딥러닝 추천 모델에 인과추론 접목시켜 전환율 예측 성능을 향상시키자!
1. 서론
안녕하세요. AI팀 안준형입니다. 이번 포스팅에서는 추천시스템에서 인과추론을 어떻게 적용하는지 알아보겠습니다. 현재 대부분의 머신러닝 기반의 추천시스템은 입, 출력 간의 상관관계 (correlation)을 모델링합니다. 하지만, 현실 세계는 상관관계가 아닌 인과관계로 구성되어 있으며 상관관계가 인과관계를 반드시 암시하지 않습니다.
예시) 어떤 유저는 휴대폰을 구매한 다음 배터리 충전기를 구매하는 경우, 전자는 후자의 원인이 되지만 그 반대 방향은 성립되지 않습니다. 유저가 충전기를 먼저 구매한 다음에 휴대폰을 구매할 확률은 매우 적다고 볼 수 있습니다. 만약 우리가 상관관계만 모델링한다면 이러한 인과관계성을 포착할 수 없고 모델 성능이 떨어질 수밖에 없습니다.
따라서, 상관관계를 기반으로 모델링을 했을 때 많은 문제점이 발생하며 구체적인 내용은 아래와 같습니다.
2. 상관관계 기반의 추천시스템의 문제점
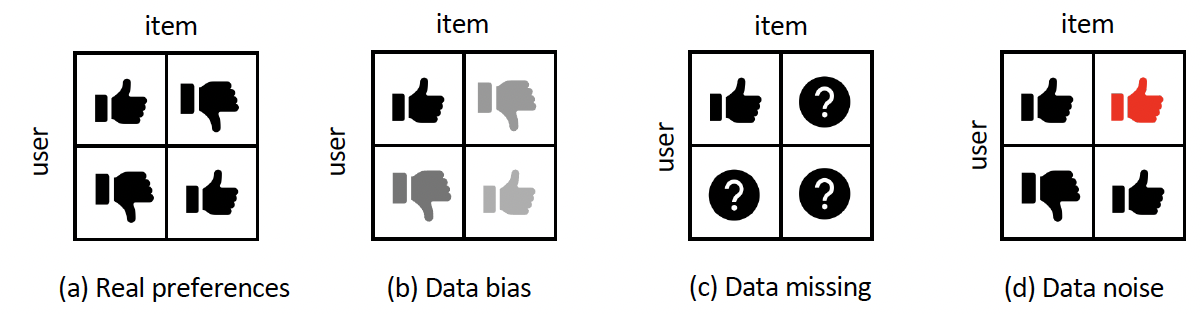
- 데이터 편향 (Data Bias): 우리가 실제로 관측 및 수집하는 데이터는 유저-아이템 상관관계를 포착하는 데이터로, 순응 편향 (conformity bias), 인기 편향 (popularity bias), 노출 편향 (exposure bias) 등 여러 종류의 편향을 포함합니다. (예시로 든 편향들에 대해서는 밑에서 더욱 자세하게 설명하겠습니다.) 이러한 데이터로 추천 모델을 학습하게 되면 낮은 추천 성능을 보이게 됩니다.
- 데이터 누락 혹은 노이즈 (Data Missing or Noise): 수집 파이프라인으로 인해 노이지하거나 완전치 못한 데이터를 얻게 됩니다. 예를 들어, 보통 유저들은 매우 작은 양의 아이템과 상호작용(클릭, 구매)하기 때문에 그 외에 수만 개의 아이템과의 상호작용은 관측되지 않습니다. 이를 데이터 누락이라 볼 수 있습니다. 그렇다면 수집한 데이터는 깨끗하냐? 실제로 그렇지 않고 노이즈가 많이 끼어있습니다. (예를 들어, 잘못 클릭했거나, 클릭했다고 해도 긍정적인 의미로 한 것이 아니라 부정적인 감정으로 했거나..) 자세한 내용은 아래에서 설명하겠습니다.
