CPU, GPU, and TensorFlow
안녕하세요. 오태호입니다.
이번 글에서는 CPU와 GPU의 차이를 살펴보고 TensorFlow를 사용하여 GPU를 어떻게 이용할 수 있는지 살펴보도록 하겠습니다. 이 글을 통해 GPU를 최대한 활용하는데 조금이라도 도움이 되었으면 좋겠습니다.
CPU의 특징
CPU(Central Processing Unit)는 우리가 사용하는 컴퓨터에서 계산을 담당하는 가장 중요한 부품입니다. PC에서는 Intel이나 AMD의 제품이 주로 사용되며, Mobile 기기에서는 ARM의 제품이 주로 사용됩니다.
CPU에서 제시하는 스펙을 살펴보면 (3.1GHz와 같은) Clock Speed가 있습니다. 100Hz의 Clock Speed를 가지는 CPU는 1초에 100번의 작업을 한다는 뜻이고, Clock Speed가 높다는 것은 같은 시간 내에 더 많은 작업을 한다는 뜻입니다. 복잡한 작업에는 시간에 오래 걸리고 단순한 작업에는 시간이 짧게 걸리기 때문에, 작업이 단순하면 단순할수록 Clock Speed를 높이기가 쉽습니다. 그래서 CPU 제조사들은 복잡한 작업을 최대한 단순한 작업으로 쪼개는 노력을 해 왔습니다. 여기서 조금 이상한 점을 하나 느끼셨을 것입니다. 복잡한 작업을 할 때는 Clock Speed가 10Hz고, 복잡한 작업을 단순한 작업 10개로 나눠서 Clock Speed를 100Hz로 높일 수 있다고 해도, 결국 복잡한 작업을 1개 수행할 때 소요되는 시간은 동일합니다. 즉, Clock Speed는 높아졌지만 실익은 없습니다.
복잡한 작업을 단순화시켜서 얻을 수 있는 이익을 CPU에서 실제로 발생하는 일을 직접 설명하면 이해가 어려울 수 있으니 좀 더 쉽게 이해할 수 있도록 자동차 공장에 비유해서 설명해 보도록 하겠습니다. 자동차를 만드는 작업은 매우 복잡한 작업이고 자동차 한 대를 만들기 위해서는 상당히 많은 시간이 듭니다. 자동차를 만드는 복잡한 작업 1개를 단순한 작업 3개로 쪼개서 한 작업의 시간을 1/3로 단축했다고 생각해 봅시다. 작업 하나 하나에 드는 시간이 1/3로 작아졌지만, 결국 자동차를 완성하기 위해서는 3개의 단순한 작업이 필요하기 때문에, 자동차 자동차 부품이 공장에 공급되고 그 부품이 자동차로 완성되어서 나오는데까지 걸리는 시간은 결국 동일해서, 복잡한 작업을 단순한 작업 3개로 쪼갠 것이 어떤 의미가 있는지 이해가 잘 되지 않을 것입니다. 하지만 잘 살펴보면 자동차 제조를 차체조립, 부품설치, 페인트칠로 나누면 첫번째 자동차를 차체조립 작업을 하고 부품설치 작업으로 넘기면 첫번째 자동차가 부품설치 작업을 하고 있는 동안에 두번째 자동차의 차체조립을 진행할 수 있습니다. 즉, 자동차 부품이 공장에 공급되고 그 부품이 자동차로 완성되어서 나오는데까지 걸리는 시간은 동일하지만, 시간당 생산되는 자동차의 양은 3배가 됩니다. CPU에서는 이런 방식을 Pipeline이라고 부르고, 쪼개진 단순한 작업들은 Pipeline Stage라고 부르고, 복잡한 작업이 시작되어서 끝나서 결과물이 나오는데까지 걸리는 시간을 Latency라고 부르며, 시간당 작업처리량을 Throughput이라고 부릅니다. 자동차 공장으로 비유하면 Latency는 자동차 부품이 공장에 공급되고 그 부품이 자동차로 완성되어서 나오는데까지 걸리는 시간이며, Throughput은 시간당 생산되는 자동차의 양입니다. 쉽게 이해할 수 있겠지만 자동차 공장에서는 Latency가 매우 길지만 Throughput은 매우 높으며 동일한 원리가 CPU에도 적용될 수 있습니다. CPU의 복잡한 작업을 단순한 작업으로 쪼개서 Pipeline Stage의 수를 늘리면 늘릴수록 Throughput이 높아지기때문에 CPU 제조사들은 Pipeline Stage를 최대한 늘리기 위해 노력을 해 왔고 현재 많이 사용되는 CPU는 대략 20개 정도의 Pipeline Stage를 가지고 있습니다.
