언어 모델의 Fine-Tuning 성능 올리기
안녕하세요, 데이블 AI 팀의 machine learning engineer 김명섭입니다.
이번 포스팅에서는 language model (LM)의 fine tuning의 성능을 더욱 향상시키는 다양한 방법론에 대해 알아보고자 합니다. LM의 fine-tuning 성능을 더욱 향상시키는 다양한 방법을 소개해 드리는 데에 중점을 맞춘 포스팅으로 각 방법론의 매우 상세한 내용보다는 어떠한 방법론이 존재하는지에 초점을 맞추어 작성되었습니다. 추가적으로, 특정 task에 대한 fine-tuning의 매우 상세한 내용을 다루지는 않습니다. 이 글은 자연어 처리에 관심이 있는 엔지니어, 연구자를 예상 독자로 작성되었으나, Introduction의 경우에는 관련 지식이 없더라도 이해하실 수 있을 것이라 생각합니다.
1. Introduction
2024년 7월 현재, 생성형 AI와 거대 언어 모델 (large language model; LLM)의 시대라고 불러도 될 만큼 LLM의 발전이 활발하게 이루어지고 있습니다. Google, Meta, OpenAI 등의 기업에서는 1년 내에도 다수의 LLM을 발표하고 있는 상황입니다.
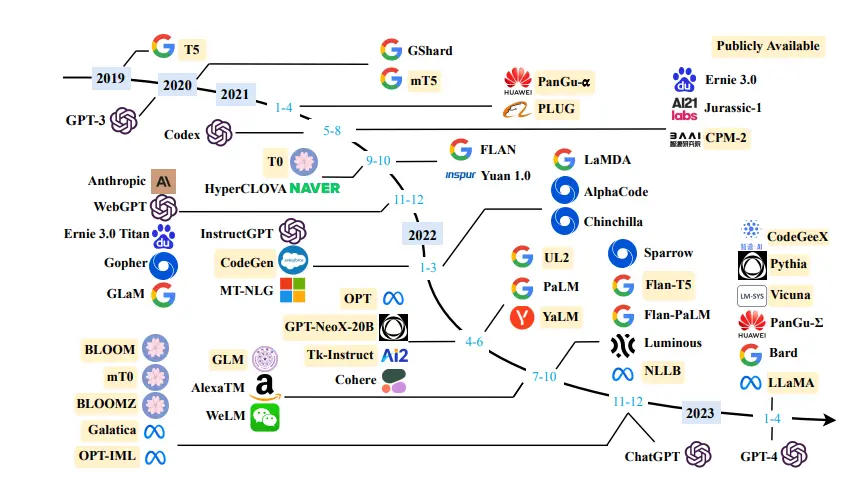 |
|---|
| Reference: https://www.labellerr.com/blog/overview-of-development-of-large-larnguage-models/ |
LLM은 대규모의 텍스트 말뭉치(corpora)를 이용하여 주어진 문장 뒤에 등장할 단어가 무엇인지 예측하는 방식으로 학습됩니다. 이 과정에서, LLM은 특정 질문 또는 대화 뒤에 일반적으로 등장할 것으로 예상되는 단어, 문맥을 학습할 수 있게 됩니다. 추가적으로 대규모의 텍스트 말뭉치 속에 숨어있는 번역, 연산 등의 sub-task를 해결할 수 있게 됩니다. 아래 예시에서는 주어진 문장 뒤에 나올 단어를 예측하는 방식으로 번역 task를 해결하는 과정을 확인하실 수 있습니다.
 |
|---|
| Reference: https://www.youtube.com/watch?v=q5FGZBqK-vc |
이러한 방식으로 LLM은 단일 task가 아닌, 범용 task를 해결할 수 있는 능력을 갖게 되고, 단일의 LLM을 이용하여 다수의 문제들을 해결할 수 있게 됩니다. 이러한 학습 방식을 in-context learning이라고 합니다. 이러한 in-context learning을 수행하기 위해서는 필수적으로 초 대규모의 텍스트 말뭉치를 필요로 합니다. 2023년 7월에 Meta에서 발표한 Llama 2의 경우에, 학습된 텍스트 코퍼스의 정확한 크기나 세부 사항은 공개되지 않았으나, 일반적으로 GPT-4와 유사한 방식으로 웹 페이지, 책, 논문, 코드 등 다양한 텍스트 데이터를 포함하고 있을 것으로 추정됩니다. 추가적으로 LLM을 효과적으로 학습하기 위해서는 수백 기가바이트(Gigabytes)에서 수 테라바이트(Terabytes) 이상의 데이터가 사용되며, 이는 수 조 단어에 달할 수 있습니다. 일반적으로 책 한 페이지에 250단어가 들어간다고 생각했을 때, 해당 크기의 데이터는 200페이지 책 수천만권에서 수억권에 달하는 엄청난 규모의 데이터입니다.