1) 문제점들을 구체적으로 알아보자
- 데이터 편향 (Data Bias)
-
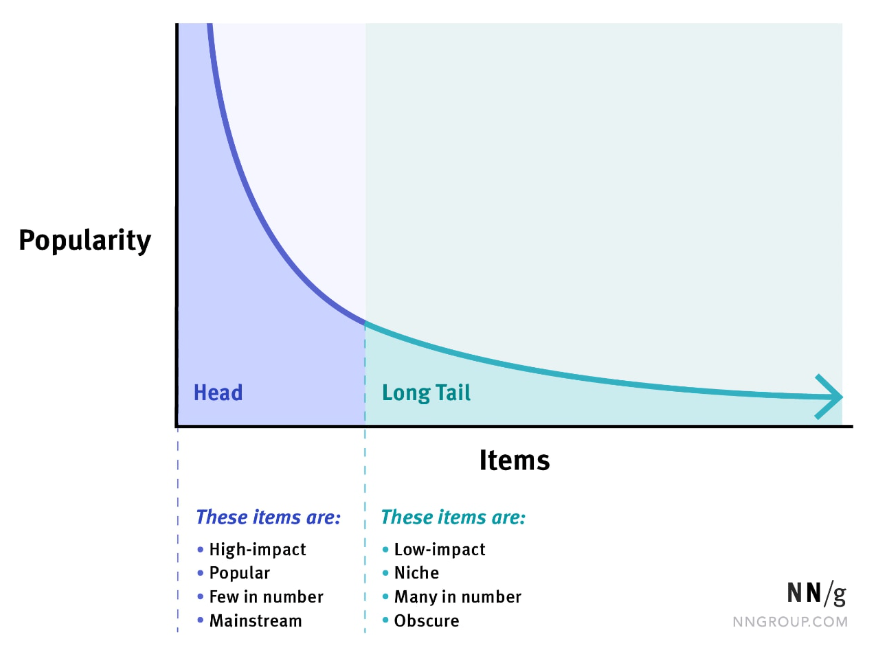
인기 편향 (popularity bias): 추천 시스템은 대개 사용자의 행동 기록을 기반으로 학습됩니다. 만약 특정 항목이 이미 많은 사용자에게 선호되어 선택되었다면, 해당 항목은 더 많은 클릭, 구매, 또는 평가를 받을 것이며, 이는 해당 항목을 더 많이 추천받게 됩니다. 보통 과거 행동 기록을 보면 long-tail 분포를 따르고 모델이 이를 학습하게되면 자주 상호작용하는 아이템에는 높은 추천 점수를 내뱉는 반면 다른 아이템에는 낮은 점수를 내뱉게 됩니다. 사용자가 추천된 인기 있는 항목을 선택하게 되면, 해당 항목은 더 많은 피드백을 받아 선호도가 높아지게 됩니다. 이로 인해 추천 시스템은 해당 항목을 더 자주 추천하게 되어 역순으로 피드백 루프가 형성될 수 있고 이는 다양성과 개인화 측면에서 문제가 될 수 있습니다.
- 순응 편향 (conformity bias): 사용자들이 다수의 의견이나 행동에 순응하려는 경향을 나타냅니다. 이러한 편향은 주로 소셜 커머스 플랫폼이나 리뷰 기반의 추천 시스템에서 나타나며 이 편향이 지속적으로 나타날 경우, 다양성과 개인화 측면에서 문제가 될 수 있습니다. 일부 사용자의 선호나 의견이 지배적으로 나타나면, 다른 사용자들은 그러한 다수의 흐름에 따라 선택하게 되어 자신만의 다양한 경험을 갖기 어려워집니다.
- 노출 편향 (exposure bias): 노출 알고리즘이 유저 피드백 수집에 영향을 끼칩니다.
-
-
데이터 누락 (Data Missing) 추천시스템이 활용하는 데이터는 대개 한정적이며 모든 유저-아이템의 상호작용을 확인할 수 없습니다. 예를 들어, 유저는 대개 적은 개수의 영화에만 평점을 매기거나, 카메라 구입했을 때 카메라 렌즈와 필름을 구매한 기록은 남지 않습니다. 그렇기 때문에, 관측되는 데이터가 실제로 유저의 모든 성향을 반영했다고 보기 힘듭니다. 이러한 데이터로 학습하게 되면 우리는 sub-optimal한 결과를 얻게 됩니다. 노출 편향에서 얘기했던 것처럼, 추천시스템의 아이템 노출 알고리즘으로 인해 유저는 특정 몇 개의 아이템에만 보게 되며, 대다수의 유저는 피드백 주는 걸 거부하는데, 이러한 현상은 Douban 이라는 영화 평점 웹사이트에서 확인할 수 있습니다. 이러한 요소들로 인해 유저의 선호도를 모델링하는 것이 쉽지 않게 됩니다. 우리는 인과추론을 통해 데이터 생성 매커니즘을 모델링할 수 있으며, 전문적으로 이를 Data Generating Process (DGP)라고 부릅니다. 이는 data-driven 모델에 사전지식으로 넣어줄 수 있고 이를 통해 데이터 누락 문제를 완화시킬 수 있습니다.
- 데이터 노이즈 (Data Noise) 추천시스템을 떠나서 다양한 도메인에서 얻게 되는 데이터에는 전부 노이즈가 포함됩니다. 예를 들어, 암시적 상호작용(implicit interaction)의 경우 유저가 특정 아이템을 클릭했다고 반드시 이를 긍정 레이블로 볼 수 없습니다. 실수로 잘못 클릭했다거나, 실제로 그 아이템을 클릭 및 구매 후에 부정적인 코멘트를 남길 수도 있습니다. 반대로, 유저가 노출된 아이템을 클릭하지 않았다고 이를 부정 레이블로 보는 것도 역시 위험합니다. 우리가 스크롤하다보면 알겠지만 모든 아이템을 다 보지 않고 스크롤을 내리는 경우가 많은데 그 중에서 유저가 실제로 선호할 아이템이 있을 수도 있습니다. 혹은, 악의적으로 노이즈를 만들어 내기도 하는데 TikTok에서는 본인의 컨텐츠를 과다 노출시키고 싶어서 많은 가계정을 생성한 후 클릭을 한다거나, Amazon의 경우 가짜 구매 기록 혹은 긍정 평가를 남긴다고 합다. 이러한 외부적인 요소들을 무시한 채로 그냥 관측된 데이터로 학습을 하게 되면 실제 유저의 선호도를 알아내기 힘들 것입니다. 그렇기 때문에 인과관계성을 알아내기 위해 인과추론 기법을 적용하는 것입니다.