CPU에서 제시하는 또 다른 스펙중에 하나는 Core의 수가 있습니다. Octa-Core는 Core가 8개가 있다는 뜻이며 물리적으로 CPU가 8개가 장착되어 있어서 8가지 작업을 동시에 작업을 수행하고 시간당 수행하는 작업의 수도 8배가 됩니다. 자동차 공장에 비유하면 자동차의 생산라인의 수에 비유할 수 있습니다. 자동차의 생산라인의 수가 1개에서 8개가 되면 시간당 생산되는 자동차의 양은 8배가 됩니다. CPU의 Core의 수를 늘리면 늘릴수록 Throughput이 높아지기때문에 CPU제조사들은 Throughput을 최대한 높이기 위해 노력해 왔고 현재 많이 사용되는 CPU는 대략 수개에서 수십개정도의 Core를 가지고 있습니다.
CPU가 최대한 많은 작업을 빠르게 수행하기 위해서는 Pipeline Stage의 수를 최대한 늘리고 Core의 수를 최대한 늘리면 될 것으로 보입니다. 하지만 이것이 생각처럼 쉽지 않습니다. CPU에서는 매우 다양한 종류의 작업을 수행하는데, 이 각각의 작업을 작은 작업으로 잘개 쪼개서 수행하다보면, 이전 작업이 전부 끝나기 전에 다음 작업을 시작해야 하는데 이것이 작업의 특성에 따라 만만치 않은 경우가 많이 있기 때문입니다. 예를 들어 다음과 같은 간단한 Code를 보더라도 a > 1인지 그렇지 않은지 판단이 이루어지기 전에 b = a - 1을 실행하던가 b = a + 1을 실행해야 합니다.
if (a > 1) {
b = a - 1;
} else {
b = a + 1;
}
간단한 해법으로는 a > 1인지 판단이 이루어질 때까지 다음 작업의 시작을 미루는 방법이 있겠지만, 그렇게 하면 성능을 위해 Pipeline Stage의 수를 늘린 이점이 사라져버립니다. 이를 극복하기 위해 일단 모르겠지만 실행해 보고 나중에 아닌 것으로 밝혀지면 실행을 취소하는 기법도 사용하긴 합니다. 무수히 많은 각종 작업의 조합을 살펴보면 Pipeline Stage의 수를 늘리는 것이 만만치 않은 경우가 많습니다. CPU의 Core의 수를 늘리는 경우도 각각의 CPU가 (GPU에 비해) 상당히 복잡한 작업을 하기 때문에 Core의 수를 많이 늘리는 것이 쉽지가 않습니다.
GPU의 특징
GPU(Graphics Processing Unit)는 아주 단순하게 설명해 보면 크게 두 부분으로 구성되어 있습니다. 하나는 Vertex Processor이고 다른 하나는 Fragment Processor입니다.
Vertex Processor에는 Triangle(Polygon) 들이 입력되고 변환된 Triangle 들이 출력됩니다. 변환된 Triangle의 의미는 3차원 공간상의 Camera의 위치의 변화 등으로 인해 위치가 변경된 Triangle을 의미합니다. 참고로 GPU는 무엇을 그리던지 기본적으로 Triangle을 조합해서 그립니다.