그렇다면, 반드시 이런 우수한 LLM을 사용하는 것만이 좋은 결과를 가져올까요? 항상 그렇지만은 않습니다. 아래의 그림은 GPT-3의 논문(Language models are few shot learners)에서 발췌한 그림으로, 원 저자들은 LLM의 범용 task 처리 능력이 우수함을 보고하기 위해 수록한 그림이지만, 그 반대의 결과 역시 추론해 낼 수 있습니다. Fine-tuned SOTA에 해당하는 성능이, 상대적으로 작은 LM을 이용하여 특정 task (여기서는 TriviaQA)에 적합하게 모델을 학습했을 때의 결과라고 보실 수 있습니다. 보시는 바와 같이, 매우 큰 규모의 LLM (여기서는 175B, 모델 사이즈 약 700GB 이상)을 동원하여야 Fine-tuned SOTA를 이길 수 있음을 확인하실 수 있습니다.
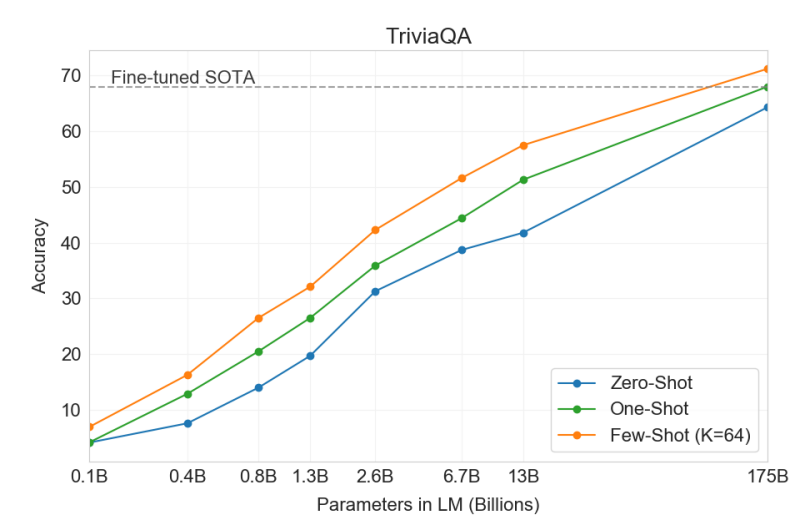 |
|---|
| Reference: https://arxiv.org/pdf/2005.14165 |
비즈니스적으로도 LLM을 사용하는 것이 항상 정답은 아닙니다. 위에서 언급드린 바와 같이, LLM을 학습하기 위해서는 매우 큰 규모의 데이터셋이 필요합니다. 추가적으로 막대한 규모의 computing power 역시 요구됩니다. GPT-3의 경우에는 한 번 학습에 한화로 50억 가량의 비용이 들었다고 보고되었으며, 이는 비즈니스적으로 다수의 기업들에게는 매우 큰 부담이 되는 금액일 것으로 생각됩니다.
 |
|---|
| GPT-3을 한 번 학습시키는 돈으로 할 수 있는 것: 회사 10분 거리의 아파트 구매 + 잔돈 17억 갖기 |
이렇듯, 많은 비용이 드는 LLM을 직접 학습시키기 보다는, task에 적합한 상대적으로 작은 LM을 만들어 해당 task에만 우수한 성능을 달성할 수 있도록 하는 것이 유리한 상황들도 존재합니다. 따라서, 오늘 포스팅에서는 상대적으로 작은 LM을 이용하여 좋은 성능을 낼 수 있도록 하는 기법들에 대해 알아보고자 합니다.