3. 인과추론이 추천시스템에 필요한 이유
1) 데이터 문제가 발생하는 원인이 뭘까?
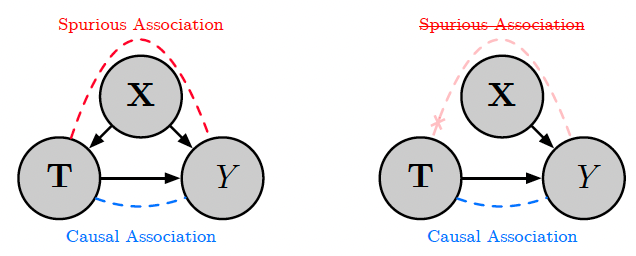
데이터 편향, 누락, 혹은 노이즈가 발생되는 원인은 backdoor path가 존재하기 때문입니다. Backdoor path를 다 설명하자면 매우 길기 때문에 간단하게만 설명하겠습니다. 우리는 보통 입력과 출력 사이의 진짜 인과적 상호작용 (causal association)만 관측하고 싶어합니다. 하지만,입출력 변수 사이에 backdoor path가 존재하게 되면 가짜 상호작용 (spurious association)이 발생하여 직접적인 인과 관계에 더해지고 그걸 우리가 관측하게 됩니다.
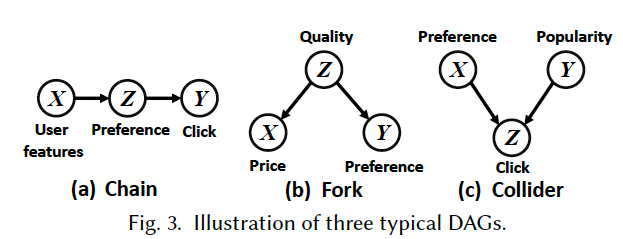
위 그림에서 (b)를 보면 Z가 X (입력)와 Y (출력)에 동시에 영향을 주고 있습니다. 이러한 backdoor path로 인해 가짜 상호작용이 발생하게 되고, 이로 인해 X와 Y 사이의 진짜 인과적 상호작용보다 더 overestimate된 X와 Y 사이의 관계를 우리는 관측하게 됩니다. 우리는 이러한 Z를 confounding bias, 혹은 confounder라고 부릅니다.
예를 들어, 아이템 인기도는 노출 확률에 영향을 주게 되는데 우리가 아이템 인기도를 고려하지 않으면 협업 필터링은 인기 있는 아이템에 지속적으로 높은 추천 점수를 부여하기 되고 양성 피드백으로 인해 over-recommendation 현상이 발생하게 됩니다. 이것이 위에서 언급한 인기 편향이며 여기서 아이템 인기도를 confounder라고 볼 수 있습니다.
인과추론 관점에서 보면 X를 treatment, Y를 outcome 변수라고 볼 수 있고, 우리가 실제로 원하는 것은 X가 Y에 다이렉트하게, 직접적으로 끼치는 영향만 보고 싶은 것입니다. 따라서, confounder로 인해 추가적으로 생성되는 영향을 제거해야 우리가 원하는 바를 관측할 수 있고 이러한 편향을 없앤 채로 데이터를 수집하고 추천 모델을 해당 데이터로 학습시키면 추천 모델도 편향을 안 갖게 됩니다. Confounder의 영향을 없애는 인과추론 방법은 여러가지가 존재합니다.
2) 이를 해결하는 인과추론 기법이 뭐가 있을까?
이 backdoor path를 없애는 인과추론 기법에는 대표적으로 Inverse Propensity Weighting (IPW)와 Doubly Robust (DR)이 있습니다.
-
Inverse Propensity Weighting (IPW)
Inverse Propensity Weighting는 관찰된 데이터에서 treatment effect (치료 효과)를 추정하는 데 사용되는 통계적 기법 중 하나입니다. 특히, 추천시스템에서는 exposure (노출)의 확률에 대한 역수를 가중치로 사용하여 편향을 보정하는 방법입니다. Inverse Propensity Weighting의 핵심 아이디어는 다음과 같습니다:
- 각 관찰된 데이터 포인트에 대해 treatment 또는 exposure의 확률을 예측합니다. 이 예측은 propensity score(경향 점수)라고도 합니다.
- 각 데이터 포인트에 대해 treatment 또는 exposure의 확률에 대한 역수를 계산하여 가중치로 사용합니다.
- 이 가중치를 사용하여 각 데이터 포인트의 결과를 조절하여 모델 학습에 사용합니다.