Fragment Processor에는 Vertex Processor의 출력물인 변환된 Triangle이 입력되고 변환된 Triangle의 내부의 Pixel을 출력합니다. 즉, 변환된 Triangle의 내부를 색칠합니다. Triangle의 Vertex(꼭지점)들의 색을 구한 다음에 내부를 중간값으로 색칠해 주는 역할을 합니다.
Vertex Processor는 대량의 많은 Triangle의 위치를 빠르게 변환하는 작업만을 수행합니다. 첫 번째 Triangle이 어떻게 변환되었느냐라는 정보가 두 번째 Triangle이 어떻게 변환되어야 하는가에 전혀 영향을 주지 않습니다. 그래서 Vertex Processor의 Pipeline Stage의 수를 극단적으로 많이 늘릴 수 있으며, Vertex Processor의 Pipeline의 수도 극단적으로 많이 늘릴 수 있습니다. Fragment Processor도 마찬가지로 첫 번째 Pixel이 어떤 색으로 색칠되었는지가 두 번째 Pixel이 어떤 색으로 색칠되어야 하는가에 전혀 영향을 주지 않습니다. 그래서 Vertex Processor와 마찬가지로 Pixel Processor도 Pipeline Stage의 수와 Pipeline의 수를 극단적으로 많이 늘릴 수 있습니다.
OpenGL 1.x시절에는 Vertex Processor와 Fragment Processor가 고정된 기능을 제공하고 Parameter만 바꿔가며 사용하는 형식으로 GPU가 구성되어 있었습니다. 그래서 만약에 기존 OpenGL API로 구현이 불가능한 아주 특이한 3D효과를 내기 위해서 GPU 제조사마다 자신의 고유의 기능을 Vertex Processor와 Fragment Processor에 추가하고 해당 기능을 사용할 수 있는 확장 API를 제공했습니다. 이런 식으로 많은 GPU 제조사마다 표준에 맞지 않는 기능을 많이 추가하면서 혼란이 가중되자 새로운 움직임이 나타나기 시작했습니다. Vertex Processor와 Fragment Processor의 기능을 고정하지 말고 Programmable하게 만들자는 움직임이 나타났고, OpenGL 2.0에서 결국 Vertex Processor는 Vertex Shader를 이용해, Fragment Processor는 Fragment Shader를 이용해 Programmable하게 되었습니다. 시간이 더 흐르자 Vertex Processor하고 Fragment Processor는 결국 둘 다 결국 계산하는 Processor니까 두 가지를 합치자는 움직임이 나오고(Unified Shader), Programming이 가능한 Processor인데 이걸 굳이 그림 그리는 데만 쓸 이유가 있을까 라는 움직임이 나오면서 OpenCL, CUDA같은 API를 통해 GPU를 그림 그리는 용도가 아닌 일반 계산에 사용할 수 있게(GPGPU) 되었습니다.
현재는 GPU에서 일반적인 Program을 돌릴 수 있게 되었지만 Pipeline Stage의 수와 Pipeline의 수를 극단적으로 크게 유지하기 위해서는 여러가지 제약사항이 있습니다. 쉬운 이해를 위해 제약사항을 실제보다 다소 과격하고 간단하게 설명한다면, loop나 if같이 비교를 하고 분기하는 구문을 사용하지 않고 최대한 Matrix(행렬) 연산을 사용하여 Program을 작성해야 합니다. 보통 많이 사용하는 방법으로는 GPU에 Program을 Load한 뒤 Program을 변경없이 고정시키고 GPU에 Input으로 Data를 쏟아넣고 Output으로 쏟아져 나오는 Data를 받는 방법으로 사용합니다. GPU에 Input으로 Data를 쏟아넣으면 GPU의 극단적으로 큰 Pipeline Stage의 수와 Pipeline의 수를 최대한 활용하여 최대한 병렬적으로 연산이 이루어지고 Output으로 Data가 쏟아져 나옵니다. 만약에 GPU에 Load한 Program을 변경하고자 한다면 일단 GPU의 Pipeline에 들어 있는 모든 Data가 쏟아져 나올 때까지 기다린 후에 변경해야 합니다. 참고로 Pipeline의 Stage의 수가 매우 많기 때문에 Latency가 매우 긴 관계로, Program의 변경이 자주 있게 되면 상당한 비효율이 발생하게 됩니다.
