen Lake에서는 State가 15로 변하는 순간에만 Reward가 1이고 나머지의 경우는 0으로 설정하였습니다. 만약에 Discount Factor를 $0.9$로 설정하게 되면 Reward를 나중에 얻을수록 Reward가 Discount가 되는 효과가 발생하기 때문에 최대한 빨리 목표지점에 빨리 도달할수록 Return이 커집니다.
Objective
Optimize(최적화)해야 하는 대상을 Objective(목표)라고 부릅니다. Objective는 구체적인 식으로 표현하고 Reinforcement Learning의 각종 기법을 사용하여 이것을 Optimize합니다. Reinforcement Learning에서 생각할 수 있는 Objective Function의 예는 다음과 같이 Return의 기대값을 Return하는 Function입니다.
\[J(\pi)=E_{\tau \sim \pi}[G_0(\tau)]=E_{\tau \sim \pi}\left[\sum_{t=0}^{T}\gamma^t r_t\right]\]이 수식을 좀 더 자세히 풀어서 설명해 보겠습니다. $\pi$ Policy를 따라서 Action을 계속 취하게 되면 $\tau$ Trajectory를 얻게 됩니다. $\tau$ Trajectory를 하나 얻게 되면 Discounted Reward를 합한 $G_0(\tau)$ Return을 얻을 수 있습니다. 이 작업을 여러 번 반복해서 Return을 여러 개를 모아서 Return의 평균(Return의 기대값)을 계산합니다. 이 값을 $J(\pi)$ Objective로 설정합니다. 이와 같이 Objective가 결정되면, Reinforcement Learning의 각종 기법을 사용해 이 값을 Optimize(이 경우에는 Maximize)하여, Agent가 Return을 최대화시키는 방향으로 행동하도록 합니다.
Value
$s$ State에서 시작해서 $\pi$ Policy를 따라서 Action을 계속 취했을 때 얻게 되는 Discounted Reward들의 합의 기대값을 Value라고 부르며 다음과 같이 표현합니다.
\[V^{\pi}(s)=E_{s_0=s,\tau \sim \pi}[G_0(\tau)]=E_{s_0=s,\tau \sim \pi}\left[\sum_{t=0}^{T}\gamma^t r_t\right]\]$s$ State에 있게 되면 앞으로 얼마나 큰 Return을 얻는 것을 기대할 수 있는가를 의미합니다.
Value는 다음과 같이 이전 State와 다음 State의 관계를 이용한 Bellman Equation 형태로 표현할 수도 있습니다.
\[\begin{aligned} V^\pi(s)&=E_{s_t=s,\tau \sim \pi}\left[G_t(\tau)\right] \\ &=E_{s_t=s,\tau \sim \pi}\left[r_t+\gamma G_{t+1}(\tau)\right] \\ &=E_{s_t=s,a_t \sim \pi(a_t|s_t),s_{t+1} \sim P(s_{t+1}|s_t,a_t)}\left[R(s_t,a_t,s_{t+1})+\gamma V^\pi(s_{t+1})\right] \end{aligned}\]Action Value
$s$ State에서 $a$ Action을 취한 후 $\pi$ Policy를 따라서 Action을 계속 취했을 때 얻게 되는 Discounted Reward들의 합의 기대값을 Action Value라고 부르며 다음과 같이 표현합니다. Action Value는 Quality라고 부르기도 합니다.
\[Q^{\pi}(s,a)=E_{s_0=s,a_0=a,\tau \sim \pi}[G_0(\tau)]=E_{s_0=s,a_0=a,\tau \sim \pi}\left[\sum_{t=0}^{T}\gamma^t r_t\right]\]$s$ State에서 $a$ Action을 취하게 되면 앞으로 얼마나 큰 Return을 얻는 것을 기대할 수 있는가를 의미합니다.
Action Value는 Value와 다음과 같이 밀접하게 관련이 있습니다.
\[V^\pi(s)=E_{a \sim \pi(a|s)}\left[Q^\pi(s,a)\right]\]Action Value는 다음과 같이 이전 State와 다음 State의 관계를 Bellman Equation 형태로 표현할 수도 있습니다.
\[\begin{aligned} Q^\pi(s,a)&=E_{s_t=s,a_t=a,\tau \sim \pi}\left[G_t(\tau)\right] \\ &=E_{s_t=s,a_t=a,\tau \sim \pi}\left[r_t+\gamma G_{t+1}(\tau)\right] \\ &=E_{s_t=s,a_t=a,s_{t+1} \sim P(s_{t+1}|s_t,a_t)}\left[R(s_t,a_t,s_{t+1})+\gamma V^\pi(s_{t+1})\right] \\ &=E_{s_t=s,a_t=a,s_{t+1} \sim P(s_{t+1}|s_t,a_t)}\left[R(s_t,a_t,s_{t+1})+\gamma E_{a_{t+1} \sim \pi(a_{t+1}|s_{t+1})}\left[Q^\pi(s_{t+1},a_{t+1})\right]\right] \end{aligned}\]Optimal Policy
Value 혹은 Action Value가 최대가 되는 방향으로 Action을 취하는 Policy를 Optimal Policy라고 합니다. Policy는 $\pi$로 표기했는데, Optimal Policy는 $\pi^*$로 표기합니다. Optimal Policy를 취할 때 Value와 Action Value는 다음과 같은 성질을 가집니다.
\[\begin{aligned} V^{\pi^*}(s)&=\max_{a} Q^{\pi^*}(s,a) \\ &=\max_{a} E_{s_t=s,a_t=a,s_{t+1} \sim P(s_{t+1}|s_t,a_t)}\left[R(s_t,a_t,s_{t+1})+\gamma V^{\pi^*}(s_{t+1})\right] \end{aligned}\] \[\begin{aligned} Q^{\pi^*}(s,a)&=E_{s_t=s,a_t=a,s_{t+1} \sim P(s_{t+1}|s_t,a_t)}\left[R(s_t,a_t,s_{t+1})+\gamma V^{\pi^*}(s_{t+1})\right] \\ &=E_{s_t=s,a_t=a,s_{t+1} \sim P(s_{t+1}|s_t,a_t)}\left[R(s_t,a_t,s_{t+1})+\gamma \max_{a_{t+1}} Q^{\pi^*}(s_{t+1},a_{t+1})\right] \end{aligned}\]Value Iteration
Value Iteration은 $V^{\pi}(s)$를 구하는 다음과 같은 Algorithm입니다. $\pi$ Policy는 $\pi^*$ Optimal Policy처럼 Value가 최대가 되는 방향으로 Action을 취한다고 가정하고 그때의 Value를 구합니다.
