머신러닝으로 만드는 개인화 추천 시스템
안녕하세요, 데이블 AI팀의 machine learning engineer 김명섭입니다.
이번 포스팅에서는 기초적인 개인화 추천 시스템 설계에 대해 알아보고자 합니다. 본 포스팅에서는 프로그래머틱 애드 (programatic ad), real-time bidding 및 DSP 등에 관한 내용들은 다루지 않습니다. 만약 해당 내용들이 궁금하시다면, 아래의 포스팅을 참고해 주세요!
- 데이나의 참 쉬운 애드테크 (Link)
추가적으로 본 포스팅은 전반적인 개인화 추천 시스템 설계에 관한 내용을 다루고 있습니다. 특정 머신러닝 모델의 architecture 등에 대해서는 다루지 않습니다.
1. Personalized Recommendation and Machine Learning
광고 추천 시스템 설계에 머신러닝 (machine learning)을 활용하는 가장 큰 이유는 개인화 추천으로 생각할 수 있을 것 같습니다. 개인화 추천이란, 사용자의 개별적인 관심, 선호도, 특성 등을 고려하여 상품, 서비스, 콘텐츠 등을 추천하는 것을 의미합니다. 개인화 추천은 사용자의 과거 행동 기록, 지역 정보, 광고의 특성, 광고를 보게 될 광고 지면의 특성 등을 종합적으로 고려하여 사용자가 관심을 보일 만한 적절한 광고를 송출합니다. 간단한 예시를 들어 보면 아래와 같습니다.
사용자가 관심을 보인 상품과 유사한 상품을 추천
e.g.) 최근 웹 검색을 통해 iPhone 15를 검색한 유저에게 iPad, AirPod 등의 광고를 송출
사용자들의 과거 행동 (구매 내역, 평가 등)을 기반으로 비슷한 취향을 가진 사용자들을 찾아, 해당 사용자들이 관심을 보인 상품을 추천
e.g.) 캠핑에 대해 관심을 보인 사용자들은 일반적으로 삼겹살에 관심을 보이는 경우가 많음, 캠핑에 관심을 보인 사용자에게 삼겹살 관련 상품을 추천
그렇다면, 이러한 개인화 추천에서 머신러닝이 왜 유용할까요? 개인화 추천에 있어 머신러닝이 유용한 이유는 아래와 같이 정리해 볼 수 있을 것 같습니다.
-
패턴 발견: 머신러닝은 대규모 데이터 세트에서 패턴을 발견하고 학습할 수 있습니다. 이를 통해 사용자의 행동 패턴이나 취향을 파악하여 개인화된 추천을 제공할 수 있습니다.
-
유연성: 머신러닝 모델은 다양한 유형의 데이터를 처리할 수 있습니다. 사용자의 행동 이력, 송출을 원하는 광고의 특성, 광고를 보게 될 지면의 특성 등 다양한 데이터를 모델에 통합하여 개인화된 추천을 제공할 수 있습니다.
-
시간적 변화 대응: 사용자의 취향이나 행동은 시간에 따라 변할 수 있습니다. 머신러닝 모델은 실시간으로 데이터를 갱신하고 학습하여 새로운 패턴이나 트렌드를 파악하여 추천을 업데이트할 수 있습니다.
-
스케일러빌리티: 머신러닝 알고리즘은 대규모 데이터 세트에서도 효율적으로 작동할 수 있습니다. 이를 통해 수백만 이상의 사용자와 항목에 대해 개인화된 추천을 실시간으로 제공할 수 있습니다.
이제부터, 이러한 개인화 추천에 머신러닝을 적용하는 기초적인 방법에 대해 알아보도록 하겠습니다.
2. Overall Architecture
개인화된 추천 모델을 설계하는 과정은 아래와 같이, 실험 환경 (experiment environment)과 배포 환경 (production environment)로 구분됩니다.