2. Boosting the Performance of Fine-tuning
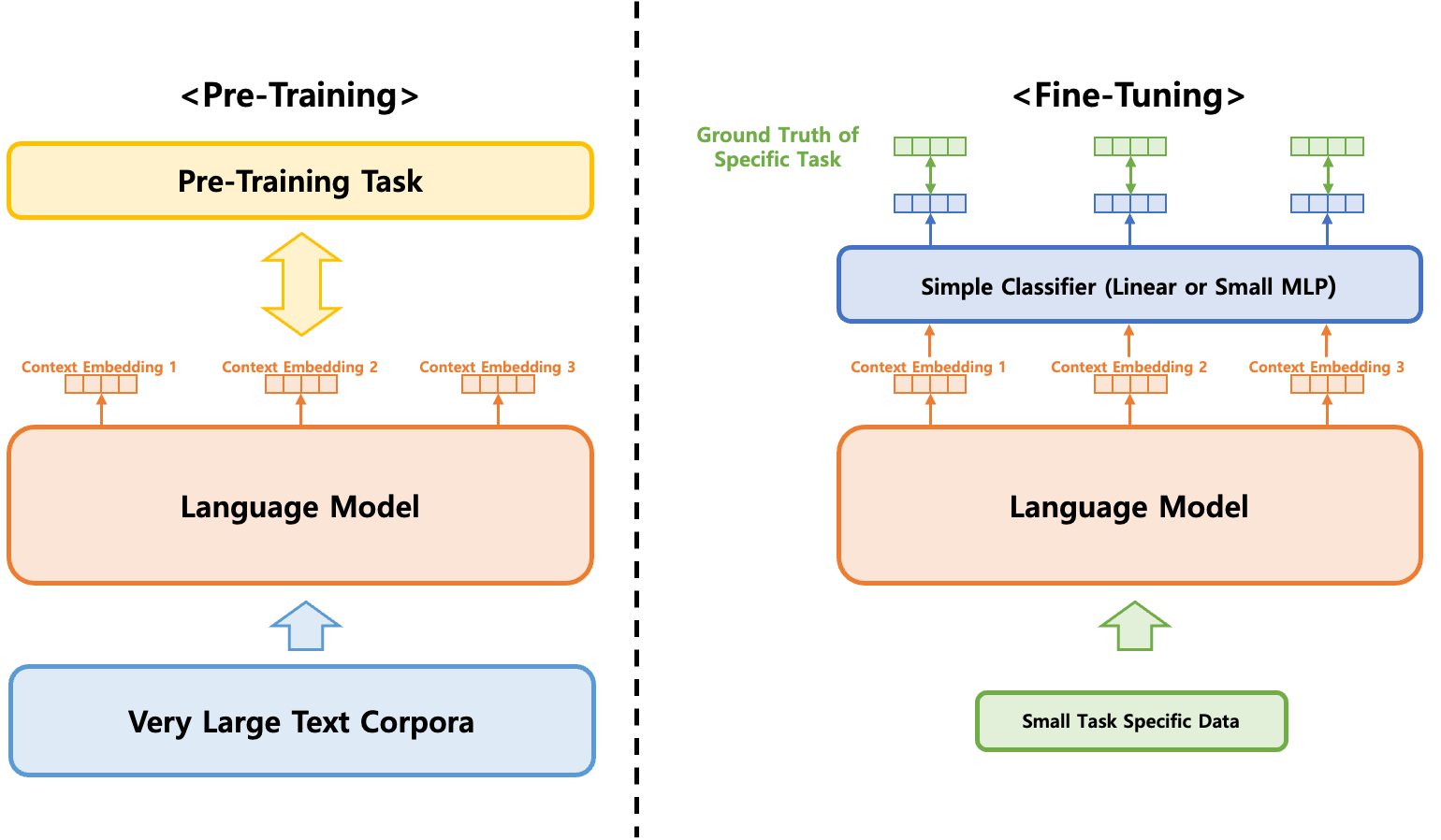
미세 조정(Fine-tuning)은 상대적으로 작은 LM을 특정 task (감정 분석, 질의 응답, 번역 등) 또는 domain (의료, 법률, 기술, 광고 등)에 맞게 추가적으로 학습시키는 과정입니다. LM은 일반적으로 사전 학습(pre-training)이라고 불리는 학습 방식을 통해 단어의 의미, 문법 규칙, 문장 구조 등을 학습하게 되지만, 특정 작업이나 도메인에 특화된 정보는 학습하지 못합니다. Fine-tuning을 통해 pre-training 과정에서 학습한 일반적 정보를 바탕으로 더 작은 규모의 특화된 데이터셋에 대한 추가적 학습을 통해 특화된 task 또는 domain에서 더 높은 성능을 발휘할 수 있도록 합니다.
LLM은 대규모의 텍스트 말뭉치(corpora)를 이용하여 주어진 문장 뒤에 등장할 단어가 무엇인지 예측하는 방식으로 학습됩니다. 이 과정에서, LLM은 특정 질문 또는 대화 뒤에 일반적으로 등장할 것으로 예상되는 단어, 문맥을 학습할 수 있게 됩니다. 추가적으로 대규모의 텍스트 말뭉치 속에 숨어있는 번역, 연산 등의 sub-task를 해결할 수 있게 됩니다. 아래 예시에서는 주어진 문장 뒤에 나올 단어를 예측하는 방식으로 번역 task를 해결하는 과정을 확인하실 수 있습니다.
 |
|---|
| Reference: https://www.youtube.com/watch?v=q5FGZBqK-vc |
2. 1. LoRA
LoRA (Low-Rank Adaptation)는 LM을 효율적으로 fine-tuning하기 위한 기법입니다. LM은 수십억 개의 매개변수를 가지고 있어, 특정 task에 맞추어 조정하려면 많은 계산 자원과 시간이 필요합니다. LoRA는 이러한 문제를 해결하기 위해 매개변수 업데이트를 저차원 근사로 제한하여 계산 비용과 메모리 사용을 크게 줄입니다.