- 모든 State의 $V^{\pi}(s)$를 초기화합니다.
- 모든 State의 $V^{\pi}(s)$가 안정될 때까지 반복합니다.
- Random하게 여러번 Action을 취하면서 $P(s_{t+1}|s_t,a_t)$과 $R(s_t,a_t,s_{t+1})$에 대한 정보를 수집합니다.
- 각각의 $s$ State에서 반복합니다.
- \(V^{\pi}(s):=\max_a Q^{\pi}(s,a)\) \(=\max_{a} E_{s_t=s,a_t=a,s_{t+1} \sim P(s_{t+1}|s_t,a_t)}\left[R(s_t,a_t,s_{t+1})+\gamma V^{\pi}(s_{t+1})\right]\)
$V^{\pi}(s)$를 구한 후에 $s$ State에서 취할 수 있는 최적의 Action은 다음과 같이 구합니다.
\[\begin{aligned} \pi(s)&:=\arg\max_{a} Q^{\pi}(s,a) \\ &=\arg\max_{a} E_{s_t=s,a_t=a,s_{t+1} \sim P(s_{t+1}|s_t,a_t)}\left[R(s_t,a_t,s_{t+1})+\gamma V^{\pi}(s_{t+1})\right] \end{aligned}\]Frozen Lake를 Value Iteration을 사용하여 푸는 구체적인 방법은 v_iteration.py를 참조하기 바랍니다.
Q Learning
Q Learning은 $Q^{\pi}(s,a)$를 구하는 다음과 같은 Algorithm입니다. $\pi$ Policy는 $\pi^*$ Optimal Policy처럼 Action Value가 최대가 되는 방향으로 Action을 취한다고 가정하고 그때의 Action Value를 구합니다.
- 모든 State, Action의 $Q^{\pi}(s,a)$를 초기화합니다.
- 모든 State, Action의 $Q^{\pi}(s,a)$가 안정될 때까지 반복합니다.
- Random하게 여러번 Action을 취하면서 $P(s_{t+1}|s_t,a_t)$과 $R(s_t,a_t,s_{t+1})$에 대한 정보를 수집합니다.
- 각각의 $s$ State에서 반복합니다.
- 각각의 $a$ Action에서 반복합니다.
- \[Q^{\pi}(s,a):=E_{s_t=s,a_t=a,s_{t+1} \sim P(s_{t+1}|s_t,a_t)}\left[R(s_t,a_t,s_{t+1})+\gamma \max_{a_{t+1}} Q^{\pi}(s_{t+1},a_{t+1})\right]\]
- 각각의 $a$ Action에서 반복합니다.
$Q^{\pi}(s,a)$를 구한 후에 $s$ State에서 취할 수 있는 최적의 Action은 다음과 같이 구합니다.
\[\pi(s):=\arg\max_{a} Q^{\pi}(s,a)\]Frozen Lake를 Q Learning을 사용하여 푸는 구체적인 방법은 q_iteration.py를 참조하기 바랍니다.
Model-based vs Model-free
Value Iteration에서는 $V^{\pi}(s)$를 구한 후에 $s$ State에서 취할 수 있는 최적의 Action($\pi(s)$)을 계산하기 위해서는 $P(s_{t+1}|s_t,a_t)$과 $R(s_t,a_t,s_{t+1})$을 알아야 합니다. 이와 같이 $P(s_{t+1}|s_t,a_t)$과 $R(s_t,a_t,s_{t+1})$을 알아야 하는 것을 Model-based라고 합니다.
Q Learning에서는 $Q^{\pi}(s,a)$를 구한 후에 $s$ State에서 취할 수 있는 최적의 Action($\pi(s)$)을 계산하기 위해서 $P(s_{t+1}|s_t,a_t)$과 $R(s_t,a_t,s_{t+1})$을 알 필요가 없습니다. 이와 같이 $P(s_{t+1}|s_t,a_t)$과 $R(s_t,a_t,s_{t+1})$을 알 필요가 없는 것을 Model-free라고 합니다.
두 가지의 차이를 Frozen Lake의 예를 들어서 살펴보겠습니다.
Value Iteration을 통해 얼어있는 호수 상의 모든 위치에서의 $V(s)$를 모두 구했습니다. 얼어있는 호수상에서의 Robot의 특정 위치에서 4방향(상,하,좌,우) 각각으로 명령을 내렸을 때, 이 Robot이 어디로 이동하게 될지 그리고 이때 얻게 되는 Reward가 얼마가 될지 알아야, $R(s_t,a_t,s_{t+1})+\gamma V^{\pi}(s_{t+1})$를 계산할 수 있고, 이 계산결과를 이용해서 현재 위치에서의 최적의 4방향명령을 알 수 있습니다.
Q Learning을 통해 얼어있는 호수 상의 모든 위치에서의 $Q^{\pi}(s,a)$를 모두 구했습니다. 얼어있는 호수상에서의 Robot의 특정 위치에서 4방향명령 각각의 $a$ Action으로 $Q^{\pi}(s,0)$, $Q^{\pi}(s,1)$, $Q^{\pi}(s,2)$, $Q^{\pi}(s,3)$을 살펴보면 현재 위치에서의 최적의 4방향명령을 알 수 있습니다.
Cart Pole
OpenAI Gym에 있는 Cart Pole 문제를 살펴봅시다.