위에 기술한 것을 약간의 수학기호를 도입해서 설명하겠습니다. \(O\)를 노출여부를 나타내는 확률변수라고 정의하고 \(o_{u,i}=1\)을 아이템 \(i\)가 유저 \(u\)에 추천되었다는 걸 뜻하자고 합시다. \(\mathcal{O}\)는 exposure space라고 정의합시다. 또한, 유저-아이템 피드백을 \(y_{u,i} \in \{0,1\}\)이라 하고 그 예측값을 \(\hat{y}_{u,i}\)라고 합시다. 그때, IPW의 목적 함수는 아래와 같습니다.
\[\mathcal{L}_{\text{IPW}}= \frac{1}{|\mathcal{O}|}\sum_{(u,i) \in \mathcal{O}} \frac{o_{u,i} l(y_{u,i}, \hat{y}_{u,i})}{\hat{o}_{u,i}}\]여기서, \(\hat{o}_{u,i}\)은 propensity score로 유저-아이템 피드백 \(y_{u,i}\)를 관측할 확률을 뜻하며, \(l(\cdot, \cdot)\)은 손실 함수로 일반적으로 많이 사용하는 binary cross entropy라고 생각해주시면 될 것 같습니다.
위 수식을 쉽게 해석하자면, “클릭이 잘 될 것 같은 표본의 가중치는 줄여주고 클릭이 잘 되지 않을 것 같은 표본의 가중치는 늘려주자는 것”입니다. 이는 클릭이 잘 되는 샘플은 학습 데이터에 포함이 많이 되지만 반대의 경우에는 포함이 잘 안 되기 때문에, 희소한 데이터에 가중치를 더 주는 방식으로 학습시켜 표본 선택 편향 문제가 완화하고 있습니다.
-
Doubly Robust (DR)
하지만, 위 기법의 단점이라고 하면 propensity score를 추정하기 힘들 뿐더러, score가 매우 작은 값이 되어버리면 전체 목적함수가 매우 커지기 때문에 variance가 높다는 점입니다. 이를 보완하기 위해서 제안된 인과추론에서의 또 다른 기법이 Doubly Robust (DR) 기법입니다. 자세하게 설명하자면 복잡해져서 간단히만 말하면, 노출되지 않은 유저-아이템 쌍에 대해서도 에러 \(l(y_{u,i}, \hat{y}_{u,i})\)를 예측하는 손실 함수를 더해줘서 joint learning해주는 기법입니다. 전체 유저-아이템 쌍의 공간을 \(\mathcal{D}\)라고 정의하면, DR의 주 목적 함수는 아래와 같습니다.
\[\mathcal{L}_{\text{DR}}^{\text{err}}= \frac{1}{|\mathcal{D}|} \sum_{(u,i) \in \mathcal{D}} \left( \hat{e}_{u,i} + \frac{o_{u,i}( l(y_{u,i}, \hat{y}_{u,i}) - \hat{e}_{u,i})}{\hat{o}_{u,i}} \right)\]여기서, \(\hat{e}_{u,i}\)은 imputation (결측값 대체) 모델의 출력값으로 \(l(y_{u,i}, \hat{y}_{u,i})\)의 예측값이라고 생각해주시면 될 것 같습니다. 이 imputation 모델을 학습하기 위해서, joint learning을 통해 아래의 목적 함수도 동시에 최소화시킵니다.
\[\mathcal{L}_{\text{DR}}^{\text{imp}}= \frac{1}{|\mathcal{O}|} \sum_{(u,i) \in \mathcal{O}} \frac{(l(y_{u,i}, \hat{y}_{u,i}) - \hat{e}_{u,i})^2}{\hat{o}_{u,i}}\]따라서, 최종 목적 함수는 아래와 같습니다.
\[\mathcal{L}_{\text{DR}}= \mathcal{L}_{\text{DR}}^{\text{err}} + \mathcal{L}_{\text{DR}}^{\text{imp}}.\]
4. 전환율 예측
1) 전환율 예측 (CVR prediction)이란?
이번에는 구체적으로 인과추론이 사용되는 추천시스템의 한 도메인에 대해서 설명드리겠습니다. 현재 많은 추천 관련 도메인에서 인과추론 기법이 사용되고 있습니다. 대표적으로는 sequential recommendation, social recommendation, CTR & CVR prediction 등이 있습니다. 그 중에서 여기서 다룰 추천 도메인은 CVR prediction, 전환율 예측입니다.