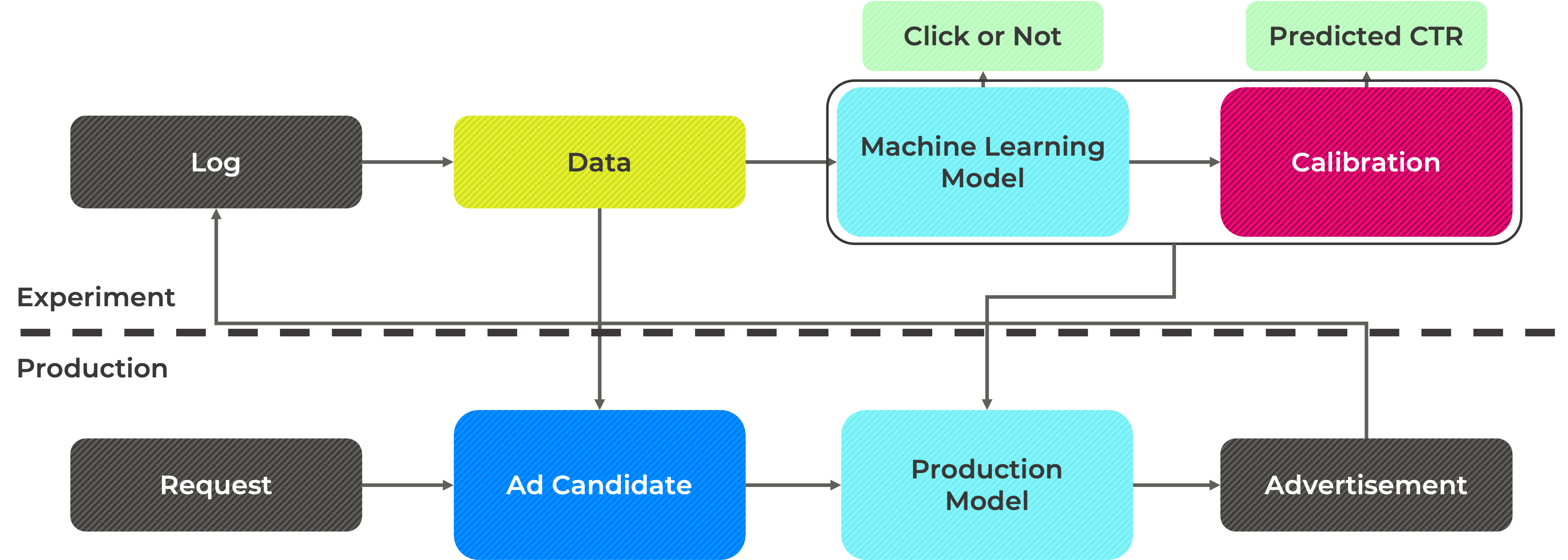
이제부터 각 환경을 통해 원천 로그로부터, 최종 유저가 보는 광고에 이르기까지 어떤 방식으로 시스템이 설계되는지를 알아보겠습니다.
2. 1. Expeirment Environment
우선적으로 실험 환경을 살펴보고자 합니다.
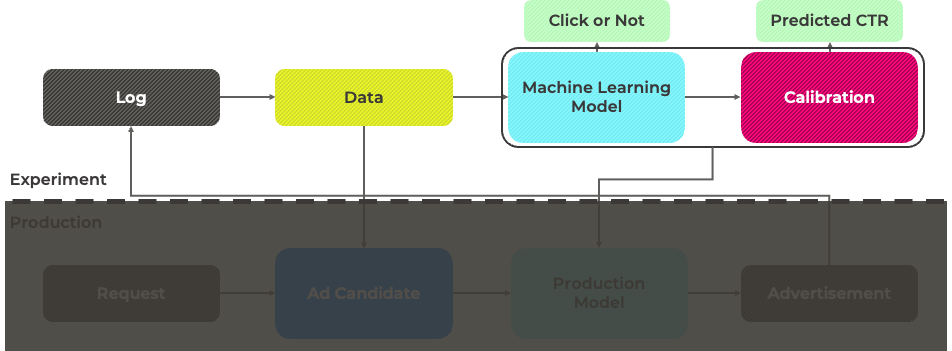
2. 1. 1. Dataset
실험 환경에서는 원천 로그로부터 정제된 데이터를 이용하여 머신러닝 모델을 학습합니다.

원천 로그를 조금 자세히 살펴보겠습니다. 아래의 예시 로그는 모바일 환경에서 특정 ad exchange가 보내 주는 로그로, 특정 지면에 대해 광고 bidding에 참여할지 여부를 결정하기 위한 목적으로 사용됩니다. 예시는 로그의 일부이며, app 정보를 나타내는 부분만 가져왔습니다.