Cart Pole 문제는 Cart에 위로 Pole이 달려 있고 Cart를 움직이면서 최대한 오래동안 Pole이 안 쓰러지도록 균형을 잡는 문제입니다.
그림으로 표현하면 다음과 같습니다.
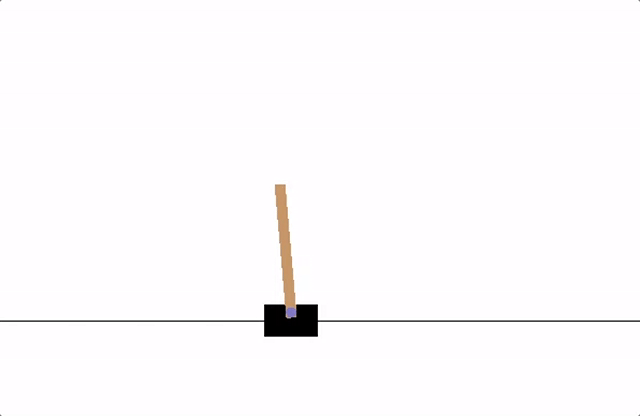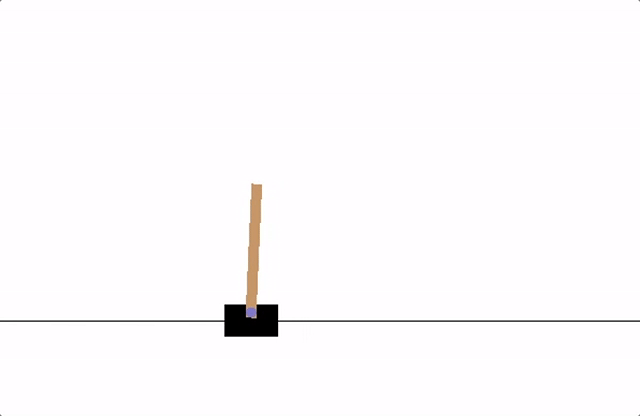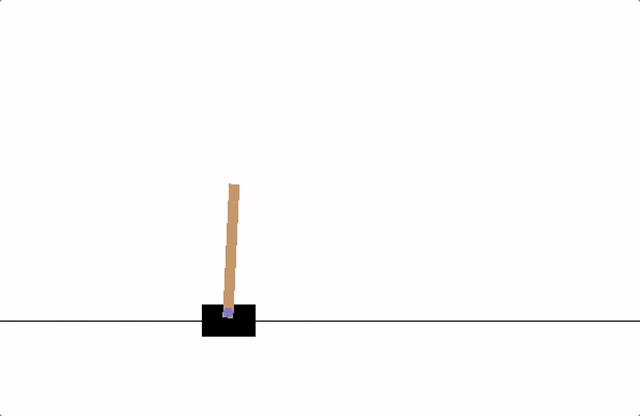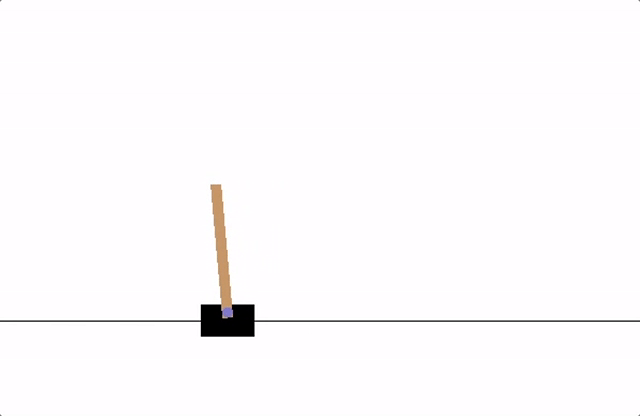
State는 Cart의 위치, Cart의 속도, Pole의 각도, Pole의 끝부분의 속도로 총 4개의 숫자로 구성되어 있습니다.
Cart가 취할 수 있는 Action은 Discrete하게 왼쪽(0), 오른쪽(1)입니다.
Reward는 한 Step이 지나면 1이 주어집니다. Pole이 균형을 잃어서 넘어지면 Episode가 도중에 끝나기 때문에 최대한 Pole의 균형을 잡으면서 오래 버틸수록 얻는 Reward가 커집니다.
이 문제를 푸는 방법은 여러가지 방법이 있을 수 있는데 그 중 하나의 방법으로는 State의 값을 바탕으로 물리학적으로 계산해서 Pole의 균형을 잡는 방법이 있을 수 있습니다. 즉, 어떤 State에 있을 때, Cart가 어떠한 Action을 취했을 때, 다음 State가 어떻게 될지를 예측해서 문제를 푸는 것으로, $P(s_{t+1}|s_t,a_t)$을 알아내서 Model-based로 문제를 푼다는 뜻입니다. Cart Pole 문제는 구조가 비교적 단순해서 Model-based로 문제를 푸는 것도 불가능하지는 않겠지만, 현실의 문제는 Model-based로 풀기가 쉽지 않은 경우가 많으므로, 이 글에서는 Model-based보다는 Model-free한 방법으로 문제를 풀어보겠습니다.
앞에서 살펴본 Model-free 방법인 Q Learning을 이용해서 Frozen Lake 문제를 풀 때와 동일한 방법으로 Cart Pole 문제를 풀려고 하면 한 가지 곤란한 문제를 만나게 됩니다. Frozen Lake 문제의 경우에는 전체 State의 수가 Robot의 현재 위치로 Discrete하게 16개가 있었지만, Cart Pole 문제에서는 State가 4개의 Continuous한 숫자로 이루어져 있어서 전체 State의 수가 사실상 무한대가 됩니다. Frozen Lake 문제에서는 각 State에서의 $Q(s,a)$를 하나하나 계산해서 Table로 저장하는 것이 가능했지만, Cart Pole 문제에서는 State의 수가 매우 많아서 Table로 저장하는 것이 현실적으로 불가능합니다. 한 가지 해결 방안으로 State의 Continuous한 숫자를 몇 개 범위로 나눠서 State의 수를 Discrete하게 만들어 주는 것을 생각해 볼 수 있는데, 이 방법으로는 State에 담겨져 있는 풍부한 내용을 제대로 활용하지 못하게 되기 때문에 바랍직하지 않습니다.