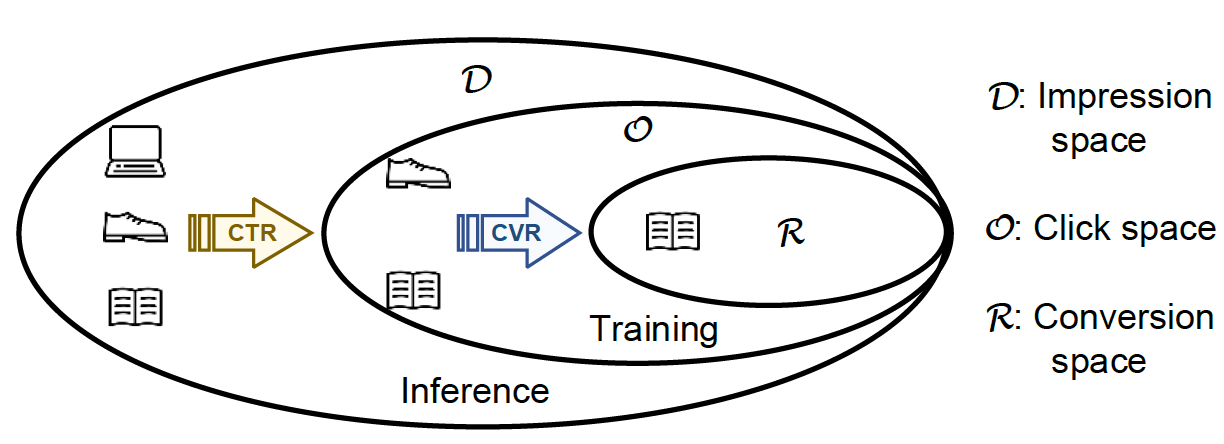
온라인 이커머스 시장에서의 전환율 예측은 소매업체나 이커머스 플랫폼이 온라인 사용자의 행동을 분석하여 해당 사용자가 제품을 구매할 가능성을 예측하는 것을 의미합니다. 전환율은 웹사이트 방문자가 실제로 제품을 구매하는 비율을 나타내며, 이는 온라인 판매와 마케팅 전략을 평가하고 최적화하는 데 중요한 지표입니다. 전환율 예측이 온라인 이커머스 시장에서 매우 중요한 이유는 아래와 같습니다.
- 마케팅 효율성 향상: 올바른 전환율 예측을 통해 기업은 광고 예산을 효율적으로 할당할 수 있습니다. 더 나은 예측은 광고 예산을 더 많은 잠재 고객에게 투입하고 마케팅 캠페인의 성과를 최대화할 수 있습니다.
- 매출 증대: 전환율 예측은 고객이 제품을 구매할 가능성을 더 정확하게 예측할 수 있도록 도와줍니다. 이는 매출을 증가시키고 기업의 수익성을 향상시킬 수 있습니다.
- 고객 경험 개선: 전환율 예측은 고객의 구매 패턴과 행동을 이해하는 데 도움을 줍니다. 이를 통해 기업은 고객에게 보다 맞춤화된 제품 및 서비스를 제공하고 사용자 경험을 개선할 수 있습니다.
일반적으로, 유저 액션은 다음의 순차적인 패턴을 따릅니다: 노출 (impression) → 클릭 (click) → 전환 (conversion). CVR은 “클릭 후 전환율”을 뜻하며, 아래와 같이 정의됩니다.
\[CVR = p(\text{conversion} | \text{click}).\]2) 전환율 예측의 문제점
전환율을 정확히 예측하는 데에 있어 문제점이 크게 2가지가 존재합니다.
-
표본 선택 편향 (Sample Selection Bias)
샘플 선택 편향(sample selection bias)은 통계적 분석이나 모델링에서 주어진 데이터가 모집단을 대표하지 못하고 특정한 부분집합에 편향되어 있는 경우를 말합니다. 이는 데이터가 수집되는 과정에서 발생할 수 있으며, 이러한 편향이 존재하면 모델의 결과가 신뢰할 수 없게 될 수 있습니다.
-
데이터 희소성 (Data Sparsity)
데이터 희소성은 용어 그대로 모델을 학습하거나 예측할 때 사용 가능한 데이터가 제한되어 있는 상황을 가리킵니다. 특히, 전환율 예측 도메인에서 이 문제가 더욱 대두되는데, 그 이유는 전환이라는 사건이 클릭 후 발생하게 되는데 클릭량도 적고 이는 모델이 정확한 예측을 만들기 어렵게 만들 수 있습니다.