{
id=1228579,
name=Block Jam 3D,
bundle=1618805694,
domain=null,
storeurl=https://apps.apple.com/us/app/block-jam-3d/id1618805694?uo=4&at=10l9yE,
cat=[IAB1, IAB9],
ver=2.12.1,
privacypolicy=1,
paid=0,
publisher={
id=209084,
name=Voodoo,
domain=https://www.voodoo.io/
},
ext={
storecat=Games,
storesubcat=[Board, Puzzle],
fmwname=unity3d,
apilevel=null
}
}
사람이 한 눈에 알아보기에는 정보가 정제되지 않은 것 같습니다. 이러한 형태의 로그로는 머신러닝 모델을 학습시킬 수 없습니다. 이 정보들 중 머신러닝 모델이 사용할 수 있는 대표적인 정보들을 모아봅시다. 우선적으로 어떤 app을 대상으로 bidding 할지를 결정하기 위해 id 정보는 필요할 것 같습니다. 도메인 지식이 조금 있다면, id와 비슷한 기능을 하는 app_bundle을 사용할 수 있다는 정보 역시 알 수 있습니다. 추가적으로 카테고리 정보들이 보이는 것 같습니다. 앱을 설계한 개발자의 정보도 쓸모가 있을지는 모르지만 일단 가공해 봅시다.
정리해 보면 아래와 같은 정보들을 머신러닝 모델의 학습에 사용할 수 있을 것 같습니다.
{
id=1228579,
bundle=1618805694,
cat=[IAB1, IAB9],
publisher={
id=209084,
},
ext={
storecat=Games,
storesubcat=[Board, Puzzle],
}
}
이제 이 정보들을 보기 좋게 table의 형태로 가공해 보겠습니다.
| app_id | app_bundle | app_category | publisher_id | store_category | store_sub_category | |
|---|---|---|---|---|---|---|
| 1228579 | 1618805694 | [IAB1, IAB9] | 209084 | Games | [Board, Puzzle] | |
| … | … | … | … | … | … | … |
이제 조금 알아보기 편해진 것 같습니다. 이제 머신 러닝 모델을 학습하여 특정 광고를 app_id가 1228579, app_bundle이 1618805694, store_category가 Games 등의 정보를 가진 app에 노출 시킬지 말지를 결정하면 될 것 같습니다. 사실 위의 정보도 머신러닝 모델을 학습 시키기에는 충분히 정제 되지는 않았지만, 매우 상세한 정제 과정은 본 포스팅의 범위를 넘어가기 때문에 차후 다른 포스팅에서 다루어 보는 것이 좋을 것 같습니다. 추가적으로 app에 대해 정보를 얻었다면, 다른 정보들과 결합하여 새로운 정보를 만들어 낼 수도 있습니다. 해당 app에서 특정 광고에 대해 노출 (impression)이 몇 번 일어났는지, 클릭 (click)은 몇 번 일어났는지 등의 정보를 추가해 줄 수도 있을 것 같습니다. 이와 같이 원천 로그로부터 정제한 정보를 데이터 (data)라고 합니다.
지금까지 원천 로그에 존재하는 정보를 가공하여 머신러닝 모델에 입력할 데이터로 가공하는 방법을 알아보았습니다. 그렇다면 머신러닝 모델은 무엇을 대상으로 학습이 되어야 할까요? 결국 최종 유저가 관심을 보일 광고를 잘 맞힐 수 있도록 학습이 되면 될 것 같습니다. 관심의 척도는 문제를 정의하기에 따라 달라질 수 있지만, 일반적으로 특정 유저가 광고를 클릭할 지 여부를 모델이 잘 판별할 수 있도록 학습을 시키면 될 것 같습니다. 이를 위해 아래와 같이 정보를 추가하여 데이터를 변경해 보겠습니다.
| app_bundle | app_category | publisher_id | store_category | store_sub_category | ad_id | click | |
|---|---|---|---|---|---|---|---|
| 1618805694 | [IAB1, IAB9] | 209084 | Games | [Board, Puzzle] | 1 | 1 | |
| … | … | … | … | … | … | … | … |
설명에 필요 없는 column을 제거하고, 광고 정보 및 클릭 여부를 추가하였습니다. 이 데이터는 과거 특정 유저의 행동 기록에 해당합니다. 특정 유저는 ad_id = 1인 광고를 app_bundle = 1618805694인 app에서 보았고, 광고를 클릭했음을 의미합니다. 이러한 정보를 가지고, 특정 유저와 비슷한 유저가 비슷한 앱에서 광고를 보았을 때, 클릭을 할 지, 클릭을 하지 않을지 여부를 예측할 수 있도록 머신러닝 모델을 설계하고자 합니다. 이와 같이 머신러닝 모델이 학습의 타겟으로 사용할 정보를 포함한 데이터를 데이터셋 (dataset)이라고 합니다.
2. 1. 2. Model Training
이제, 아래의 그림과 같이 로그로 부터 정제되어 다양한 정보를 포함한 데이터를 머신러닝 모델에 입력하여, 특정 유저가 클릭을 할지, 클릭을 하지 않을지 예측하는 모델을 설계합니다.