기존의 fine-tuning 방식에서는 모델의 모든 매개변수를 직접 업데이트합니다. 이는 매우 많은 자원과 시간이 필요하며, 특히 대규모 모델의 경우에는 실용적이지 않습니다. LoRA는 모델의 가중치 행렬(weight matrices)을 두 개의 저차원 행렬로 분해하여 학습합니다. 예를 들어, 원래의 가중치 행렬이 $W$라면, LoRA는 이를 두 개의 저차원 행렬 $A$와 $B$로 근사하여 $W \approx A \cdot B$ 형태로 표현합니다. 이렇게 하면 학습 중에 조정해야 할 매개변수의 수가 크게 줄어듭니다.
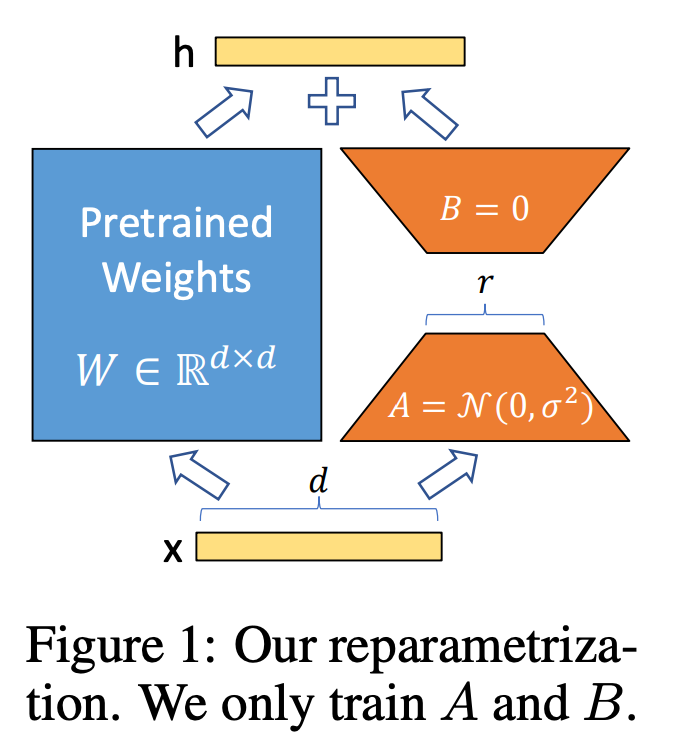 |
|---|
| Reference: https://arxiv.org/pdf/2106.09685 |
이 접근 방식의 주요 장점은 계산 효율성입니다. 저차원 근사를 사용하면 fine-tuing 과정에서 업데이트할 매개변수의 수가 줄어들기 때문에, 계산 비용이 감소하고 fine-tuning 속도가 빨라집니다. 또한, 저차원 행렬을 사용하므로 메모리 사용량이 크게 줄어들어, 더 적은 자원으로도 대규모 모델을 효과적으로 fine-tuning할 수 있습니다. 이는 연구자와 개발자가 대규모 모델을 사용할 때 비용과 시간 측면에서 큰 이점을 제공합니다.
LoRA는 성능 유지 측면에서도 유리합니다. 저차원 근사를 통해 성능 손실 없이 모델을 효율적으로 조정할 수 있습니다. 이는 실험을 통해 입증된 바 있으며, 다양한 응용 분야에서 높은 성능을 유지하면서도 효율적인 fine-tuning을 가능하게 합니다. 예를 들어, 자연어 처리(NLP) 작업에서 LoRA를 적용하면, 대규모 모델의 성능을 그대로 유지하면서도 특정 도메인에 맞춘 맞춤형 모델을 빠르고 효율적으로 생성할 수 있습니다.