5. 인과추론 기법으로 전환율 예측 성능 향상시키기
1) Multi-Task Learning (MTL)
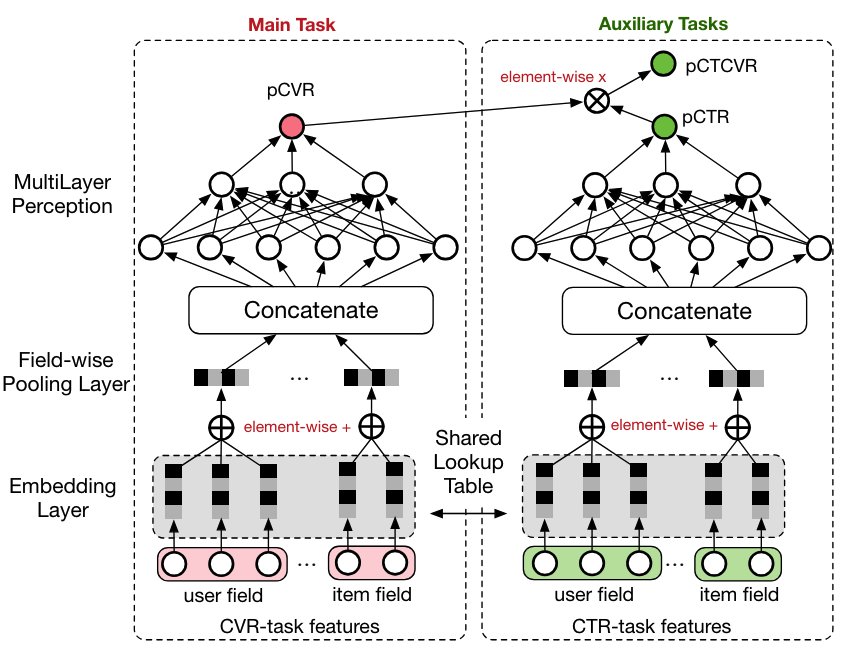
위에서 언급한 표본 선택 편향과 데이터 희소성을 해결하기 위해 2018년 Alibaba는 multi-task learning을 도입한 “Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate” 논문을 SIGIR에 게재했습니다. 위 그림에서 알 수 있듯이 CTR 예측 타워와 CVR 예측 타워를 각각 빌드하고, 아래의 손실 함수로 모델을 학습합니다.
\[\mathcal{L}_{ESMM} = \mathcal{L}_{CTR} + \mathcal{L}_{CTCVR}.\]여기서, CTCVR은 CTR x CVR을 뜻하며, \(\mathcal{L}_{CTR}\)은 클릭 레이블과 CTR 예측값 사이의 binary cross entropy입니다. 그렇다면, \(\mathcal{L}_{CTCVR}\)은 클릭x전환 레이블과 CTCVR 예측값과의 binary cross entropy가 되겠죠? 위 모델은 아주 간단한 방법으로 표본 선택 편향과 데이터 희소성 문제를 완화시켰습니다.
2) MTL에 인과추론을 접목시키기
하지만, 아직 추후 연구들을 통해 위의 모델도 표본 선택 편향을 완벽히 해결하지 못했다는 것이 밝혀졌습니다. 이 문제를 더욱 완화하기 위해 multi-task learning에 인과추론 기법을 적용한 논문들이 게재됐습니다.
대표적으로 Ant Group에서 SIGIR’22에 게재한 “ESCM2: Entire Space Counterfactual Multi-Task Model for Post-Click Conversion Rate Estimation” 논문이 있습니다.
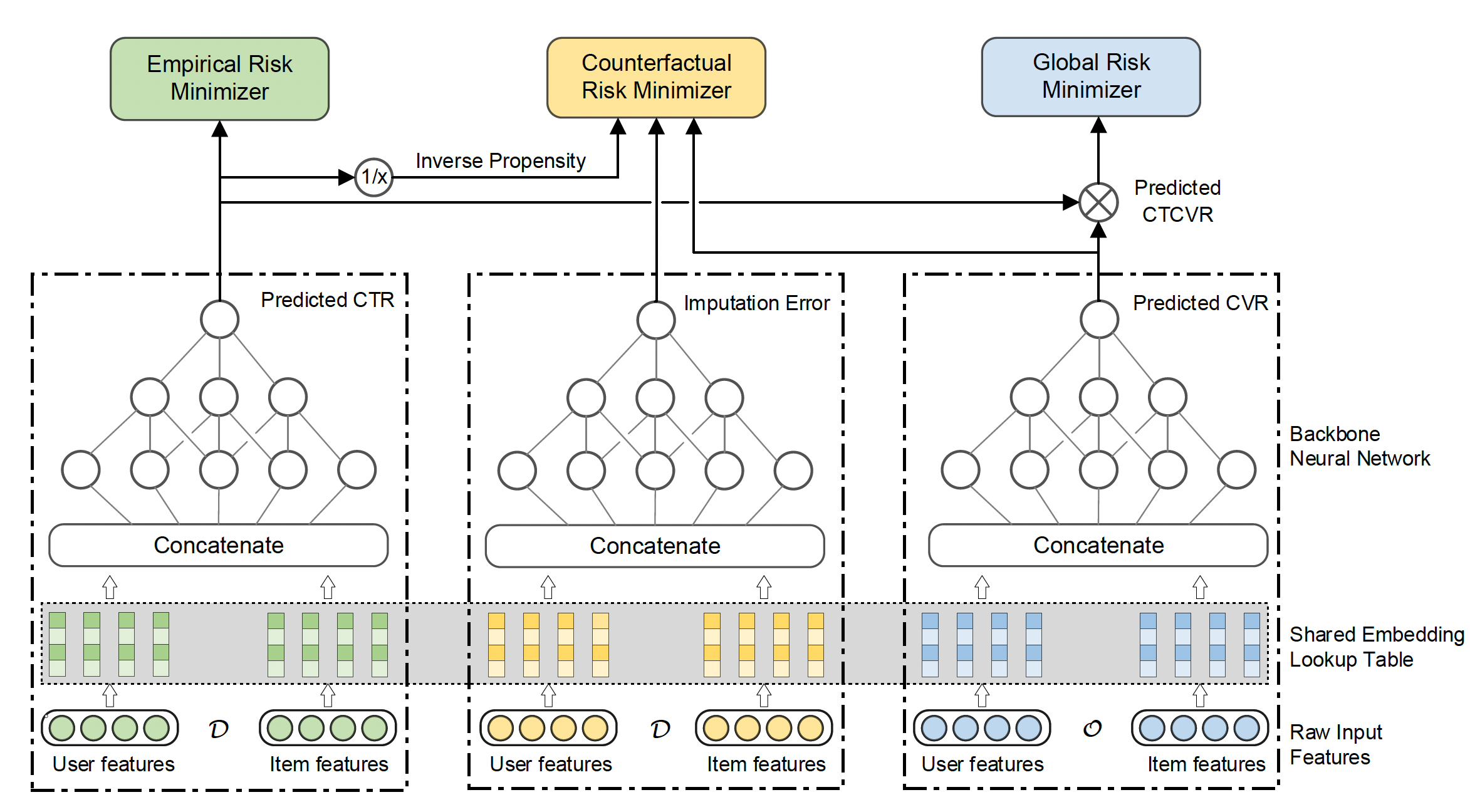
❓ 어떻게 인과추론 기법을 적용했을까?