Deep Q Network
Deep Q Network(DQN)는 Q Learning와 마찬가지로 $Q^{\pi}(s,a)$을 구해서 $\pi^*$ Optimal Policy를 구하는데, $Q^{\pi}(s,a)$을 Deep Neural Network로 구성하여 구하는 Algorithm입니다.
Q Learning에서 봤었던 $Q^{\pi^*}(s,a)$의 수식을 다시 살펴보면 다음과 같습니다.
\[Q^{\pi^*}(s,a)=E_{s_t=s,a_t=a,s_{t+1} \sim P(s_{t+1}|s_t,a_t)}\left[R(s_t,a_t,s_{t+1})+\gamma \max_{a_{t+1}} Q^{\pi^*}(s_{t+1},a_{t+1})\right]\]자세히 살펴보면 Agent가 Environment에서 열심히 Action을 하면서 Reward를 얻으면서 살펴보면 Trajectory를 많이 모을 수 있는데, 알 수 없는 부분은 $Q^{\pi^*}(s,a)$입니다. 많이 모은 Trajectory를 이용하여 위의 수식을 최대한 비슷하게 만족하는 $Q^{\pi}(s,a)$를 Deep Neural Network으로 구성해서 구합니다.
Trajectory $s_t, a_t, r_t, s_{t+1}$를 예로 들어서 살펴보겠습니다. $s_t, a_t, r_t, s_{t+1}$이 주어졌을 때 다음 식을 만족하는 $Q^{\pi}(s_t,a_t)$를 구하고 싶습니다.
\[Q^{\pi}(s_t,a_t)=r_t+\gamma \max_{a_{t+1}} Q^{\pi}(s_{t+1},a_{t+1})\]그러기 위해서, Loss $L$을 다음과 같이 정의하고, 열심히 모은 $s_t, a_t, r_t, s_{t+1}$를 Loss $L$에 쏟아부으면서, Stochastic Gradient Descent를 이용하여 Loss $L$을 Optimize(Minimize)하여, $Q^{\pi}(s,a)$를 구합니다.
\[L=\left[Q^{\pi}(s_t,a_t)-(r_t+\gamma \max_{a_{t+1}} Q^{\pi}(s_{t+1},a_{t+1}))\right]^2\]참고로 $Q^{\pi}(s,a)$를 Deep Neural Network으로 구성할 때 Input을 $s$, $a$로 하고 Output을 Q로 구성하게 되면 $\max_{a_{t+1}} Q^{\pi}(s_{t+1},a_{t+1})$을 계산할 때 $a_{t+1}$을 Action의 수만큼 $Q^{\pi}(s_{t+1},a_{t+1})$를 호출해야 해서 매우 불편합니다. Cart Pole의 경우에는 $\max_{a_{t+1}} Q^{\pi}(s_{t+1},a_{t+1})$을 계산할 때, $Q^{\pi}(s_{t+1},0)$, $Q^{\pi}(s_{t+1},1)$ 과 같이 두 번 호출하여 가장 큰 값을 사용해야 합니다. 그래서 일반적으로는 $Q^{\pi}(s,a)$를 구성할 때, Input을 $s$로 하고 Output을 Action의 수 만큼의 Q가 되도록 구성합니다. Cart Pole의 경우에는 $\max_{a_{t+1}} Q^{\pi}(s_{t+1},a_{t+1})$을 계산할 때, Input을 $s$로 주면 Output이 $Q^{\pi}(s_{t+1},0)$, $Q^{\pi}(s_{t+1},1)$ 과 같이 두 개가 동시에 나오게 되고 이 중에 가장 큰 값을 사용합니다.
Epsilon Greedy Policy
$Q^{\pi}(s,a)$를 구하기 위해 Trajectory를 모을 때 항상 $\arg\max_{a} Q^{\pi}(s,a)$ 이렇게 최적의 Action을 선택하게 되면, 방문했던 State중에 가장 좋은 State에만 집중적으로 방문하고 한 번도 방문하지 않았던 State에는 방문하지 않게 됩니다. 방문하지 않았던 State중에 지금까지보다 훨씬 좋은 State가 존재할 수도 있기 때문에, 이렇게 Trajectory를 모으게 되면 정확한 $Q^{\pi}(s,a)$를 구할 수 없게 됩니다. 이런 상황에서는 $1-\epsilon$ 확률만큼은 $\arg\max_{a} Q^{\pi}(s,a)$ 와 같이 기존과 동일한 방법으로 Action을 선택하고, $\epsilon$ 확률만큼은 Random한 Action을 취하면 좀 더 다양한 State에서 잘 작동하는 $Q^{\pi}(s,a)$를 구할 수 있습니다.
Action을 $\arg\max_{a} Q^{\pi}(s,a)$와 같이 최적의 Action을 항상 선택하는 Policy를 Greedy Policy라 합니다. $1-\epsilon$ 확률만큼은 $\arg\max_{a} Q^{\pi}(s,a)$와 같이 최적의 Action을 취하고, $\epsilon$ 확률만큼은 Random한 Action을 취하는 Policy를 Epsilon Greedy Policy($\epsilon$ Greedy Policy)라고 합니다. $\epsilon$은 $Q^{\pi}(s,a)$를 구하는 초반에는 다소 높게 설정했다가 $Q^{\pi}(s,a)$가 안정적으로 작동하는 상황을 보면서 조금씩 낮게 설정하는 것이 일반적입니다.
한 번도 방문하지 않았던 State에 방문해 보는 것을 Exploration이라고 하고, 자신이 방문했던 State중에 가장 좋은 State에 방문하는 것을 Exploitation이라고 합니다. Epsilon Greedy Policy에서 초반에 $\epsilon$이 크면 Exploration에 집중하게 되고 후반에 $\epsilon$이 작으면 Exploitation에 집중하게 됩니다. Exploration과 Exploitation은 서로 Tradeoff관계를 가집니다.