아래의 표는 LoRA의 원본 논문(LoRA: Low-Rank Adaptation or large language models)에서 발췌한 것으로, GPT-2 Medium과 GPT-2 Large 에 대해 단순 fine-tuning과 LoRA를 적용했을 때의 trainable paramter의 수를 비교한 것입니다. GPT-2 Medium 기준 354.92M의 paramter가 0.35M parameter로, GPT-2 Large를 기준으로 774.03M에서 0.77M으로, 각각 약 1/1000으로 감소한 것을 확인하실 수 있으며, 이 때 오히려 성능은 증가하신 것을 확인하실 수 있습니다.
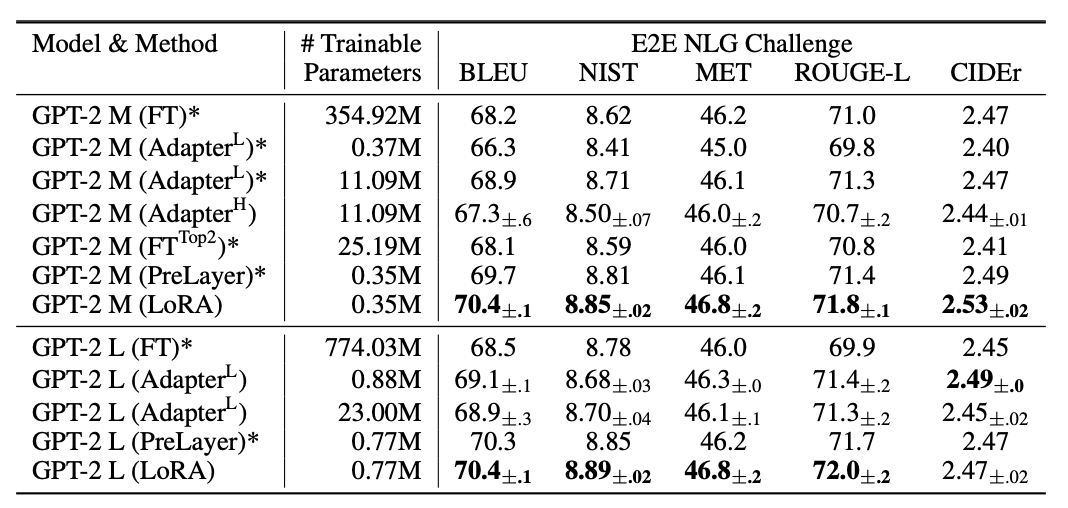 |
|---|
| Reference: https://arxiv.org/pdf/2106.09685 |
LoRA를 적용하려면, 먼저 사전 학습된 LM을 준비하고, 해당 모델의 가중치 행렬을 두 개의 저차원 행렬로 분해합니다. 그런 다음, 저차원 행렬을 사용하여 파인 튜닝을 수행합니다. 이 과정에서 원래의 가중치 행렬은 고정되고, 저차원 행렬만 업데이트됩니다. 마지막으로, 파인 튜닝된 모델을 평가하고, 필요한 경우 추가 조정을 수행합니다. 