위에서 언급한 Inverse Propensity Weighting (IPW) 기법을 사용했습니다.
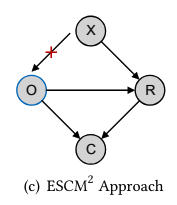
\(X\) (feature)가 \(O\) (click)에서 \(R\) (conversion)의 인과성 사이에 confounder로 작용한다고 보고있어서 \(X\)가 \(O\)에 미치는 인과성을 제거, 즉 backdoor path를 없앴습니다. 이때, backdoor path를 없애는 방법으로 Inverse Propensity Weighting (IPW), 혹은 Doubly Robust (DR) 기법을 사용했고 위에서 정의한 IPW, DR loss를 CVR loss로 정의한 것입니다.
\[\mathcal{L}_{CVR-IPS} = \frac{1}{|\mathcal{O}|}\sum_{(u,i) \in \mathcal{D}} \frac{o_{u,i} l(y_{u,i}, \hat{y}_{u,i})}{\hat{o}_{u,i}}\] \[\mathcal{L}_{CVR-DR} = \frac{1}{|\mathcal{D}|} \sum_{(u,i) \in \mathcal{D}} \left( \hat{e}_{u,i} + \frac{o_{u,i}( l(y_{u,i}, \hat{y}_{u,i}) - \hat{e}_{u,i})}{\hat{o}_{u,i}} \right) + \frac{1}{|\mathcal{O}|} \sum_{(u,i) \in \mathcal{O}} \frac{(l(y_{u,i}, \hat{y}_{u,i}) - \hat{e}_{u,i})^2}{\hat{o}_{u,i}}\]위 모델 그림에서 imputation tower는 \(\mathcal{L}_{CVR-DR}\)로 학습할 때 사용되며 \(\mathcal{L}_{CVR-IPS}\)로 학습한다고 하면 이 모델은 사용되지 않습니다. 그리고 counterfactual risk minimizer가 CVR loss라고 보시면 됩니다. 그렇다면, 이 모델의 최종 손실 함수는 아래와 같습니다.
\[\mathcal{L}_{ESCM^2-IPS}=\mathcal{L}_{CTR}+\mathcal{L}_{CTCVR}+\alpha\mathcal{L}_{CVR-IPS}.\] \[\mathcal{L}_{ESCM^2-DR}=\mathcal{L}_{CTR}+\mathcal{L}_{CTCVR}+\alpha\mathcal{L}_{CVR-DR}.\]여기서, \(\alpha\)는 CVR loss의 크기를 조절하는 하이퍼파라미터입니다.
6. 결과
벤치마크 데이터셋에 적용한 결과는 아래와 같습니다. 각각의 표는 CVR과 CTCVR 예측 성능을 나타내고 있습니다.