CPU와 GPU의 비교
지금까지 설명한 CPU와 GPU의 특징을 요약하여 비교해 보면 아래 그림과 같이 나타낼 수 있습니다.
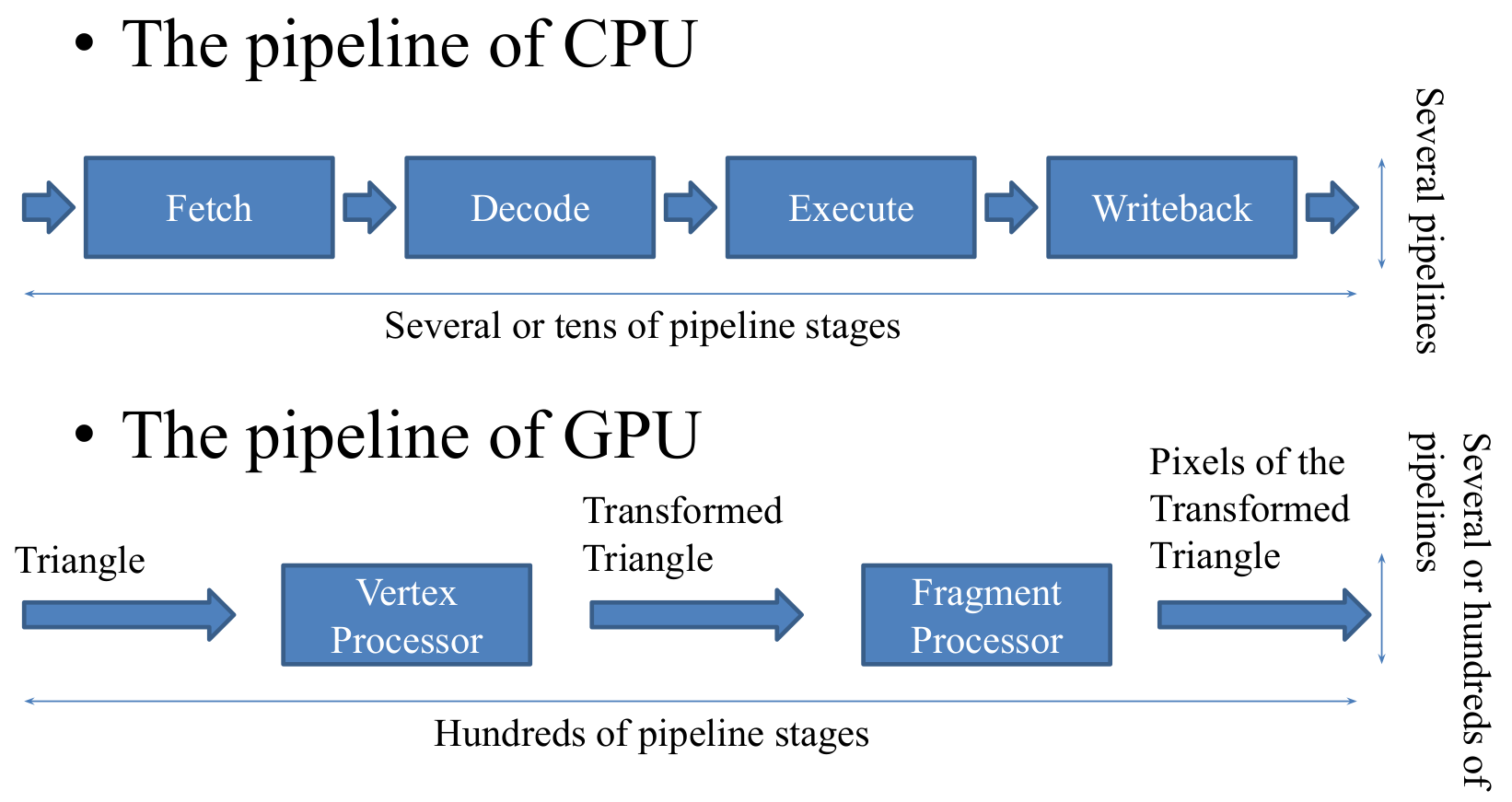 이 그림은 제가 2011년에 사용한 다소 오래된 발표자료의 일부인 관계로 Pipeline의 수가 다소 적게 표현되어 있는 점을 참고해 주시기 바랍니다.