Experience Replay
앞에서 $Q^{\pi}(s,a)$을 구하기 위해서 Stochastic Gradient Descent를 사용했는데, Stochastic Gradient Descent를 사용하기 위해서는 학습에 사용하는 Batch가 IID(Independent and Identically Distributed)하다는 가정이 필요합니다. 하지만 모은 Trajectory를 살펴보면 시간상으로 가까이 있는 Data는 상당히 Correlated되어 있기 때문에($s_{t+1}$이 무엇이냐는 $s_t$가 무엇이었냐에 크게 영향을 받기 때문에) 시간 순서로 구성한 Batch로 Stochastic Gradient Descent를 사용해서 $Q^{\pi}(s,a)$을 구하는 것이 쉽지 않다는 것을 알 수 있습니다. 이 문제를 해결하기 위해 Trajectory를 많이 모아서 Buffer로 만들어 놓고, 원하는 Batch 크기 만큼 Random하게 Buffer에서 가져와서, Batch를 IID하게 만든 후에, Stochastic Gradient Descent를 사용하여 $Q^{\pi}(s,a)$를 구합니다. 이 방법을 Experience Replay라고 합니다.
How to Solve Cart Pole with Deep Q Network
Cart Pole을 Deep Q Network을 사용하여 푸는 구체적인 방법은 dqn.py를 참조하기 바랍니다.
Continuous Cart Pole
앞에서 언급된 Cart Pole과 동일한데 Action이 Discrete하지 않고 Continuous한 문제를 살펴봅시다.
Cart가 취할 수 있는 Action은 $-1.0$부터 $+1.0$사이의 값을 가지고 $-1.0$에 가까울수록 왼쪽으로 힘을 강하게 가하고 $+1.0$에 가까울수록 오른쪽으로 힘을 강하게 가합니다.
Cart Pole 문제를 풀 때 사용했던 Deep Q Network으로 Continuous Cart Pole 문제를 풀려고 살펴보면, Continuous Cart Pole 문제에서는 Action이 Continuous해서 Action의 수가 사실상 무한대가 되면서, $Q^{\pi}(s,a)$의 Deep Neural Network의 크기도 사실상 무한대가 되어 버려서, 구현이 현실적으로 불가능하다는 것을 알 수 있습니다. 한 가지 해결 방안으로 Action의 Continuous한 숫자를 몇 개 범위로 나눠서 Action의 수를 Discrete하게 만들어 주는 것을 생각해 볼 수 있는데, 이 방법으로는 정교하게 Action을 취할 수가 없어서 바람직하지 않습니다.
REINFORCE
Deep Q Network에서는 $Q^{\pi}(s,a)$를 구해서 $\pi^*$ Optimal Policy를 간접적으로 구했습니다. REINFORCE는 $E_{\tau \sim \pi}[G_0(\tau)]$를 최대화시키는 $\pi^*$ Optimal Policy를 직접 구하는 Algorithm입니다. Vanilla Policy Gradient라고도 불립니다. 여기서는 $\pi$ Policy를 Deep Neural Network으로 구성해서 구합니다.
$\pi$ Policy를 Deep Neural Network으로 구성하는데 이때 Deep Neural Network의 Parameter들을 $\theta$로 표기하고 $\theta$들로 구성되어 있는 Policy를 $\pi_\theta$로 표기합니다. $\pi_\theta(a|s)$는 $s$ State에서 $a$ Action을 취할 확률을 나타냅니다. $\pi_\theta(a|s)$를 Deep Neural Network으로 구성할 때는 Input으로 $s$ State를 주면 Output으로 각각의 Action을 취할 확률이 되도록 구성합니다. 그런데 Continuous Cart Pole의 경우에는 Action이 Continuous하기 때문에, Action의 수가 무수히 많아서, Output의 수가 무수히 많아지기 때문에, 이렇게 구성하는 것이 불가능합니다. 그래서, 이런 경우에는 Deep Neural Network의 Output으로 Action의 Probability Distribution이 나오도록 하는데, 이 Probability Distribution이 Normal Distribution을 따른다고 가정하고, 이 Normal Distribution의 Mean과 Standard Deviation을 Deep Neural Network의 Output이 되도록 구성합니다. 정리하면, $\pi_\theta(a|s)$의 Deep Neural Network은 Input으로 $s$ State를 주면 Output으로 Normal Distribution을 따르는 $a$ Action의 $\mu$ Mean과 $\sigma$ Standard Deviation이 되도록 구성합니다.
Objective of REINFORCE
REINFORCE에서 Optimize(Maximize)하고자 하는 $J(\pi_\theta)$ Objective는 다음과 같습니다.
\[J(\pi_\theta)=E_{\tau \sim \pi_\theta}[G_0(\tau)]\]이것을 Maximize해 주는 $\pi_\theta(a|s)$를 찾기를 시도하는데, $\pi_\theta(a|s)$을 찾는다는 것은 $\pi_\theta(a|s)$을 구성하고 있는 Deep Neural Network의 Parameter들인 $\theta$를 찾는 것을 의미합니다. Objective를 Maximize해 주는 $\theta$는 $J(\pi_\theta)$ Objective를 $\theta$에 대해 미분해서 Stochastic Gradient Ascent를 사용하여 구합니다. 다음과 같이 미분을 하고 이 정보를 이용해서 $\theta$를 구합니다.
\[\nabla_\theta J(\pi_\theta)=\nabla_\theta E_{\tau \sim \pi_\theta}[G_0(\tau)]\]계산과정이 다소 복잡한데, 이것을 계산해서 정리하면 다음과 같습니다.
\[\nabla_\theta J(\pi_\theta)=E_{\tau \sim \pi_\theta}\left[\sum_{t=0}^T G_t(\tau)\nabla_\theta \ln\pi_\theta(a_t|s_t)\right]\]Derivation of the Objective
$\nabla_\theta J(\pi_\theta)$ 수식의 유도과정은 다음과 같습니다.