이러한 과정을 통해 LoRA는 대형 언어 모델의 파인 튜닝을 더 효율적이고 실용적으로 만들어줍니다. 다만 이건 제가 개인적으로 처음에 헷갈렸던 부분인데, 전체 모델에 대해 두 개의 저차원 행렬 분해를 적용하는 것이 아니라, 모델에 존재하는 각 Linear Layer마다 적용하는 것임을 인지해 주세요.
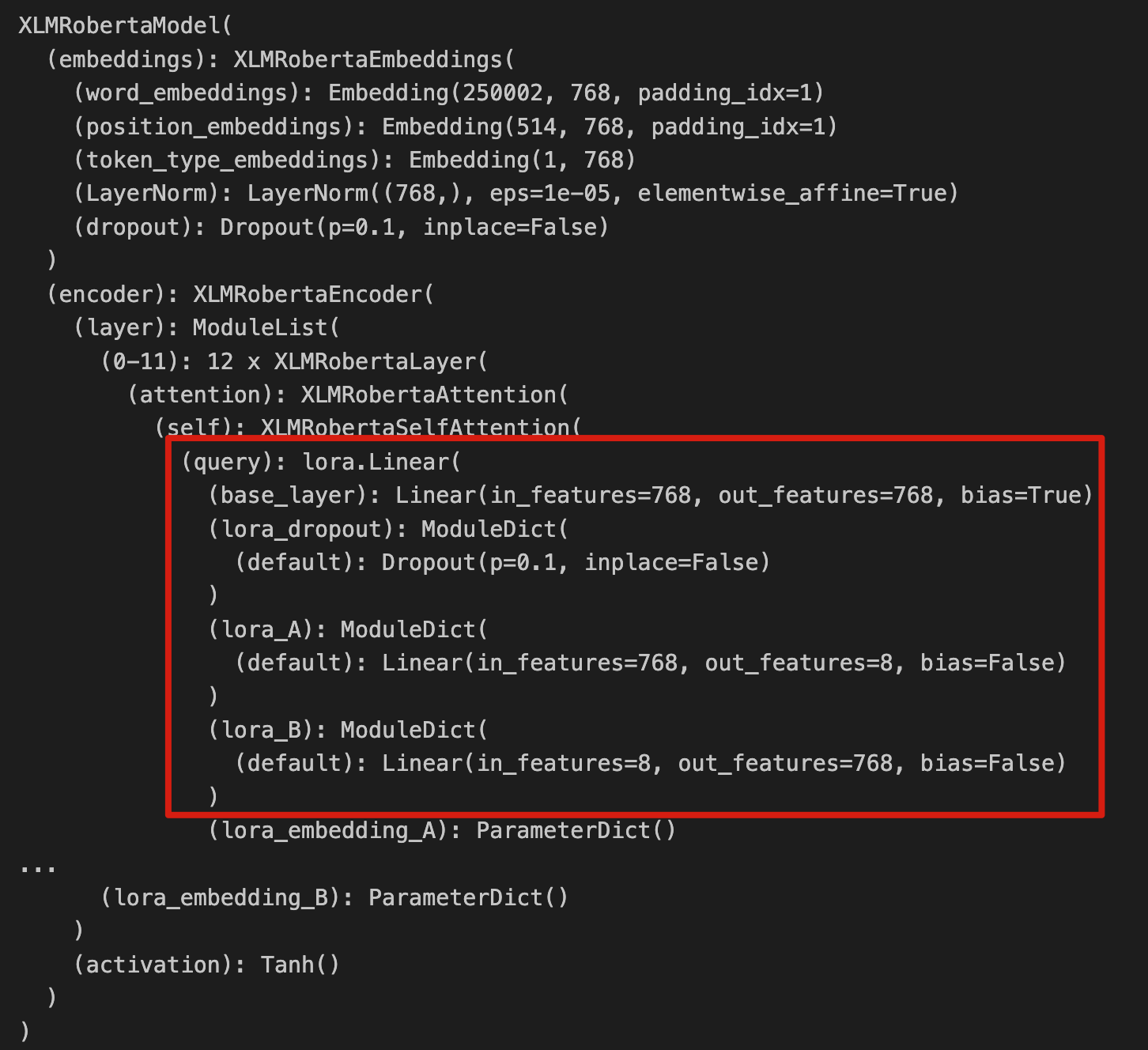 |
2. 2. TAPT, DAPT
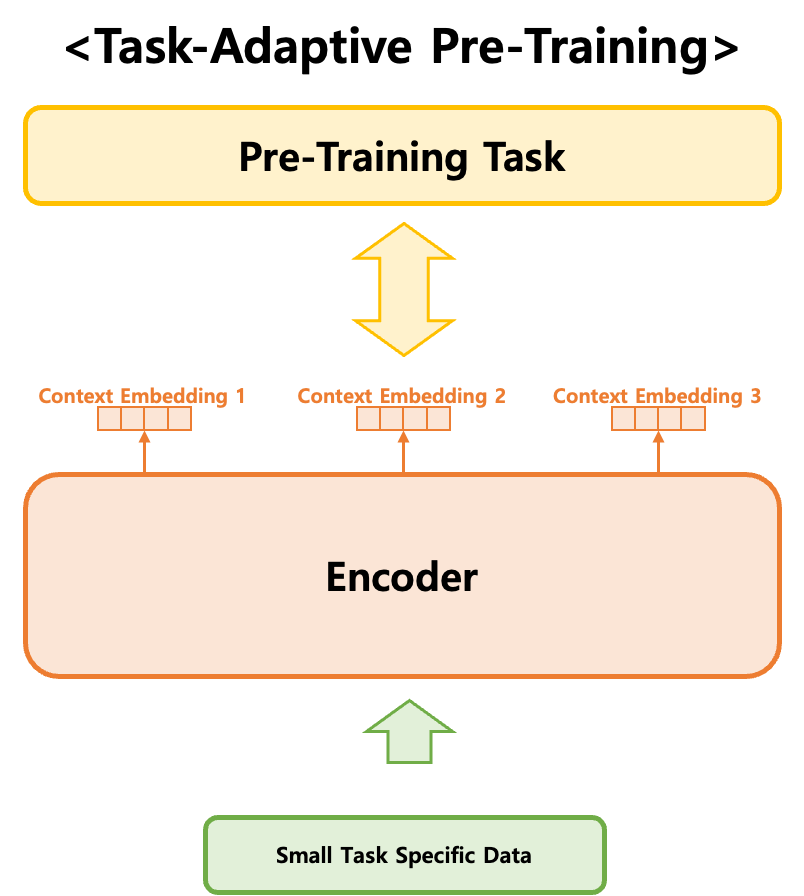
task-adaptive pre-training (TAPT)와 domain-adaptive pre-training (DAPT)는 언어 모델의 사전 학습에서 사용하는 text corpora와 미세 조정에서 사용하는 text dataset이 서로 다른 특징을 지닌다는 점에 초점을 맞춥니다. 실제로 LM의 사전 학습에는 wikipedia, 논문, 코드, 블로그 글 등 다양한 글이 사용되고, 일반적으로 길이가 긴 편에 속하지만, 대화와 같은 특정 task에서는 길이가 짧은 텍스트가 주로 등장할 수 있습니다. 이들의 패턴이 서로 다른 것은 LM의 fine-tuning에 긍정적인 영향을 주지 못할 수 있습니다.