이 그림은 제가 2011년에 사용한 다소 오래된 발표자료의 일부인 관계로 Pipeline의 수가 다소 적게 표현되어 있는 점을 참고해 주시기 바랍니다.
CPU는 복잡한 프로그램을 작동시키는데 적합하며, Pipeline Stage의 수는 보통 수십개이고, Pipeline의 수는 보통 수개에서 수십개입니다.
GPU는 단순한 프로그램을 대용량의 데이터에 대해 작동시키는데 적합하며, Pipeline Stage의 수는 보통 수백개이고, Pipeline의 수는 보통 수천개입니다.
TensorFlow를 이용한 GPU의 활용
어떤 사람들은 TensorFlow로는 Machine Learning만을 하는 것으로 생각하는데, 사실 Machine Learning과 전혀 상관없이 아주 간편하게 GPU를 활용한 고속병렬계산을 하는 용도로도 사용할 수 있습니다.
여기서는 최대한 간단하게 TensorFlow에서 GPU를 활용하는 것을 보이기 위해 현재는 TensorFlow에서 권장하지 않는 TensorFlow 초창기에 많이 사용했던 Low Level한 방법을 사용해 보도록 하겠습니다. 최신 버전 TensorFlow에서는 각종 Warning이 발생하거나 API가 사라져서 아예 작동하지 않을 수도 있으니 혹시 작동하지 않는다면 구버전 TensorFlow를 설치해서 사용해 보시기 바랍니다. 참고로 필자가 TensorFlow 1.14.0 버전을 사용해서 테스트해 보았을 때 Warning Message와 함께 작동되는 것을 확인할 수 있었습니다.
다음과 같은 Python Code를 실행시켜 보면
import numpy as np
import tensorflow as tf
x_input = tf.placeholder(tf.float32)
theta0_var = tf.Variable(-0.13)
theta1_var = tf.Variable(1.5)
y_output = theta0_var + theta1_var * x_input
print('x_input', x_input)
print('theta0_var', theta0_var)
print('theta1_var', theta1_var)
print('y_output', y_output)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
x_data = np.array([0.20, 0.50, 0.60, 0.85, 0.90])
print('x_data', x_data)
y_data = sess.run(y_output, feed_dict={x_input: x_data})
print('y_data', y_data)
다음과 같은 결과가 출력됩니다.
x_input Tensor("Placeholder:0", dtype=float32)
theta0_var <tf.Variable 'Variable:0' shape=() dtype=float32_ref>
theta1_var <tf.Variable 'Variable_1:0' shape=() dtype=float32_ref>
y_output Tensor("add:0", dtype=float32)
x_data [0.2 0.5 0.6 0.85 0.9 ]
y_data [0.17000002 0.62 0.77000004 1.1450001 1.2199999 ]
Code의 주요 부분을 살펴보도록 하겠습니다.
x_input = tf.placeholder(tf.float32)를 통해 GPU에 Input으로 Data를 쏟아부을 입구를 정의합니다. x_input을 통해 GPU에 Input으로 Data를 쏟아부을 예정입니다.
y_output = theta0_var + theta1_var * x_input을 통해 GPU에서 실행할 Program을 정의합니다. TensorFlow에서는 이것을 Computation Graph라고 부릅니다. Code만 보면 실제 계산을 하는 것처럼도 보이지만 실제로 계산이 이루어지지는 않으며 어떻게 계산을 수행하라는 계산식을 의미합니다. 이것은 GPU에서 실행할 Program을 의미합니다. 실제로 print를 해 봐도 계산된 결과가 아닌 알아보기 힘든 이상한 정보가 출력됩니다. 이 Program은 GPU에 Load하고 실행중에는 수정하지 않습니다.