$f(x)$이 있고 $x$가 Probability Distribution $p(x|\theta)$를 따를 때 $\nabla_\theta E_{x \sim p(x|\theta)}[f(x)]$는 다음과 같습니다.
\[\begin{aligned} \nabla_\theta E_{x \sim p(x|\theta)}[f(x)]&=\nabla_\theta\int_{-\infty}^{\infty} f(x)p(x|\theta) dx \\ &=\int_{-\infty}^{\infty} f(x)\nabla_\theta p(x|\theta) dx \\ &=\int_{-\infty}^{\infty} f(x)p(x|\theta)\frac{\nabla_\theta p(x|\theta)}{p(x|\theta)} dx \\ &=\int_{-\infty}^{\infty} f(x)p(x|\theta)\nabla_\theta\ln p(x|\theta) dx \\ &=E_{x \sim p(x|\theta)}[f(x)\nabla_\theta\ln p(x|\theta)] \end{aligned}\]$x=\tau$, $f(x)=G_0(\tau)$, $p(x|\theta)=p(\tau|\theta)$라고 하면 다음과 같습니다.
\[\nabla_\theta J(\pi_\theta)=E_{\tau \sim \pi_\theta}\left[G_0(\tau)\nabla_\theta \ln p(\tau|\theta)\right]\]이 식의 $\nabla_\theta \ln p(\tau|\theta)$는 다음과 같습니다. $p(\tau|\theta)$는 $s_0$ State에서 $a_0$ Action을 취할 확률, $s_0$ State에서 $a_0$ Action을 취할 때 다음 State가 $s_1$이 될 확률, $s_1$ State에서 $a_1$ Action을 취할 확률, $s_1$ State에서 $a_1$ Action을 취할 때 다음 State가 $s_2$이 될 확률, …, 이런 식으로 구한 모든 확률을 곱해서 구합니다.
\[p(\tau|\theta)=\prod_{t=0}^T p(s_{t+1}|s_t, a_t)\pi_\theta(a_t|s_t) \\ \begin{aligned} \ln p(\tau|\theta)&=\ln \prod_{t=0}^T p(s_{t+1}|s_t, a_t)\pi_\theta(a_t|s_t) \\ &=\sum_{t=0}^T(\ln p(s_{t+1}|s_t, a_t)+\ln \pi_\theta(a_t|s_t)) \end{aligned} \\ \begin{aligned} \nabla_\theta \ln p(\tau|\theta)&=\nabla_\theta \sum_{t=0}^T(\ln p(s_{t+1}|s_t, a_t)+\ln \pi_\theta(a_t|s_t)) \\ &=\sum_{t=0}^T \nabla_\theta \ln \pi_\theta(a_t|s_t) \end{aligned}\]$\nabla_\theta J(\pi_\theta)$을 다시 정리해 보면 다음과 같습니다.
\[\begin{aligned} \nabla_\theta J(\pi_\theta)&=E_{\tau \sim \pi_\theta}\left[G_0(\tau)\nabla_\theta \ln p(\tau|\theta)\right] \\ &=E_{\tau \sim \pi_\theta}\left[\sum_{t=0}^T G_0(\tau) \nabla_\theta \ln \pi_\theta(a_t|s_t)\right] \end{aligned}\]$\pi_\theta(a_t|s_t)$는 $t$ 시점에 취하는 Action의 Probability Distribution인데 $G_0(\tau)$는 $0$부터 $T$ 시점까지의 Discounted Reward의 합입니다. 미래의 Action이 과거의 Reward에 영향을 끼칠 수 없기 때문에 $\nabla_\theta J(\pi_\theta)$는 다음과 같이 정리되어서 유도가 완료되었습니다.
\[\nabla_\theta J(\pi_\theta)=E_{\tau \sim \pi_\theta}\left[\sum_{t=0}^T G_t(\tau) \nabla_\theta \ln \pi_\theta(a_t|s_t)\right]\]How to Calculate the Objective
$\nabla_\theta J(\pi_\theta)$ 수식을 구체적으로 어떻게 계산할 수 있는지 자세히 살펴보겠습니다.
$\tau \sim \pi_\theta$와 같이 $\pi_\theta$ Policy를 따라 $\tau$ Episode를 여러개 생성해서 기대값을 계산합니다. $(s_0, a_0, r_0), (s_1, a_1, r_1), \cdots, (s_T, a_T, r_T)$와 같이 Episode를 생성합니다.
$G_t(\tau)$는 다음과 같이 $t$시점부터 $T$시점까지 Discounted Reward의 합입니다.
\[G_t(\tau)=\sum_{t'=t}^{T}\gamma^{t'-t} r_{t'}\]$\pi_\theta(a_t|s_t)$는 $s_t$ State에서 $a_t$ Action을 취할 확률입니다. 이것은 Deep Neural Network으로 구현합니다. Deep Neural Network의 Input은 $s_t$이며 Output은 $a_t$의 확률분포를 표현하는 Normal Distribution의 $\mu_\theta(s_t)$ Mean과 $\sigma_\theta(s_t)$ Standard Deviation입니다. 구체적으로 $\pi_\theta(a_t|s_t)$은 다음과 같습니다. 여기의 $\pi$는 Policy가 아니라 원주율인 것에 주의합니다.
\[\pi_\theta(a_t|s_t)=\frac{1}{\sigma_\theta(s_t)\sqrt{2\pi}}\exp\left(-\frac{(a_t-\mu_\theta(s_t))^2}{2\sigma^2_\theta(s_t)}\right)\]$\ln \pi_\theta(a_t|s_t)$는 다음과 같습니다.
\[\ln \pi_\theta(a_t|s_t)=-\ln(\sigma_\theta(s_t))-\frac{1}{2}\ln 2\pi-\frac{(a_t-\mu_\theta(s_t))^2}{2\sigma^2_\theta(s_t)}\]$\mu_\theta(s_t)$, $\sigma_\theta(s_t)$는 $\theta$ Parameter들을 가지는 Deep Neural Network의 Output이기 때문에 $\nabla_\theta \ln \pi_\theta(a_t|s_t)$과 같이 $\theta$로 미분한 값은 PyTorch AutoGrad를 사용하여 계산할 수 있습니다.