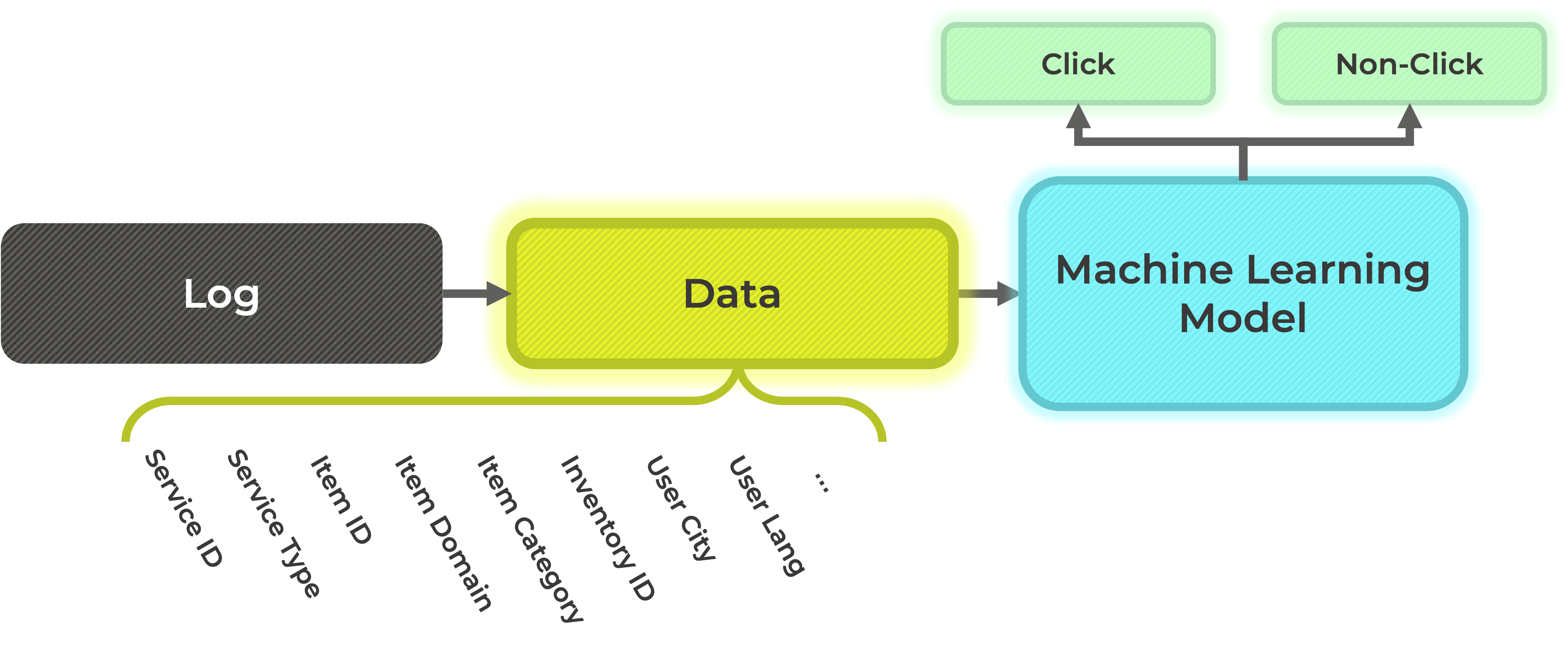
그러면, 머신러닝 모델은 아래의 그림과 같이, 특정 유저가 광고를 클릭할 확률, 클릭하지 않을 확률을 계산할 수 있게 됩니다. 이렇게 계산된 특정 유저가 광고를 클릭할 확률을 predicted click through rate (pCTR)이라고 합니다.