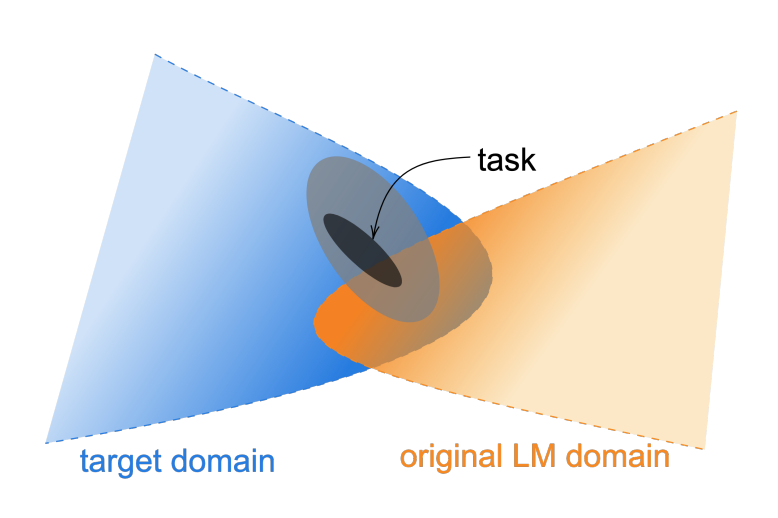 |
|---|
| Reference: https://arxiv.org/pdf/2004.10964 |
TAPT는 사전 학습된 언어 모델을 더욱 미세 조정하는 과정입니다. 기본적으로, 일반 언어 모델은 대규모의 일반적인 텍스트 데이터를 사용하여 사전 학습됩니다. 이러한 모델은 다양한 언어 패턴과 정보를 학습하지만, 특정 작업의 특수한 요구사항을 모두 반영하지는 못합니다. TAPT는 해당 작업의 특성에 맞는 데이터를 사용하여 모델을 추가로 사전 학습시킴으로써 이 문제를 해결합니다. 예를 들어, 감정 분석 작업을 수행하려는 경우, 감정이 잘 드러나는 텍스트 데이터를 사용하여 모델을 추가로 사전 학습시키는 것이 TAPT입니다.
DAPT는 특정 도메인에 특화된 언어 모델을 만들기 위한 과정입니다. 각 도메인은 고유한 용어와 스타일이 있기 때문에, 일반적인 언어 모델만으로는 충분하지 않을 때가 많습니다. DAPT는 특정 도메인의 텍스트 데이터를 사용하여 모델을 사전 학습시켜 해당 도메인의 특성을 잘 반영할 수 있도록 합니다. 예를 들어, 의학 분야의 텍스트를 처리하려는 경우, 의학 관련 논문이나 보고서 데이터를 사용하여 모델을 사전 학습시키는 것이 DAPT입니다. 이렇게 하면 모델이 해당 도메인의 용어와 표현을 더 잘 이해하고 처리할 수 있게 됩니다.
 |
|---|
| Reference: https://www.youtube.com/watch?v=QD7evnWWj2A |
TAPT와 DAPT는 언어 모델의 성능을 향상시키는 강력한 도구입니다. TAPT는 특정 작업에 맞게 모델을 미세 조정하여 최적의 성능을 발휘할 수 있도록 하고, DAPT는 특정 도메인의 특성을 반영하여 모델의 이해도를 높입니다. 이 두 기술을 적절히 활용하면, 더욱 정교하고 효과적인 언어 모델을 개발할 수 있습니다.