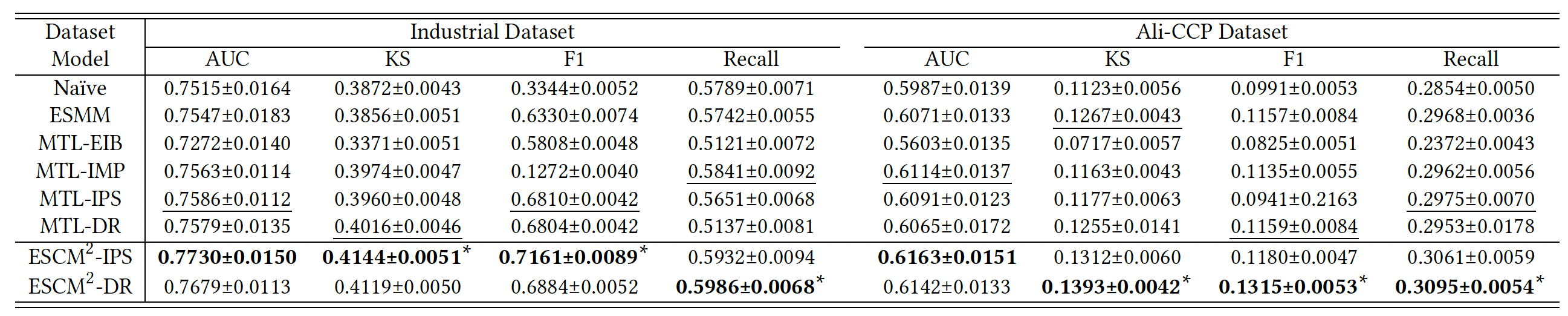
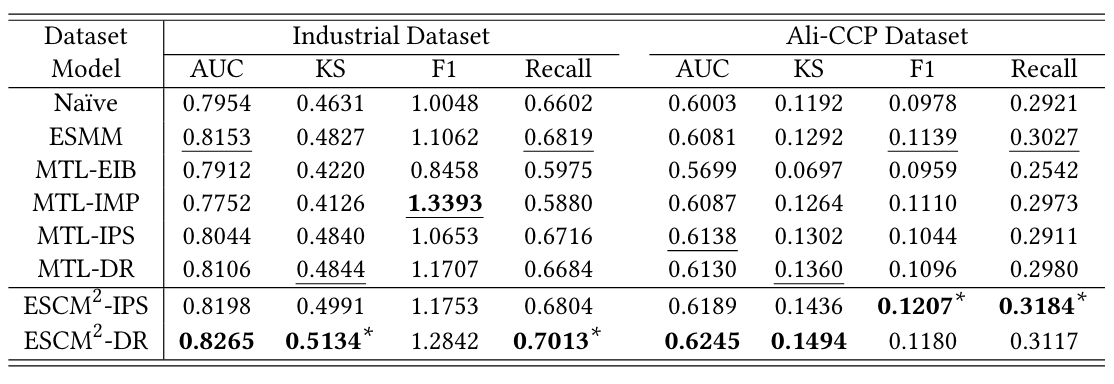
또한, 저자들은 자체 플랫폼을 통해 온라인 A/B 테스트도 진행했고 주요 KPI 지표 모두 우수한 성능을 보였다고 합니다.
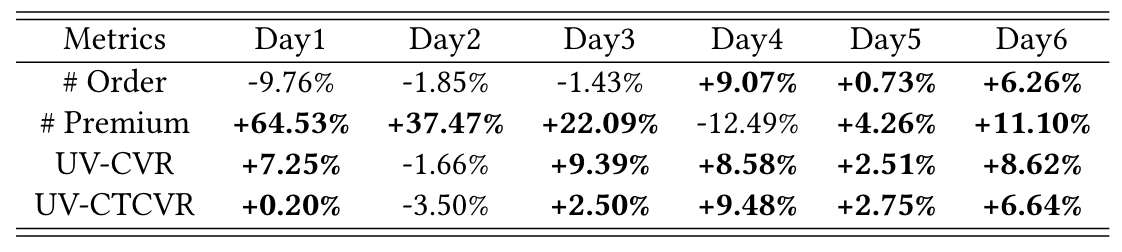
해당 모델을 데이블이 보유한 플랫폼에도 deploy를 해봤고 더욱 향상된 성능을 보여줬습니다.
7. 마무리
이번 글에서는 현재 대부분의 상관관계 기반 추천모델이 어떤 문제점을 가지고 있고, 인과추론이 어떻게 이러한 문제점들을 해결하고 있으며, 구체적으로 전환율 예측 도메인에서 어떻게 인과추론이 적용되고 있는지 알아봤습니다. 사실 복잡한 내용을 하이 레벨에서 설명했기 때문에 구체적인 내용을 파악하기 힘드셨을 수도 있을 것 같은데 그냥 대강 “아 이러한 문제점들이 있구나, 인과추론 기법에 대표적으로 뭐가 있구나” 정도로만 이해해주시길 바랍니다.
추가적으로 설명하자면, 데이블 AI팀은 위 5장에서 설명한 방법론에도 많은 한계점이 있다는 것을 발견했고, 이를 해결하여 새로운 방법론을 제시했습니다. 이 방법을 사용했을 때 기존의 방법보다 더욱 뛰어난 예측 성능을 보였습니다. 현재 논문 투고를 준비하고 있으며 투고 후 더욱 자세한 내용을 다루도록 하겠습니다.
참고 문헌
위의 그림들은 아래 링크 및 논문에서 가져왔습니다.
- Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
- ESCM2: Entire Space Counterfactual Multi-Task Model for Post-Click Conversion Rate Estimation
- Causal Inference in Recommender Systems: A Survey and Future Directions
- Recognize Strategic Opportunities with Long-Tail Data