Intuition of the Objective
$\nabla_\theta J(\pi_\theta)$을 직관적으로 살펴보겠습니다.
\[\nabla_\theta J(\pi_\theta)=E_{\tau \sim \pi_\theta}\left[\sum_{t=0}^T G_t(\tau) \nabla_\theta \ln \pi_\theta(a_t|s_t)\right]\]$\tau \sim \pi_\theta$와 같이 $\pi_\theta$ Policy를 따라 $\tau$ Episode를 생성합니다. $(s_0, a_0, r_0), (s_1, a_1, r_1), \cdots, (s_T, a_T, r_T)$와 같이 Episode를 생성합니다. 이해를 쉽게 하기 위해 여기서는 Episode를 한 개만 생성해서 살펴봅니다.
$\nabla_\theta J(\pi_\theta)$는 Deep Neural Network의 $\theta$ Parameter의 값이 약간 커졌을 때 $J(\pi_\theta)$ Objective가 얼마나 커지는지를 나타냅니다.
$G_0(\tau)$는 $0$부터 $T$시점까지의 Discounted Reward의 합입니다. $\nabla_\theta \ln \pi_\theta(a_0|s_0)$는 Deep Neural Network의 $\theta$ Parameter의 값이 약간 커졌을 때 $s_0$ State에서 $a_0$ Action을 취하는 확률이(정확하게는 확률의 $\ln$이) 얼마나 커지는지를 나타냅니다.
$G_1(\tau)$는 $1$부터 $T$시점까지의 Discounted Reward의 합입니다. $\nabla_\theta \ln \pi_\theta(a_1|s_1)$는 Deep Neural Network의 $\theta$ Parameter의 값이 약간 커졌을 때 $s_1$ State에서 $a_1$ Action을 취하는 확률이(정확하게는 확률의 $\ln$이) 얼마나 커지는지를 나타냅니다.
…
$G_T(\tau)$는 $T$부터 $T$시점까지의 Discounted Reward의 합입니다. Episode의 마지막으로 더 이상 Action과 Reward가 없습니다.
Deep Neural Network의 $\theta$ Parameter의 값이 약간 커졌을 때 $J(\pi_\theta)$ Objective가 최대한 많이 커지도록 하기 위해서는, $G_t(\tau)$ Discounted Sum이 큰 $t$시점에서 Deep Neural Network의 $\theta$ Parameter의 값이 약간 커졌을 때 $s_t$ State에서 $a_t$ Action을 취하는 확률이 최대한 많이 커져야 합니다. 그리고 반대로 Deep Neural Network의 $\theta$ Parameter의 값이 약간 작아졌을 때 $J(\pi_\theta)$ Objective가 최대한 많이 커지도록 하기 위해서는, $G_t(\tau)$ Discounted Sum이 큰 $t$시점에서 Deep Neural Network의 $\theta$ Parameter의 값이 약간 작아졌을 때 $s_t$ State에서 $a_t$ Action을 취하는 확률이 최대한 많이 커져야 합니다.
$J(\pi_\theta)$ Objective가 커지게 하기 위해서는, $G_t(\tau)$ Discounted Sum이 큰 $t$시점에서, $s_t$ State에 $a_t$ Action을 취할 확률이 높아지도록 만들어주는 방향으로, Deep Neural Network의 Parameter $\theta$가 변해야(커지거나 작아져야) 합니다.
$\tau \sim \pi_\theta$와 같이 $\pi_\theta$ Policy를 따라 $\tau$ Episode를 생성하고, $\pi_\theta$ Policy에서 $\theta$를 어떻게 살짝 변경하면 $J(\pi_\theta)$가 살짝 개선되는지 살피면서, 조금씩 $\theta$를 변경하여, $\pi_\theta$ Policy를 개선시켜 나갑니다.
$\pi_\theta(a_t|s_t)$ Policy는 Deep Neural Network으로 구현하고 Input은 $s_t$이며 Output은 $a_t$의 확률분포를 표현하는 Normal Distribution의 $\mu_\theta(s_t)$ Mean과 $\sigma_\theta(s_t)$ Standard Deviation입니다. 학습 초반에는 어떤 Policy를 취하는 것이 유리한지 잘 모르기 때문에 $\sigma_\theta(s_t)$가 다소 큰 값이 나오면서 Exploration에 집중하고, 학습이 진행되면 조금씩 어떤 Policy를 취하는 것이 좋은지 확신이 생기기 시작하면서 $\sigma_\theta(s_t)$의 값이 점점 작아지며 Exploitation에 집중하게 됩니다.
REINFORCE with Baseline
$\nabla_\theta J(\pi_\theta)$의 $G_t(\tau)$를 다음과 같이 살짝 변형시켜서 성능을 향상시키는 기법을 REINFORCE with Baseline이라고 합니다.
\[\nabla_\theta J(\pi_\theta)=E_{\tau \sim \pi_\theta}\left[\sum_{t=0}^T (G_t(\tau)-b(s_t)) \nabla_\theta \ln \pi_\theta(a_t|s_t)\right]\]$b(s_t)$는 여러가지 형태로 지정해 줄 수 있으며 어떻게 지정하느냐에 따라 성능에 영향을 줍니다. 간단하게는 $b(s_t)=\frac{1}{T}\sum_{t=0}^T G_t(\tau)$로 지정할 수도 있습니다.
$G_t(\tau)$가 항상 Positive면 어느 State에서 어느 Action을 하는 것을 학습시키는 것이 바람직한지 다소 모호한 상황에 빠질 수가 있는데 이때 $b(s_t)=\frac{1}{T}\sum_{t=0}^T G_t(\tau)$로 지정해 주면 Trajectory에서 절반정도를 바람직한 Action으로 파악해서 적극적으로 학습시키는 것이 가능해 지면서 성능이 개선됩니다.