2. 3. Adversarial Training
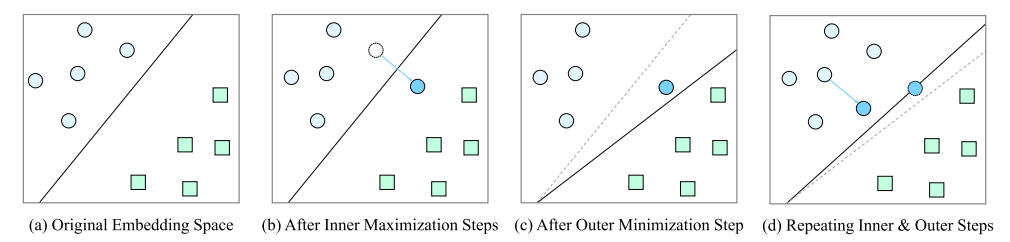
언어 모델의 성능을 향상시키기 위한 다양한 기법들이 연구되고 있습니다. 그 중 하나로 최근 주목받고 있는 기법이 적대적 훈련(Adversarial Training)입니다. Adversarial training은 모델이 악의적인 입력 또는 예기치 않은 변형에 더 강건해지도록 훈련하는 방법입니다. 기본 개념은 모델이 잘못된 예측을 하도록 유도하는 “적대적 예제(adversarial example)”를 생성하고, 이러한 예제에 대해 모델을 반복적으로 학습시키는 것입니다. 이렇게 하면 모델이 다양한 변형된 입력에도 견고하게 반응할 수 있게 되어 성능이 향상됩니다.
Adversarial training의 상세 학습 과정은 본 포스팅의 범위를 넘어가는 것으로 생각되어, 혹시 상세한 방법이 궁금하시다면 아래 동영상의 8분 30초까지를 참고해 주세요. 본 포스팅에서는 adversarial training은 학습 과정에서 input data에 미세한 노이즈를 부과한다고만 이해해 주셔도 무관할 것 같습니다.
 |
|---|
| Reference: https://www.youtube.com/watch?v=KSUyLaDpFP4 |
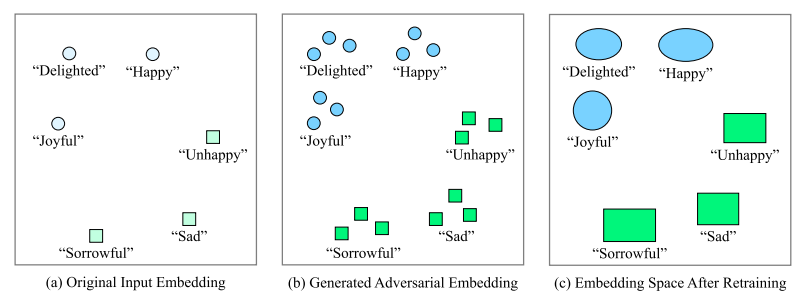
학습 과정에서 미세한 노이즈를 부과하는 것이 왜 학습에 도움이 될까요? LM은 주변 단어들의 embedding을 함께 학습하여 미세한 문맥을 파악할 수 있도록 학습됩니다. 이 과정에서 사전에 데이터에 존재하지 않았던 미세한 embedding의 변화를 학습할 수 있게 되어, 각 단어가 갖는 공간을 확장하는 효과가 있습니다.
 |
|---|
| Reference: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9680703 |
 |
|---|
| Reference: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9680703 |
각 단어 (또는 토큰)이 갖는 공간을 확장함으로써 미지의 데이터에 대해 보다 일반화된 LM을 만들 수 있게 됩니다. 아래 그림에서 미세하게 노이즈가 부과된 토큰에 대해 모두 같은 토큰으로 인지할 수 있게 학습하는 과정에서 일반화 성능을 보유하게 된다고 이해해 주시면 감사하겠습니다. 상세한 내용은 본 포스팅에 더하여 다음 논문을 참고해 주세요. Text Embedding Augmentation Based on Retraining With Pseudo-Labeled Adversarial Embedding (Kim and Kang, 2022)
 |
|---|
| Reference: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9680703 |
3. Conclusion
이번 포스팅에서는 LM의 fine-tuning의 성능을 더욱 끌어올릴 수 있는 다양한 기법들에 대해 알아보았습니다. 본 포스팅에서는 각 방법론들의 매우 세부적인 사항까지는 다루지 않고, 어떠한 방법론들이 있는지만을 소개해 드렸지만, 향후 기회가 된다면 각 방법론들에 대해서 상세하게 다루어 보고자 합니다. 본 포스팅이 언어 모델의 fine-tuning 성능을 향상시키고자 하는 엔지니어 또는 연구자분들께 도움이 되기를 바랍니다.
긴 글 읽어 주셔서 감사합니다.