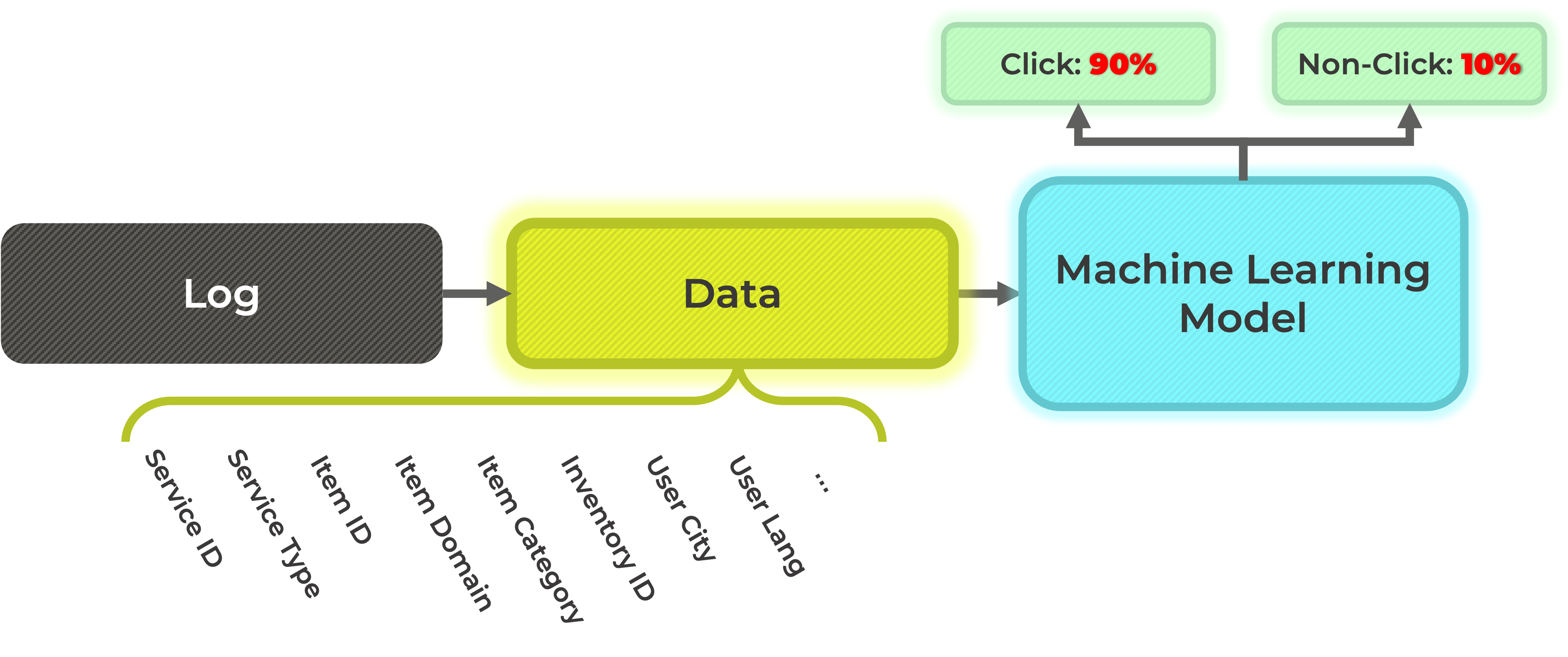
언뜻 보기에는 위와 같은 방식으로 광고를 송출할 모델을 학습시킬 수 있을 것 같습니다. 하지만 실제로는 그렇지 않습니다. 일반적으로 광고를 클릭할 확률은 1% 미만입니다. 통상적인 웹 사이트를 보았을 때 노출되는 광고 중 실제 클릭하는 비율이 얼마인지를 생각해 보면 광고를 클릭할 비율인 click through rate (CTR)이 얼마나 낮은지를 예상하실 수 있습니다. 이와 같이, 학습 데이터셋의 99% 이상이 non-click 데이터로 구성되어 있기 때문에, 이 데이터셋을 그대로 사용하게 될 경우 머신러닝 모델은 클릭이 일어나지 않을 것이라고 예측하기만 해도 99%의 정확도 성능을 기록하게 됩니다. 하지만 우리가 설계하기를 원하는 모델은 특정 유저가 특정 광고를 클릭할 확률을 정확하게 예측하는 모델이기에, 이렇게 학습된 모델은 우리의 목적과는 맞지 않습니다.
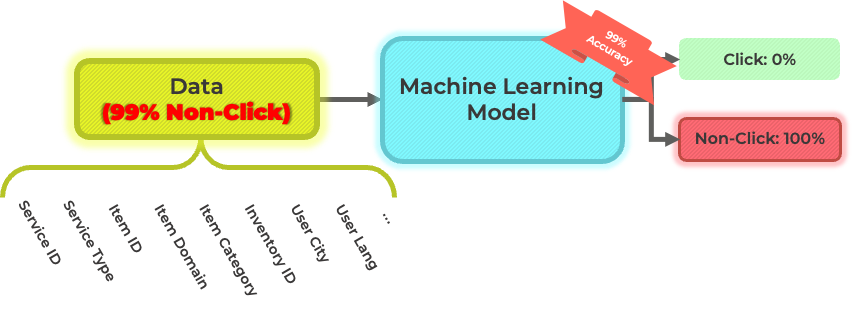
이러한 상황을 방지하고, 개인화 추천 시스템의 목적에 부합하는 머신러닝 모델을 만들기 위해 click과 non-click 데이터를 적절한 비율로 구성하고 학습을 진행합니다. 아래 예시와 같이, 일반적으로 click 데이터는 전체 데이터를 사용하고, non-click 데이터는 일부를 샘플링하여 적절한 비율을 맞춘 뒤 학습에 사용하게 됩니다.