How to Solve Continuous Cart Pole with REINFORCE
Continuous Cart Pole을 REINFORCE을 사용하여 푸는 구체적인 방법은 reinforce.py를 참조하기 바랍니다.
Policy-based vs Value-based
Reinforcement Learning Algorithm을 분류하는 하나의 방법으로 Policy-based, Value-based가 있습니다.
REINFORCE와 같이 직접 $\pi$ Policy를 구하는 방법을 Policy-based라고 합니다.
Value Iteration, Q Learning, Deep Q Network와 같이 $V^\pi(s)$ 혹은 $Q^\pi(s,a)$를 구하는 방법을 Valued-based라고 합니다.
둘 다 장단점이 있으며, 두 가지의 장점을 모두 취하기 위해 Policy-based와 Value-based를 섞어서 쓰기도 합니다.
On-Policy vs Off-Policy
Reinforcement Learning Algorithm을 분류하는 하나의 방법으로 On-Policy, Off-Policy가 있습니다.
REINFORCE는 학습을 위해 $\tau$ Trajectory를 모을 때 $\pi_\theta$ Policy를 기반으로 모으고, $\pi_\theta$ Policy에서 $\theta$를 어떻게 살짝 변경해야 해당 $\tau$ Trajectory에서 $J(\pi_\theta)$ Objective가 얼마나 살짝 개선되는지를 살펴보고, 살짝 $\pi_\theta$ Policy를 개선합니다. 자세히 살펴보면 학습에 사용된 Trajectory는 해당 Trajectory를 생성한 Policy를 개선할 때만 유효하고 다른 Policy를 개선할 때는 사용이 불가능하다는 사실을 알 수 있습니다. 이런 이유로 $\pi_\theta$ Policy가 생성한 $\tau$ Trajectory는, $\pi_\theta$ Policy를 개선하기 위해 $\theta$를 한 번 변경하는데 사용되고 나면, 새로운 $\pi_\theta$ Policy를 개선하는데 더 이상 사용이 불가능해지는데, 이것을 On-Policy라고 합니다.
Deep Q Network와 같이 Policy를 변경하지 않으면서 $Q_\theta^\pi(s,a)$의 $\theta$만 변경하는 경우에는 이전에 모아두었던 학습용 Trajectory를 학습에 재활용하는 것이 가능합니다. 이와 같이 학습용 Trajectory를 $\theta$가 변경되더라도 재활용해서 쓸 수 있는 것을 Off-Policy라고 합니다.
On-Policy의 경우에는 Experience Replay를 사용할 수 없지만, Off-Policy의 경우에는 Experience Replay를 사용할 수 있어서, Off-Policy가 On-Policy에 비해 학습 데이터를 더 효율적으로 활용합니다.
Monte-Carlo Method vs Temporal Difference Method
Reinforcement Learning Algorithm을 분류하는 하나의 방법으로 Monte-Carlo(MC) Method, Temporal Difference(TD) Method가 있습니다.
REINFORCE에서 학습과정을 보면 $\nabla_\theta J(\pi_\theta)=E_{\tau \sim \pi_\theta}\left[\sum_{t=0}^T G_t(\tau) \nabla_\theta \ln \pi_\theta(a_t|s_t)\right]$ Objective를 구해야 하는데, 이것을 계산하기 위해 Episode 전체가 종료될 때까지 $\tau$ Trajectory를 $\pi_\theta$ Policy에 따라 직접 생성하기를 여러번 반복하여 평균을 계산합니다. 이와 같이 여러번 Sample해서 평균하는 방식을 Monte-Carlo Method라고 합니다.
Deep Q Network에서 학습과정을 보면 $L=\left[Q^{\pi}(s_t,a_t)-(r_t+\gamma \max_{a_{t+1}} Q^{\pi}(s_{t+1},a_{t+1}))\right]^2$ Loss를 구해야 하는데, 이것을 계산하기 위해 $\tau$ Trajectory에서 필요한 부분은 Episode 전체가 아니라 $s_t, a_t, r_t, s_{t+1}$입니다. 계산을 위해 Episode 전체가 끝날 때까지 기다릴 필요도 없습니다. 이와 같이 $\tau$ Trajectory상의 두 시점의 차이를 이용하는 방식을 Temporal Difference Method라고 합니다.
Conclusion
이 글에서는 Reinforcement Learning를 이해하는데 필요한 기초적인 내용을 설명하였습니다. Reinforcement Learning은 현재도 매우 활발하게 연구되고 있는 분야인 관계로 정보가 항상 많이 쏟아지고 있어서 Reinforcement Learning의 공부를 어디서부터 시작해야 좋을지 파악하기가 쉽지 않은 경우가 많은데, 그런 분들에게 이 글이 유용한 자료가 되었기를 바랍니다.
이 글에서는 이해를 돕기 위해 의도적으로 자세한 내용, 복잡한 내용, 최신 기법등을 포함시키지 않았으며 꼭 필요하다고 생각되는 최소한의 내용만을 포함하기 위해 노력하였습니다. 그런 관계로, 실제로 복잡한 문제를 여기에 소개된 Deep Q Network나 REINFORCE을 이용해서 풀려고 하면 잘 풀리지 않을 것으로 생각합니다.
만약에 복잡한 문제를 풀기 위한 비교적 최신 Model-free Algorithm에 관심이 있다면, Discrete Action의 경우에는 Deep Q Network을 개선시키는 각종 기법들을(Experience Reply, Target Network, Double DQN, Duel DQN, 등등) 찾아서 살펴보기를 추천드립니다. Continuous Action의 경우에는 TD3 혹은 SAC를 찾아서 살펴보기를 추천드리는데 혹시 내용이 이해가 잘 되지 않는다면 Actor Critic, A2C, DDPG를 차례로 찾아서 살펴본 후에 TD3와 SAC를 살펴보시기를 추천드립니다.