tf.Session()을 통해 GPU에서 실행할 Program을 GPU에 Load합니다.
sess.run(tf.global_variables_initializer())을 통해 GPU에서 실행할 Program의 설정값에 해당하는 theta0_var, theta1_var을 초기화합니다.
y_data = sess.run(y_output, feed_dict={x_input: x_data})을 통해 GPU Input으로 정의한 x_input에 x_data를 쏟아붓고 y_output을 GPU의 Output으로 사용하여 쏟아져 나온 Output Data를 y_data에 저장합니다.
x_data = np.array([0.20, 0.50, 0.60, 0.85, 0.90])와 같이 GPU에 Input으로 쏟아부었는데, 살펴보면 0.20을 Input으로 한 계산결과값은 0.50을 Input으로 한 계산결과값에 영향을 주지 않습니다. 그래서 GPU의 Pipeline을 최대한 활용할 수 있습니다. 여기서는 간단하게 보여주기 위해 Data를 5개만 넣어 주었지만 GPU의 Memory가 허용하는 한도 내에서 매우 많이 넣어줄 수도 있습니다. GPU의 Program도 y_output = theta0_var + theta1_var * x_input와 같이 이해를 돕기 위해 간단하게 작성하였는데 상당히 복잡한 계산식을 넣어도 GPU의 Pipeline을 최대한 활용해 효율적으로 계산이 이루어지게 됩니다.
앞에서 설명드린 GPU의 특징을 바탕으로 살펴보면서, 이 Code를 활용해서 여러가지 복잡한 것을 해 보려고 생각해 보면, 이 Code가 다소 비효율적으로 작동될 수 있다는 것을 살펴볼 수 있습니다. 일단 첫 번째로 y_data = sess.run(y_output, feed_dict={x_input: x_data})이 부분을 보면 x_data를 GPU에 Input Data로 보내고 y_data에 GPU로부터 Output Data를 저장하는데 Output Data가 y_data에 저장되었다는 것은 이미 GPU의 Pipeline이 비어버렸다는 뜻입니다. 즉, GPU의 Pipeline을 꽉꽉 채워서 GPU가 쉬지않고 움직이게 하기 위해서는 y_data에 GPU로부터의 Output Data가 저장되기 한참 전에 다음 x_data를 GPU에 Input Data를 보내야 합니다. 이것을 위해 TensorFlow의 Queue기능(혹은 더 발전된 기능)을 사용해야 합니다. 즉, GPU에 Input으로 쏟아부을 Data를 미리 지정해 놓아서 Pipeline에 조금이라도 빈 공간이 생기면 GPU에 Data를 쏟아부어줘야 합니다. 그리고 두 번째로 만약에 도중에 theta0_var나 theta1_var를 변경하고자 한다면 이때도 GPU의 Pipeline을 비우고 나서 변경해야 하기 때문에 GPU가 비효율적으로 작동하게 됩니다. GPU의 Pipeline을 빈번하게 비워야 되도록 TensorFlow를 사용하게 되면 GPU를 활용했음에도 불구하고 GPU의 매우 긴 Latency로 인해 CPU를 사용했을 때보다도 성능이 좋지 않을 수 있으니 주의해야 합니다.
맺음말
요즘은 개발자의 편의성을 위해 GPU로 인한 여러가지 제약사항을 개발자가 의식하지 않고 GPU를 활용할 수 있도록 많은 개선이 이루어지고 있는 관계로 이 글에서 설명한 부분들은 시간이 지나면서 맞지않는 사실이 될 가능성도 높습니다(사실 이미 맞지 않지만 쉬운 이해를 위해 일부러 단정적으로 설명한 부분도 있습니다). 하지만 GPU의 성능이 충분히 활용되고 있지 못한 상황에 부딪쳤을 때, 그 이유를 이해하는데 이 글이 도움이 될 것으로 생각합니다.