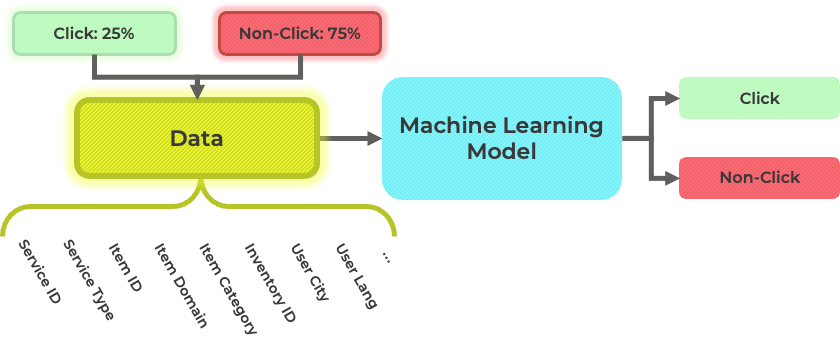
이 외에도 non-click이 명확하고, 머신러닝 모델이 이미 잘 학습하여 머신러닝 모델 입장에서는 쉬운 데이터를 덜 학습하도록 하는 등 모델 성능을 올리기 위한 다양한 기법들이나, 실제 서비스에 활용 가능할 정보로 빠른 속도로 학습이 가능하도록 하는 등의 다양한 기법들을 적용하여 머신러닝 모델을 학습시킵니다.
2. 1. 3. Calibration
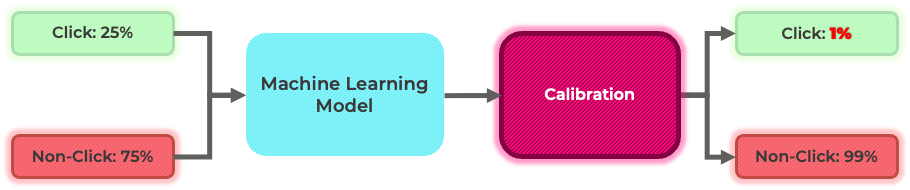
조금 전에 머신러닝 모델이 click 데이터의 패턴을 보다 잘 학습할 수 있도록 샘플링을 통해 click 데이터와 non-click 데이터의 비율을 조정한다고 말씀드렸습니다. 하지만, 이렇게 만들어진 데이터는 실제 데이터와는 서로 다른 패턴을 가지고 있습니다. 예시로, 아래 그림을 보면, click의 비율을 조정한 데이터에서는 click이 일어날 확률이 25%이지만, 실제 데이터에서는 click이 일어날 확률이 1%입니다.
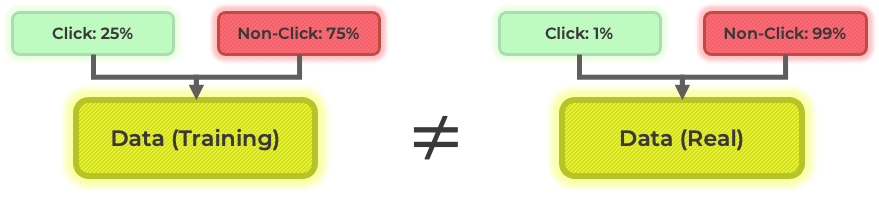
따라서, 비율 조정을 한 데이터로 학습한 머신러닝 모델은 실제 데이터로 학습한 머신러닝 모델과는 다르게 학습됩니다. 비율을 조정한 데이터를 사용하게 될 경우 실제 click이 일어날 확률보다 예측 값이 과도하게 높아질 가능성이 존재하고, 이는 추천 시스템의 성능을 해칠 수 있습니다. 이러한 차이를 해결하기 위해 보정 (calibration) 작업을 거치게 됩니다.
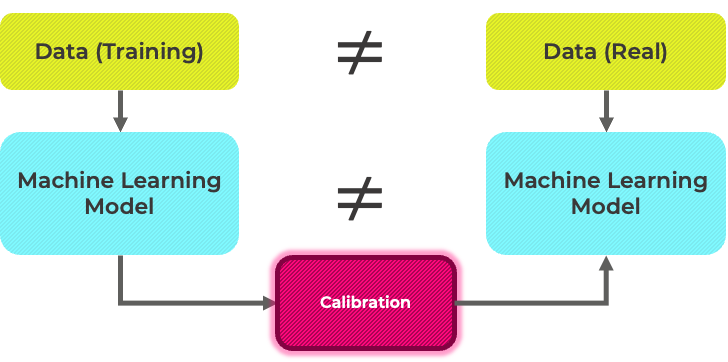
상세하게 calibration logic을 설명하는 것은 이 포스팅의 범위를 넘어가는 것으로 생각되어, 별도의 포스팅으로 다루도록 하겠습니다. 여기서는 샘플링을 통해 비율을 조정한 데이터로 학습한 모델의 예측 결과 값을 실제 데이터로 학습한 결과와 비슷하도록 모델 예측 결과 값을 보정해주는 작업이라고만 이해하셔도 무관할 것 같습니다. 이러한 과정을 거쳐 클릭이 일어날 것으로 예상되는 확률 값을 pCTR로 사용하여 광고 bidding을 진행하게 됩니다.
2. 1. 4. Experiment Environment Summary
지금까지 실험 환경에 대해 살펴보았습니다. 배포 환경으로 넘어가기에 앞서 실험 환경에서 수행된 작업들을 정리해 보면 아래와 같습니다.
- 원천 로그로 부터 정보를 정제하여 데이터셋을 생성
- 데이터셋에 대해 샘플링을 통해 클릭 데이터의 비율을 조정하고, 머신러닝 모델 학습
- 해당 모델의 결과가 실제 데이터를 사용한 예측 결과와 비슷하게 되도록 보정 작업
2. 2. Production Environment
지금부터는 배포 환경을 살펴보겠습니다.
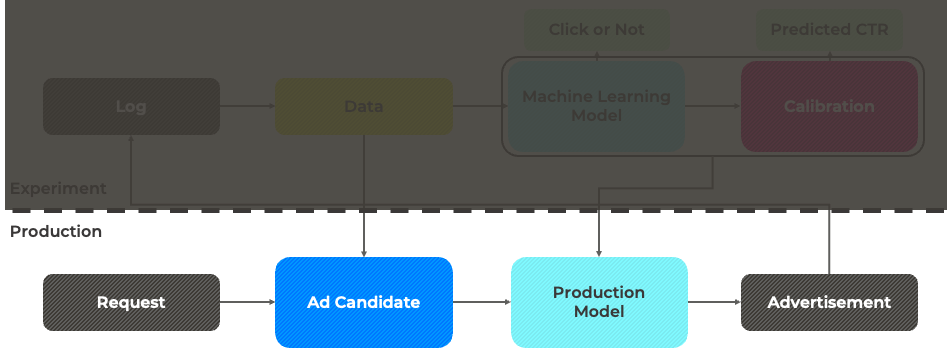
배포 환경에서는 특정 유저에 대한 광고 request에 대해 광고 후보군을 선정하고, 예상 클릭율 (pCTR)이 높은 광고를 선택하여 송출합니다.
2. 2. 1. Ad Candidate
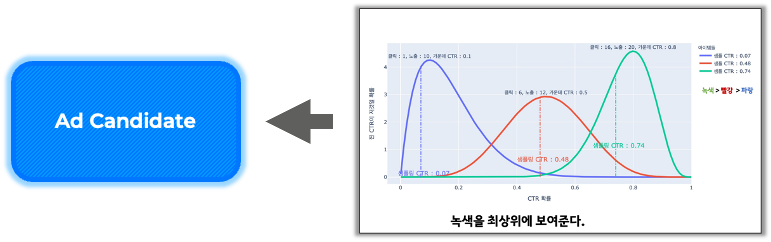
실험 환경에서 만들었던 머신러닝 모델은 광고의 클릭율을 예측하는데 많은 연산을 요구합니다. 그래서 적절한 광고를 송출하기 위해 request마다 송출 가능한 모든 광고에 대해 클릭율을 계산하면 많은 시간과 비용이 들게 됩니다. 따라서, 비용과 시간을 줄이기 위해 적절한 광고 후보군 (ad candidate)를 선정하는 작업을 먼저 거치게 됩니다.
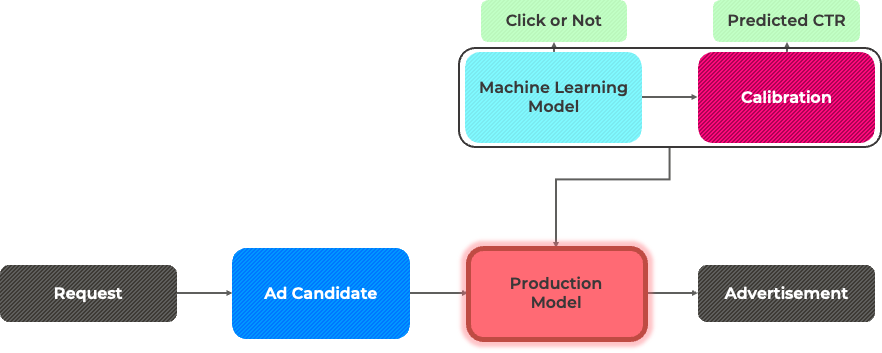
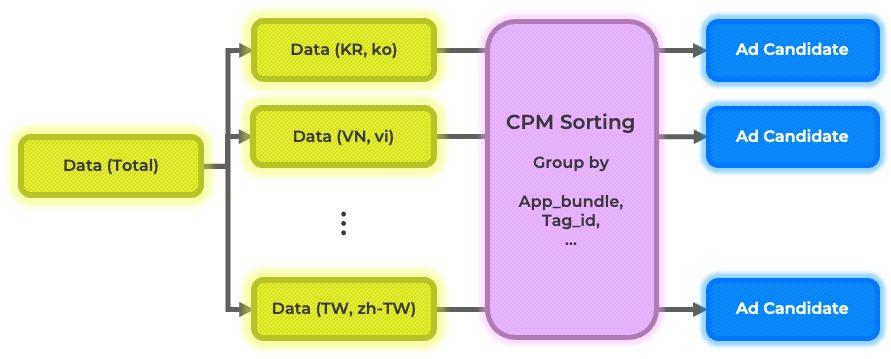
Ad candidate는 데이터의 광고 정보를 기반으로 생성됩니다. 아주 대표적으로 아래와 같은 예시를 들 수 있을 것 같습니다. 데이터를 유저의 지역, 언어 별로 분리합니다. 이후 각 지역 및 언어 별로 다양한 조건 하에서 과거의 cost per mille (CPM; 광고 1000회 노출 당 비용, 기대 이익으로 생각해도 됨)이 높은 순서대로 임의 개수의 광고를 선별할 수 있습니다.
또는, thompson sampling과 같이 광고의 노출 정도와 클릭 수에 따라 샘플링을 통해 ad candidate를 선정하기도 합니다. Thompson sampling에 대한 상세한 설명은 본 포스팅의 범위를 넘어가기 때문에, 노출이 적다면 탐색용으로 광고를 내보내고, 이후 충분히 탐색이 되었다면 성과가 좋은 광고를 내보낸다고 이해하셔도 좋을 것 같습니다. 이렇게 만들어진 ad candidate를 기반으로 머신러닝 모델은 어떤 광고를 송출할지를 결정합니다.
2. 2. 2. Bidding Logic
일반적으로, 광고를 송출하는 입장에서는, 또는 매체의 입장에서는 CPM (기대 매출)을 최대화하는 DSP를 설계하기를 원합니다. CPM은 아래와 같이 클릭 당 단가와 (cost per click; CPC)와 클릭을 할 확률 (CTR)의 곱으로 계산됩니다.
\[CPM = CPC \times CTR\]여기서 CPC는 일반적으로 광고주와의 협의를 통해 정해지는 가격입니다. 따라서 머신러닝 모델의 입장에서는 고정값으로 취급할 수 있습니다. 특정 광고가 송출되어 클릭이 일어날 확률의 경우 사전에 알 수 없는 값입니다. CTR이 알 수 없는 값이기 때문에, 머신러닝 모델을 이용하여 pCTR을 추정하고, pCTR로 계산된 CPM을 사용하여 광고를 송출합니다.
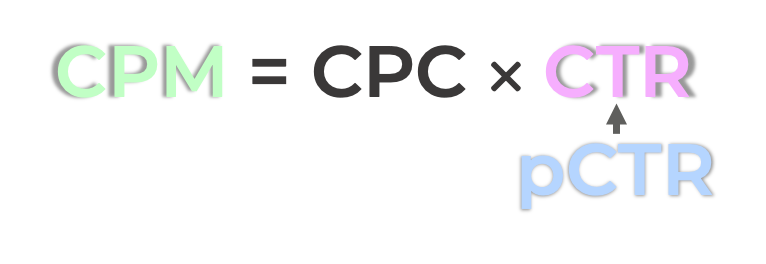
이렇게 송출된 광고는 다시 실험 환경의 원천 로그가 됩니다.

3. Conclusion
다시 한 번 전반적인 개인화 추천 시스템을 살펴보면 아래와 같습니다.
지금까지 프로그래머틱 애드 환경에서 기초적인 개인화 추천 시스템을 설계하는 방법을 살펴보았습니다. 본 포스팅이 개인화 추천 시스템에 대한 이해에 조금이라도 도움이 되기를 바랍니다.
긴 글 읽어주셔서 감사합니다.